先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里p7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加v获取:vip204888 (备注大数据)

正文
计算并判断下图例子:
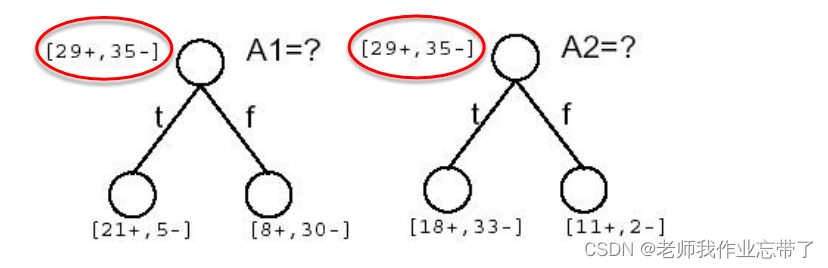
可以看到a1 a2都是29+,35-,接近一半一半,熵应该是接近于1的。
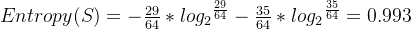
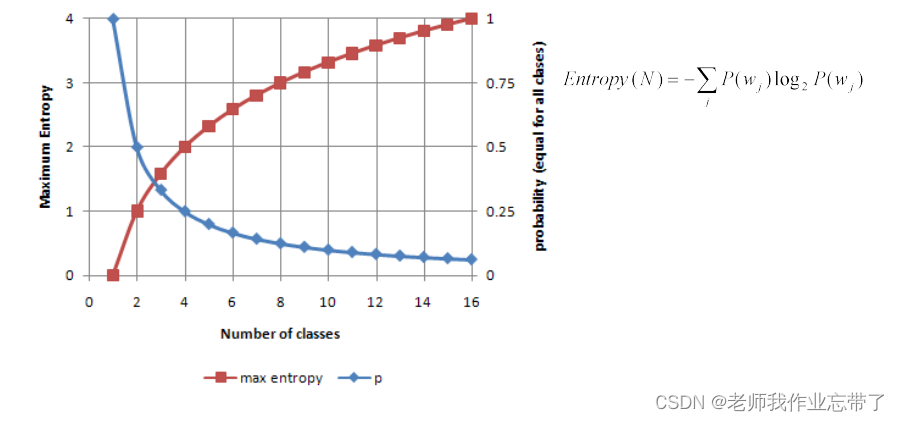
蓝线:1个类时概率为1,2个类时概率为0.5,16个类时概率为1/16
红线:1个类时最大熵为0,2个类时最大熵为1,无限增长。(其中最大时为均匀分布的)
2. gini 混杂度 ( duda 倾向于使用 gini 混杂度)
在经济学和社会学上人们用 基尼系数 来衡量一个国家发展的平衡与否。
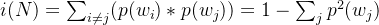
表示所有不相同情况的乘积(如果是a、b两种情况则p(a)*p(b),如果是a、b、c三种情况则p(a)*p(b)+p(a)*p©+p(b)*p©)
或者 1-相同情况的乘积 (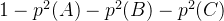 )
)
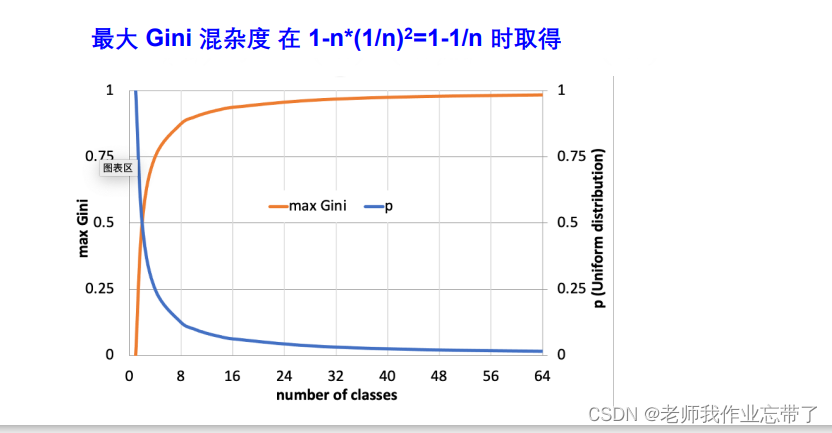
n = number of class(也是因为是均匀分布的,各部分都是1/n)
有了上限,上限为1.
