什么是yarn?
yarn(yet another resource negotiator)是apache hadoop生态系统中的一个重要组件,用于资源管理和作业调度。它是hadoop 2.x版本中的一个关键特性,取代了旧版本中的jobtracker和tasktracker。yarn的设计目标是使hadoop能够处理更广泛的工作负载,包括批处理、交互式查询、流处理以及其他类型的工作负载。
为什么需要yarn?
yarn的引入解决了hadoop 1.x版本中存在的一些限制和不足,提供了更灵活、更高效的资源管理和作业调度。以下是一些需要yarn的主要原因:
- 多样化的工作负载支持:
-hadoop 1.x版本中的mapreduce框架适用于批处理作业,但不太适合处理交互式查询、流处理等多样化的工作负载。yarn的出现使得hadoop可以同时运行多种类型的应用程序,包括批处理、交互式查询(如apache hive、apache tez)、流处理(如apache storm、apache flink)等。 - 资源隔离和多租户支持:
yarn支持在同一集群上运行多个应用程序,并能够对资源进行有效的隔离,防止一个应用程序的资源消耗影响其他应用程序的性能。这种多租户支持使得企业可以更高效地共享集群资源,并在不同的团队、部门或业务单位之间进行资源划分和管理。 - 动态资源分配: yarn允许应用程序根据需要动态申请和释放资源,而不是像hadoop 1.x版本那样静态地将资源分配给作业。这种动态资源分配机制可以提高集群资源的利用率,并更好地适应不同作业的资源需求变化。
- 支持更大规模的集群:
yarn的架构设计更适合处理大规模集群,能够有效地管理数千甚至数万个节点的资源和作业。这使得hadoop可以在更大规模的数据集上进行处理和分析,满足日益增长的数据处理需求。 - 更灵活的作业调度:
yarn提供了灵活的作业调度框架,可以支持多种调度策略和调度器插件。这使得用户可以根据自己的需求选择最适合的调度器,并对调度策略进行定制,以满足不同作业的性能和资源需求。
yarn的基本核心思想
yarn的基本核心思想是将资源管理和作业调度从特定的计算框架(如mapreduce)中分离出来使其成为单独的守护进程,使得hadoop集群能够更通用地支持多种类型的应用程序和工作负载。
这个想法是拥有一个全局的 resourcemanager ( rm ) 和每个应用程序的 applicationmaster ( am )。应用程序可以是单个作业,也可以是作业的 dag。resourcemanager 和 nodemanager 构成了数据计算框架。 resourcemanager是系统中所有应用程序之间资源仲裁的最终权威。 nodemanager 是每台机器的框架代理,负责容器、监视其资源使用情况(cpu、内存、磁盘、网络)并将其报告给resourcemanager/scheduler。每个应用程序的 applicationmaster 实际上是一个特定于框架的库,其任务是与 resourcemanager 协商资源并与 nodemanager 一起执行和监视任务。

在hadoop集群中,yarn主要有以下几个核心组件:
- resourcemanager(资源管理器):resourcemanager是yarn集群中的主节点,负责管理整个集群的资源分配和作业调度。它跟踪可用资源,并为提交到集群的应用程序分配资源。
- nodemanager(节点管理器):nodemanager运行在每个集群节点上,负责管理该节点上的资源,并与resourcemanager通信以报告节点的资源使用情况和可用性。
- applicationmaster(应用程序管理器):每个提交到yarn集群的应用程序都有一个对应的applicationmaster。applicationmaster负责与resourcemanager协商资源、监控作业进度,并向resourcemanager请求更多资源或报告作业完成情况。
resourcemanager 有两个主要组件:scheduler 和applicationsmanager。
调度程序负责将资源分配给受熟悉的容量、队列等约束的各种正在运行的应用程序。调度程序是纯粹的调度程序,因为它不执行应用程序状态的监视或跟踪。此外,它不保证重新启动由于应用程序故障或硬件故障而失败的任务。 scheduler根据应用程序的资源需求执行其调度功能;它是基于资源容器的抽象概念来实现的,资源容器包含内存、cpu、磁盘、网络等元素。
调度程序具有可插入策略,负责在各种队列、应用程序等之间划分集群资源。当前的调度程序(例如capacityscheduler和fairscheduler)就是插件的一些示例。
applicationsmanager 负责接受作业提交、协商第一个容器来执行应用程序特定的 applicationmaster 并提供在失败时重新启动 applicationmaster 容器的服务。每个应用程序的 applicationmaster 负责与 scheduler 协商适当的资源容器,跟踪其状态并监控进度。
hadoop-2.x 中的 mapreduce 保持了与之前稳定版本 (hadoop-1.x) 的api 兼容性。这意味着所有 mapreduce 作业仍应在 yarn 之上运行,只需重新编译即可。
yarn通过reservationsystem支持资源预留的概念,reservationsystem 是一个组件,允许用户指定随时间和时间限制(例如截止日期)的资源配置文件,并预留资源以确保重要作业的可预测执行。reservationsystem跟踪资源随着时间的推移,对预留进行准入控制,并动态指示底层调度程序以确保预留得到满足。
为了将 yarn 扩展至数千个节点以上,yarn通过yarn federation功能支持联合概念。联合允许透明地将多个纱线(子)集群连接在一起,并使它们显示为单个大型集群。这可用于实现更大的规模,和/或允许多个独立集群一起用于非常大的作业,或用于具有跨所有集群的容量的租户。
在 yarn 上运行的应用程序
- 批处理应用程序:
批处理作业是hadoop最常见的用例之一,它们通常涉及对大规模数据集进行分析和处理。使用yarn,批处理作业可以通过mapreduce框架或其他批处理引擎(如apache spark、apache flink等)来运行。 - 交互式查询:
交互式查询通常用于对数据进行即席查询和分析。通过yarn,可以在集群上运行诸如apache hive、apache impala、apache drill等交互式查询引擎,这些引擎能够实时响应用户的查询请求。 - 流处理应用程序:
流处理应用程序用于对实时数据流进行处理和分析。通过yarn,可以在集群上运行流处理引擎,如apache storm、apache flink、apache kafka streams等,以实时处理数据流并生成相应的输出。 - 机器学习和数据挖掘:
yarn也可以支持运行机器学习和数据挖掘算法。例如,可以使用apache spark的机器学习库(mllib)或apache flink的机器学习库来在集群上训练和部署机器学习模型。 - 图计算:
图计算应用程序用于在图结构数据上执行复杂的分析和计算。通过yarn,可以在集群上运行图计算引擎,如apache giraph、apache spark graphx等,来处理大规模的图数据。 - 其他类型的应用程序:
此外,yarn还可以支持各种其他类型的应用程序,包括etl(extract-transform-load)作业、数据流处理、实时分析等。yarn的通用性和灵活性使得它能够满足不同类型应用程序的运行需求。
应用程序如何在 yarn 上运行?
