一、hive产生背景
传统hadoop架构存在的一些问题
mapreduce编程必须掌握java,门槛较高
传统数据库开发、dba、运维人员学习门槛高
hdfs上没有schema的概念,仅仅是一个纯文本文件
hive的产生
为了让用户从一个现有数据基础架构转移到hadoop上
现有数据基础架构大多基于关系型数据库和sql查询
facebook诞生了hive
二、hive是什么
它是基于hadoop的数据仓库工具
方便的将结构化数据文件映射为一张数据库表
提供sql查询功能,sql语句底层转换为mr作业执行
hive提供了一系列功能可以方便进行数据etl
hive目前是apache基金会的顶级项目
hive作为数据仓库工具,非常适合数据仓库联机分析处理(olap)
对于etl的解释
etl是指“extract, transform, load”的缩写,是数据仓库中常见的一种数据处理过程。在etl过程中,数据从一个或多个来源(extract)抽取出来,经过清洗、转换和整合等处理(transform),最终加载(load)到目标数据库或数据仓库中。
具体来说,etl过程通常包括以下几个步骤:
1. extract(抽取):从一个或多个数据源中抽取数据。这些数据源可以是数据库、文件、api接口等。在这个阶段,数据会被提取出来,准备进行后续的处理。
2. transform(转换):在数据抽取之后,数据会经过各种转换操作,以满足目标系统的需求。转换可能包括数据清洗、数据格式转换、数据合并、数据计算等操作。目的是将原始数据转换为目标数据模型的格式。
3. load(加载):经过转换处理后的数据会被加载到目标数据库或数据仓库中。这个过程包括将数据写入目标系统的表格或数据结构中,以供后续分析和查询使用。etl过程在数据仓库和商业智能系统中起着至关重要的作用,帮助组织将分散的、杂乱的数据整合、清洗并转化为有用的信息。通过etl过程,组织可以实现数据的一致性、准确性和可靠性,从而支持数据分析、报告和决策制定等业务需求。
三、hive在hadoop生态系统中的位置
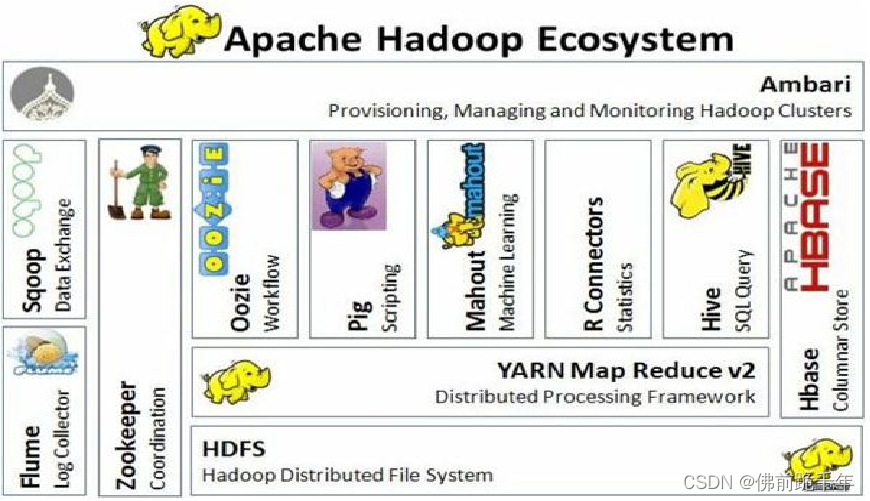
在hadoop生态系统中,hive是一种数据仓库工具,它提供了类似于sql的查询语言(hiveql)来查询和分析存储在hadoop集群中的大规模数据。hive通常被用作数据仓库,用于结构化数据的存储和查询。
hive的位置可以理解为在hadoop生态系统中处于数据处理和查询层的位置。在hadoop生态系统中,hive通常与以下组件和工具一起使用:
1. hadoop distributed file system (hdfs):hdfs是hadoop的分布式文件系统,用于存储大规模数据。hive通常可以直接查询和分析存储在hdfs上的数据。
2. mapreduce:mapreduce是hadoop的一种计算框架,用于处理大规模数据的并行计算。hive可以通过mapreduce来执行查询和数据处理操作。