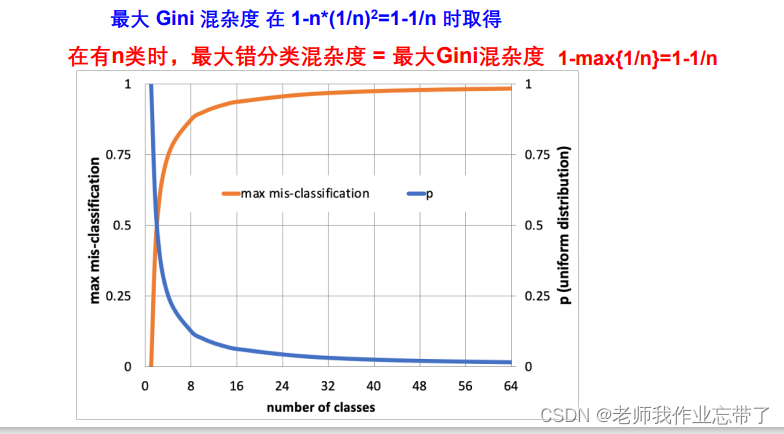
3. 错分类混杂度
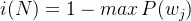
1-最大类的概率,即1-大多数进入的那个类(分对了,1-就是错的)
度量混杂度的变化–信息增益(ig)
由于对a的排序整理带来的熵的期望减少量
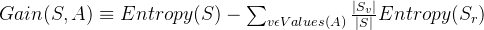
原始s的熵值-经过属性a分类以后的期望熵值
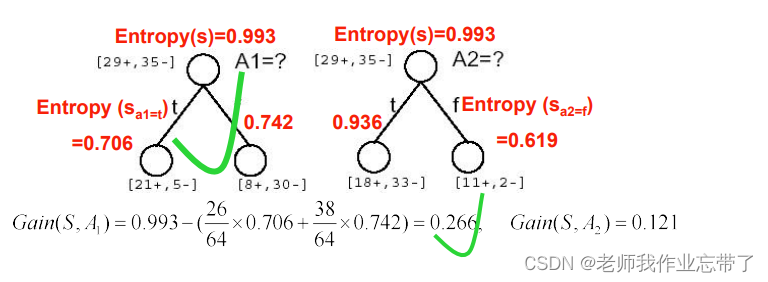 经计算,可见a1(湿度)的ig(信息增益)更大一些,也就意味着我们获得了更多的信息(减少的熵更多一些),我们选择a1作为根节点。
经计算,可见a1(湿度)的ig(信息增益)更大一些,也就意味着我们获得了更多的信息(减少的熵更多一些),我们选择a1作为根节点。
例:根据下表选择用哪个属性做根节点
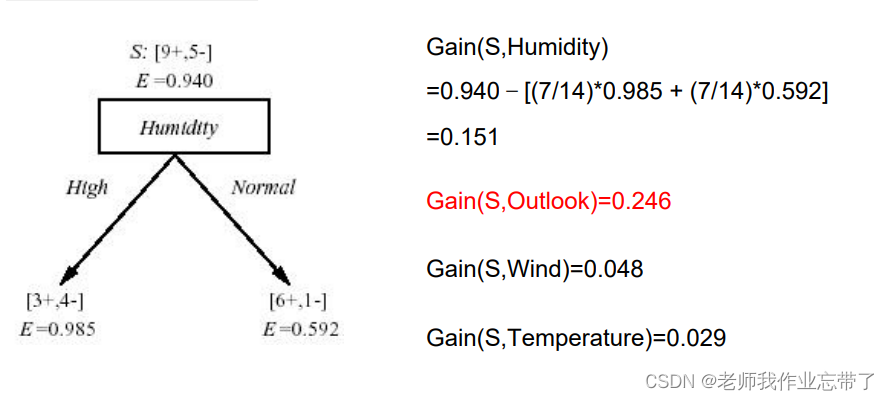
outlook的gain最大,选它作为根节点。
q2: 何时返回(停止分裂节点)?
