yolo-v5 训练自己的分类模型
1、获取官方源码
2、测试官方源码
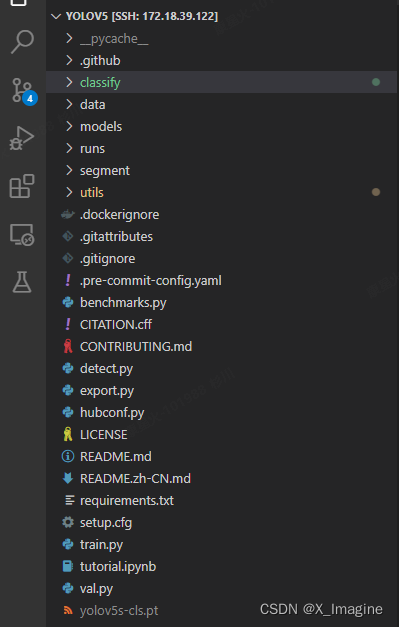
下图是官方的代码结构(v7.0),文件夹【classify】存放分类的相关代码,包括训练代码 train.py,预测代码 predict.py,评估代码 val.py,
2.1、公开数据集测试源码
按照上述代码结构,进入【classify】文件夹,打开训练脚本【train.py】。根据训练脚本最上面的注释内容:可以使用官方数据集,也可以使用自己的数据集,以及单卡和多卡的训练命令,

官方训练命令如下,
python classify/train.py --model yolov5s-cls.pt --data cifar10 --epochs 5 --img 224
运行上述命令,会【自动下载】所需的数据集【cifar10】和模型文件【yolov5s-cls.pt】。下载完成后,数据的存放结构如下图所示,包含测试集【test】和训练集【train】。注意,参考官方的数据存放结构,后续存放自己的数据集

如下图所示,每一个文件夹内,存放一个类别的图片

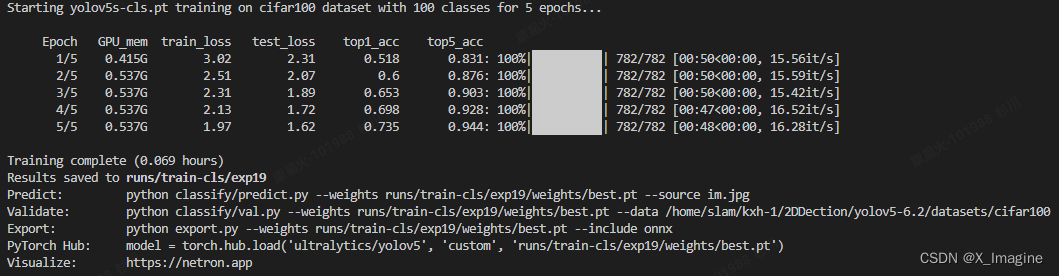
训练过程如下,训练基本正常,
3、源码模块解析
3.1、数据读取
-
训练类别数量:数据路径【data_dir/train】下的文件夹数量等同于训练的类别数量(存放数据时应该注意),具体代码如下:
nc = len([x for x in (data_dir / 'train').glob('*') if x.is_dir()]) # number of classes -
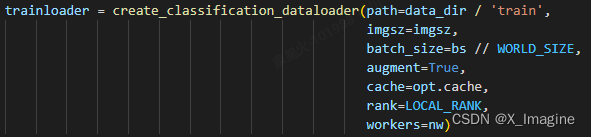
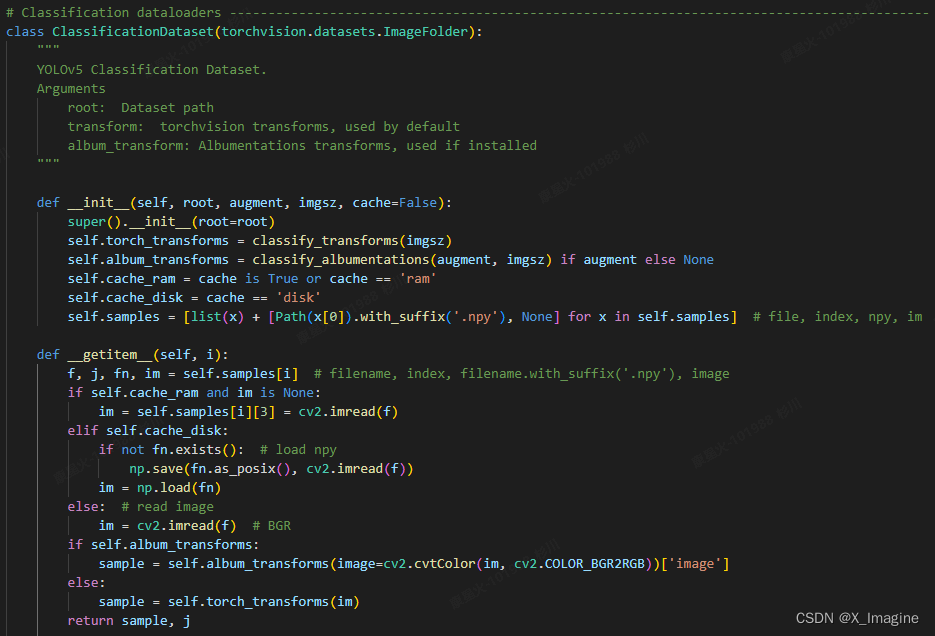
数据读取