3. yarn:yarn是hadoop的资源管理器,用于集群资源的管理和作业调度。hive作业可以由yarn进行资源分配和调度。
4. hive metastore:hive metastore是hive的元数据存储,用于存储表结构、分区信息等元数据。通常,hive metastore会使用关系数据库(如mysql)来存储元数据信息。
总的来说,hive在hadoop生态系统中的位置是作为一个用于数据仓库、数据查询和分析的工具,它通过hiveql语言将sql查询转换为mapreduce任务或tez任务,从而实现对hadoop集群中大规模数据的查询和分析。
四、hive与传统关系型数据库的异同
| hive | rdbms | |
| 查询语言 | hql | sql |
| 数据存储 | hdfs | 块设备、本地文件系统 |
| 执行 | mapreduce | executor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 事务 | 0.14版本后加入 | 支持 |
| 索引 | 0.8版本后加入 | 有复制的索引 |
| 数据更新 | 不支持 | 支持 |
五、hive的特点及优势
hive支持运行在不同的计算框架上:mapreduce、tez、spark、flink等。
hive与sql有着相似的语法,大大提高开发效率
hive支持hdfs与hbase上的ad-hoc(点对点模式)
hive支持用户自定义函数、脚本等
hive设计特点:
- hive不支持对数据的改写和添加,所有数据都是在加载的时候确定的
- 支持索引,加快数据查询
- 不同的存储类型,例如:文本文件、序列化文件
- 将元数据保存在关系数据库中,减少了在查询中执行语义检查时间
- 可以直接使用存储在hadoop文件系统中的数据
- 类sql的查询方式,将sql查询转换为mapreduce的job在hadoop集群上执行
- 编码跟hadoop同样使用utf-8字符集
在生产环境中,hive有如下优势
- 可扩展,hive可以自由扩展集群规模,拓展功能方便
- 延展性,hive支持自定义函数,用户可根据需求自定义
- 容错性,良好的容错性
解决了传统关系数据库在大数据处理上的瓶颈;适合大数据的批量处理。
充分利用集群的cpu计算资源、存储资源,实现并行计算。
hive支持标准sql语法,免去了编写mr程序的过程,减少了并发成本。
六、hive的框架设计
hive的架构设计包括三个部分:
hive client
hive客户发,可通过java、python等语言连接hive并进行与rdbms类似的sql查询操作
hive service
hive服务端,客户端必须通过服务端与hive交互,主要包括cli、hiveserver、hivewebinterface等组件