“如果训练样本被完美分类”
• 情形 1: 如果当前子集中所有数据 有完全相同的输出类别,那么终止
• 情形 2: 如果当前子集中所有数据 有完全相同的输入特征,那么终止
比如:晴天-无风-湿度正常-温度合适,最后有的去了有的没去。此时即使不终止也没办法了,因为能用的信息已经用完了。这意味着:**1、数据有噪声noise。**需要进行清理,如果噪声过多说明数据质量不够好。2、漏掉了重要的feature,比如漏掉了当天是否有课,有课就没办法出去玩。
可能的情形3: 如果 所有属性分裂的信息增益为0, 那么终止 这是个好想法吗?(no)
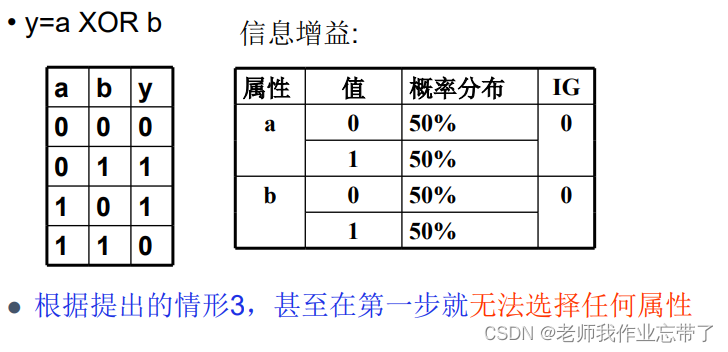
如上图此时树的第一个节点都找不出来(ig都是0),如果3说得对,那此时决策树都无法构建。
假如我们不要这个条件,反正都一样,ig都是0,多个最大值的时候随机选一个关系就被构建出来了(此时也完美分类了)
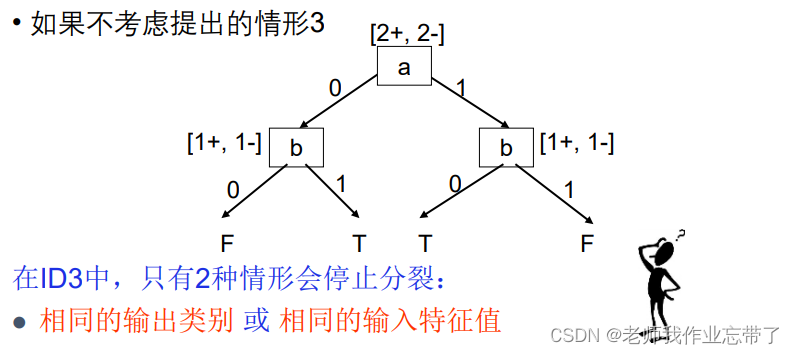
即在id3中只有上面两种情况会停止分裂,如果ig=0,则随机取一个就好。
id3算法搜索的假设空间
- 假设空间是完备的(即能处理属性的析取又能处理属性的合取)
目标函数一定在假设空间里
- 输出单个假设(沿着树的一条路走下去)
不超过20个问题(根据经验,一般feature不超过20个,过于复杂树比较长也容易产生过拟合)
- 没有回溯(以a1做根节点,没办法退回去看a2做根节点怎么样)
局部最优
- 在每一步中使用子集的所有数据(比如梯度下降算法里权值的更新策略是每条数据更新一次的话,那就是每次只使用一条数据)
数据驱动的搜索选择
对噪声数据有鲁棒性
id3中的归纳偏置(inductive bias)
- 假设空间 h 是作用在样本集合 x 上的
没有对假设空间作限制
- 偏向于在靠近根节点处的属性具有更大信息增益的树
尝试找到最短的树
该算法的偏置在于对某些假设具有一些偏好 (搜索偏置), 而不是对假设空间 h 做限制(描述偏置).
奥卡姆剃刀(occam’s razor)*:偏向于符合数据的最短的假设
cart (分类和回归树)
一个通用的框架:
- 根据训练数据构建一棵决策树
- 决策树会逐渐把训练集合分成越来越小的子集
- 当子集纯净后不再分裂
- 或者接受一个不完美的决策
许多决策树算法都在这个框架下,包括id3、c4.5等等。
三、过拟合问题
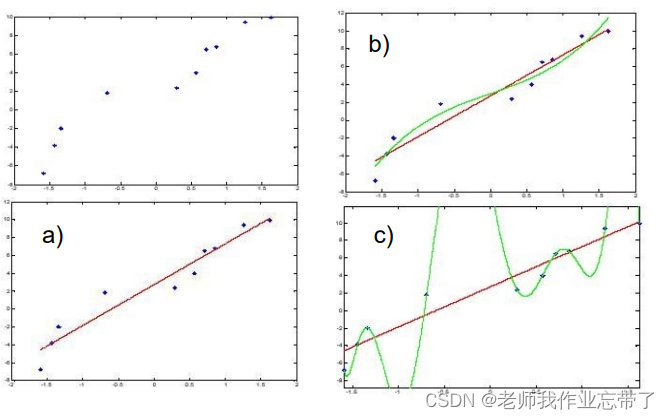
如上图,b比a更好,但如果像c一样每个点都被完美拟合了,错误率为0,但是如果有一个新的点:
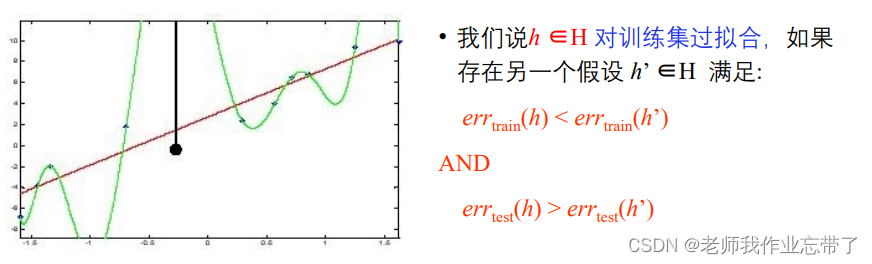
此时c的算法的误差就太大了,过于匹配训练数据了,使得它在测试的更多未见实例上的泛化能力下降了。
决策树过拟合的一个极端例子:
- 每个叶节点都对应单个训练样本 —— 每个训练样本都被完美地分类
- 整个树相当于仅仅是一个数据查表算法的简单实现
即此时的树就是一个数据查表,可以类比数据结构里哈希表。这意味着查找时只能查找表里有的数据,对于没有的数据查不到,没什么泛化能力。
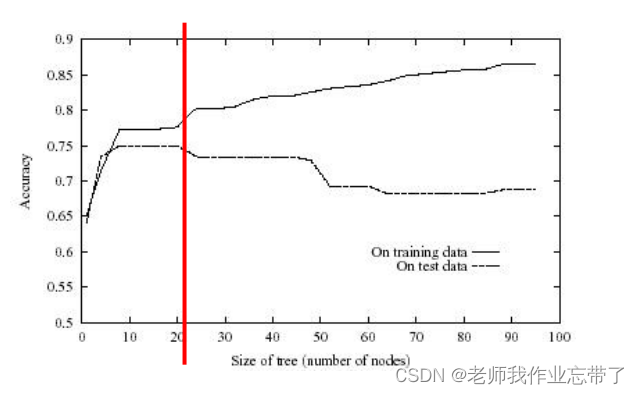
四、如何避免过拟合
对决策树来说有两种方法避免过拟合
- 当数据的分裂在统计意义上并不显著(如样例少)时,就停止增长:预剪枝
- 构建一棵完全树,然后再做后剪枝
在实际应用中,一般预剪枝更快, 而后剪枝得到的树准确率更高。
对于预剪枝
预剪枝: 基于样本数
比如有100个数据,到当前节点只有5个数据了,就不继续向下分了,无论几个正几个负,说明分的过细了。
预剪枝: 基于信息增益的阈值
选ig大的为节点,如果ig最大的还是有点小了,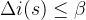 则停止。
则停止。
对于后剪枝:
后剪枝: 错误降低剪枝
剪枝后新的叶节点的标签赋值策略
错误降低剪枝的效果
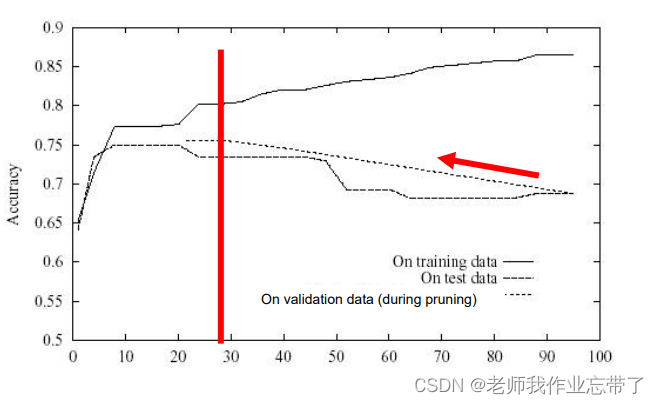
从后到前,在验证集上一点点减枝。
后剪枝: 规则后剪枝
为什么在剪枝前将决策树转化为规则?
五、扩展: 现实场景中的决策树学习
1. 连续属性值

• 建立一些离散属性值,区间化,便于建立分支
• 可选的策略:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加v获取:vip204888 (备注大数据)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
五、扩展: 现实场景中的决策树学习
1. 连续属性值
• 建立一些离散属性值,区间化,便于建立分支
• 可选的策略:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加v获取:vip204888 (备注大数据)
[外链图片转存中…(img-mvo2662u-1713271822046)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

发表评论