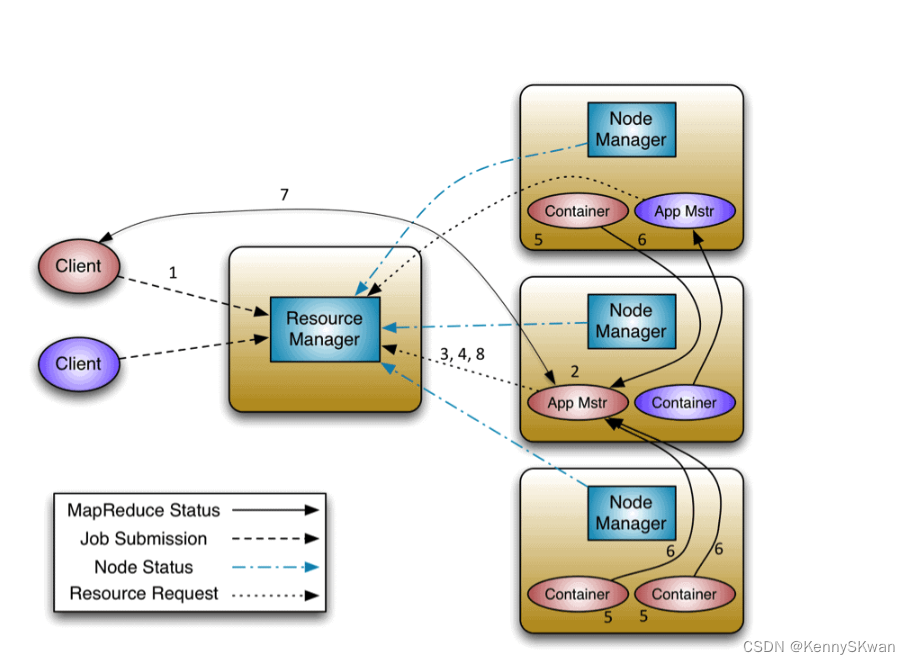
- 应用程序提交:
用户通过yarn客户端提交应用程序。在提交过程中,用户需要指定应用程序的资源需求、启动命令、应用程序类型等信息。通常,应用程序的启动命令会包括指定应用程序的jar包或可执行文件、主类名(对于java应用程序)、应用程序的输入和输出路径等信息。 - resourcemanager分配资源:
resourcemanager接收到用户提交的应用程序后,会根据应用程序的资源需求和集群中的资源情况进行资源分配。resourcemanager会为应用程序分配所需的计算资源(如cpu和内存资源)以及其他必要的资源(如网络带宽)。 - nodemanager启动容器:
一旦资源分配完成,resourcemanager会通知集群中相应的nodemanager,在相应的节点上启动一个或多个容器(container)。容器是yarn中的基本执行单位,它包含了运行应用程序所需的计算资源、环境变量等信息。 - 应用程序启动:
一旦容器启动完成,应用程序的启动命令将被执行。这可能涉及启动应用程序的主进程,例如执行java的main()方法或运行可执行文件。 - applicationmaster启动:
应用程序的启动过程通常会涉及到一个特殊的组件,称为applicationmaster。applicationmaster负责与resourcemanager通信,协商资源、监控作业进度,并向resourcemanager请求更多资源或报告作业完成情况。applicationmaster运行在集群中的一个容器中,并由resourcemanager负责启动和监控。 - 作业执行:一旦applicationmaster启动,应用程序就可以开始在容器中执行。根据应用程序的类型和逻辑,它可能会涉及到数据的读取、处理、计算以及生成结果等过程。
- 作业完成:
一旦应用程序执行完成,applicationmaster会向resourcemanager报告作业完成情况,并请求释放所占用的资源。 - 资源释放
resourcemanager会相应地释放容器所占用的资源,并通知nodemanager停止相应的容器。至此,应用程序的执行过程结束,集群资源被释放,可以被其他应用程序使用。


发表评论