hive storage and computing
包含hive的数据存储与计算的内容,hive元数据存储在rdbms中,数据存储在hdfs中,计算由mr完成
hive框架图:
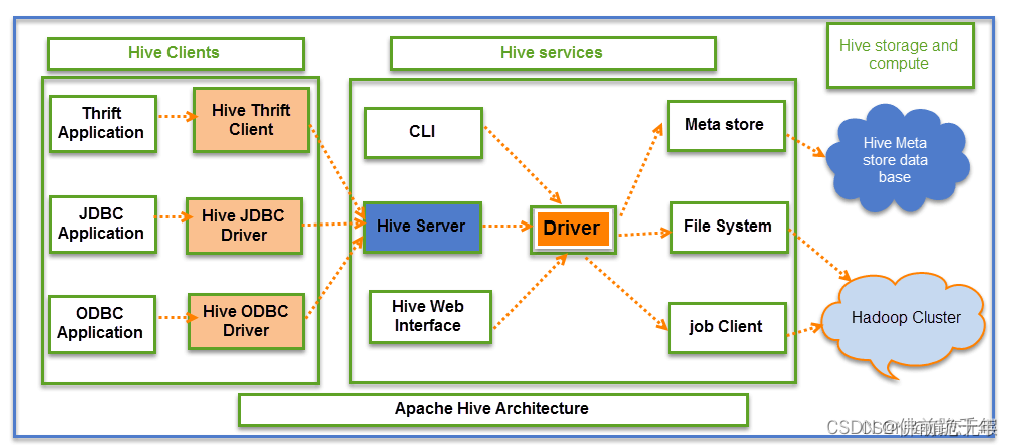
hive架构主要包括:
cli、hiveserver2、hwi、driver、metastore
hive数据存储模型与rdbms类似,分区和分桶是hive为提升查询性能而特有的概念
hive元数据释对真实数据的描述,通常单独存储在mysql中
hive除了两种命令行开发工具(cli和beeline)之外还有许多第三方工具(hue、ambari、zeppelin)
hive的工作流程图:
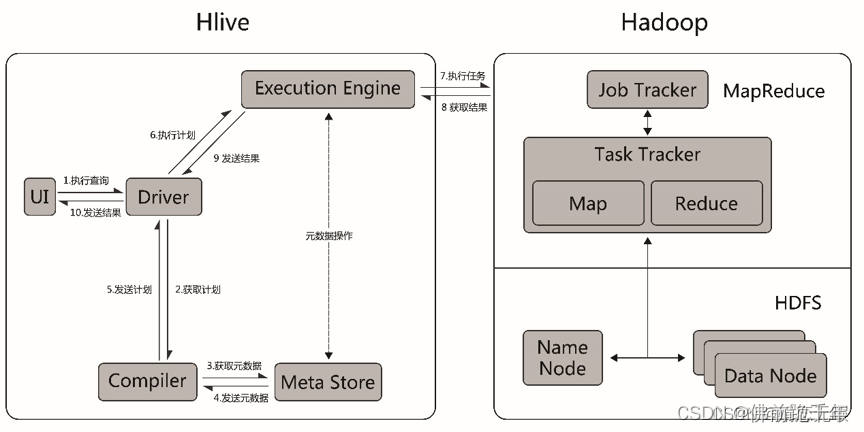

七、hive的适用场景
hive的劣势
hive的hql表达能力有限:有些复杂运算用hql不易表达;效率低:hive自动生成mr作业,通常不够智能。
业务场景
- 适用于非结构化数据的离线分析统计
- hive的优势在于处理大数据,对处理小数据没有优势
不适用场景
- 复杂的机器学习算法
- 复杂的科学计算
- 联机交互式实时查询
场景技术特点
- 为超大数据集设计的计算、扩展能力
- 支持sql like查询语言
- 多表的join操作
- 支持非结构化数据的查询、计算
- 提供对数据存取的编程接口,支持jdbc、odbc
八、hive 的存储格式
hive中的数据
有真实数据与元数据之分,元数据是表示真实数据与hive表的映射关系
hive真实数据的存储格式
- textfile,文本文件格式
- sequencefile,二进制序列化过的文本存储文件格式
- rcfile,面向列的数据存储格式
- orcfile,对rcfile的优化格式
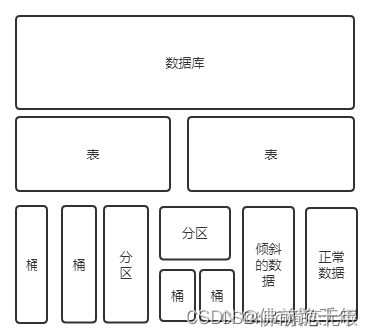
存储模型
hive数据在hdfs的典型存储结构表现
/数据仓库地址/数据库名/表名/数据文件(或分桶文件)
/数据仓库地址/数据库名/表名/分区键/数据文件(或分桶文件)
hive数据存储模型图:
九、hive数据单元介绍
database:数据库,在hdfs中为hive.metastore.warehouse.dir目录下的一个文件夹。
tables:表,表由列构成,在表上可以进行过滤、映射、连接和联合操作,在hdfs中为数据库目录下的子目录。
hive表分为内部表和外部表:内部表类似于rdbms中的表,由hive管理 外部表指向已经存在hdfs中的数据,外部表的真实数据不被hive管理。
partitions 分区,每个表都可以按指定的键分为多个分区,作用是为了提高查询的效率,在hdfs中是表目录的子目录。
buckets 分桶,根据表中某一列的哈希值将数据分为多个桶,在hdfs最终为同一目录下根据哈希散列后的多个文件。



发表评论