3.2、网络结构
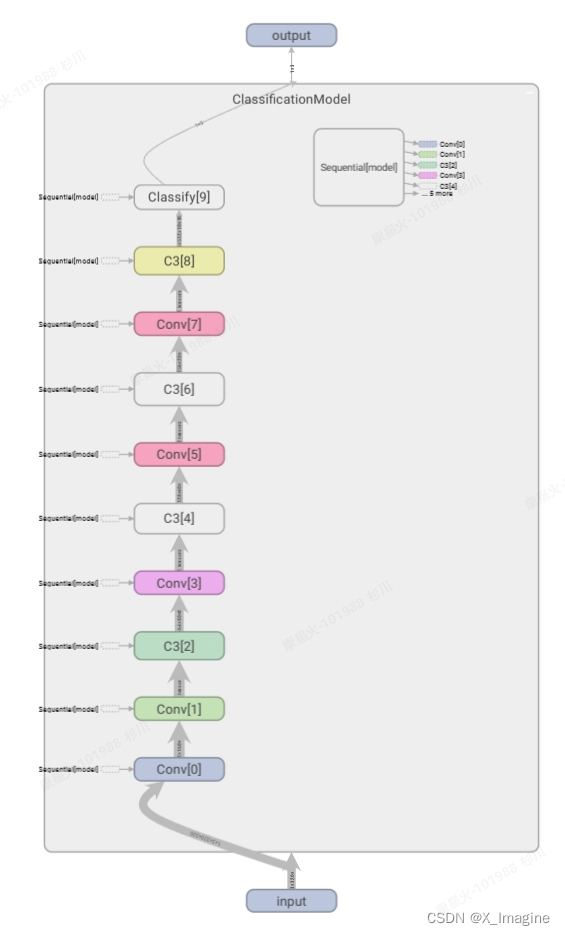
分类网络【yolov5-cls 】的网络结构如下图所示,只用了目标检测网络的主干部分。基础模块包括:c3,cbs,其详细的结构,可以参考之前写的博文,yolo-v5 系列算法和代码解析(四)—— 网络结构
4、快速开始训练自己的数据
按照在官方数据集上的测试过程,要想快速开始训练,只要两方面的准备:(1)准备好自己的数据集;(2)配置部分训练参数。具体的过程在以下章节陈述
4.1、准备自己的数据
根据【2.1】节的陈述,依据官方数据的组织结构来存放自己的数据集,每一个文件夹放一个类别的图片。【mono_demo】就是存放自己的训练数据的根目录名称,也是训练时传入的数据标志。存放的结构如下图所示,

4.2、配置训练参数
为了训练自己的数据集,首先保证官方代码能够在自己的数据集上正常训练,并且达到基本的训练效果即可(判断标志就是网络能够正常收敛),之后再进行网络调优。所以,这一章节的目的是让官方源码在自己的数据集上快速开始训练,并且能够得到基本的训练效果。为此,修改训练脚本(train.py)的部分训练参数,具体如下,
-
模型选择,默认是
yolov5-cls.pt,也可以是efficient-b0,b1,b2,b3,resnet18,parser.add_argument('--model', type=str, default='yolov5s-cls.pt', help='initial weights path') -
修改训练数据路径
parser.add_argument('--data', type=str, default='mono_demo', help='cifar10, cifar100, mnist, imagenet, etc.') -
根据自己的需要,修改如下参数
parser.add_argument('--epochs', type=int, default=10) parser.add_argument('--batch-size', type=int, default=64, help='total batch size for all gpus') parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='train, val image size (pixels)') -
根据是否需要预训练,修改参数
parser.add_argument('--pretrained', nargs='?', const=true, default=true, help='start from i.e. --pretrained false')
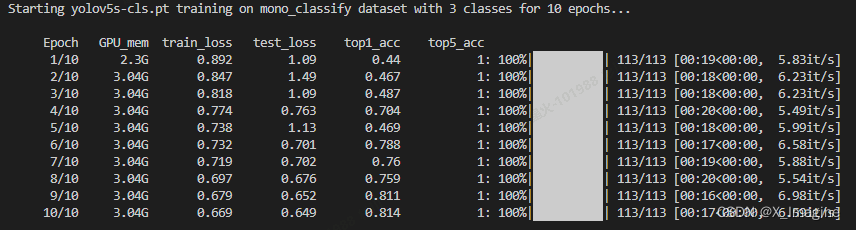
配置完参数后,开启训练,过程如下,从精度来看,基本正常,达到最基本的效果,
4.3、模型推理和评估
训练完成模型后,通常要经常进行推理和评估,根据结果评估模型,并且作为后续优化的参考
模型预测:
python classify/predict.py --weights runs/train-cls/exp24/weights/best.pt --source im.jpg
模型评估:
python classify/val.py --weights runs/train-cls/exp24/weights/best.pt --data datasets/biaozhu_train_1
训练可视化:
tensorboard --logdir=runs/train-cls/exp34



发表评论