apache hbase™是一个分布式、可扩展、大数据存储的hadoop数据库。
当我们需要对大数据进行随机、实时的读/写访问时,可以使用hbase。这个项目的目标是在通用硬件集群上托管非常大的表——数十亿行x数百万列。apache hbase是一个开源、分布式、版本化的非关系数据库,模仿了chang等人的谷歌bigtable:a distributed storage system for structured data。正如bigtable利用谷歌文件系统提供的分布式数据存储一样,apache hbase在hadoop和hdfs之上提供了类似bigtable的功能。
hbase的部署模式包括:
-
独立模式:hbase不使用hdfs,而是使用本地文件系统代替它在同一个jvm上运行所有hbase守护进程和本地zookeeper。
-
分布模式
- 伪分布式:所有守护进程都运行在单个节点上。
- 完全分布式:守护进程分布在集群中的所有节点上。
本文部署hbase集群的时候,需要依赖于hadoop集群和zookeeper集群。
一、准备工作
-
虚拟机相关:
-
vmware workstation 16:虚拟机 > vmware_177981.zip
-
centos stream 9:虚拟机 > centos-stream-9-latest-x86_64-dvd1.iso
-
-
jdk
jdk1.8:jdk > jdk-8u261-linux-x64.tar.gz -
hadoop
hadoop 3.3.6:hadoop > hadoop 3.3.6.tar.gz
-
zookeeper
zookeeper > apache-zookeeper-3.8.4-bin.tar.gz
-
hbase
hbase > hbase-2.5.8-bin.tar.gz
-
辅助工具
mobaxterm:mobaxterm_portable_v24.0.zip
本文相关资源可以在文末提供的百度网盘资源中下载,除了vmware(你懂的…),以上资源均来源于官网,mobaxterm是便捷式软件,无需安装。
1. hadoop安装
参考: 搭建hadoop3.x完全分布式集群(centos 9)
2. zookeeper安装
参考:搭建zookeeper完全分布式集群(centos 9 )
3. 时钟同步
在hbase集群中,各个节点之间的时间同步非常重要,如果各个节点的时间不一致,那么会出现写入数据的时间戳不一致或某些操作的顺序发生错误等问题,从而影响hbase集群的稳定性和正确性。因此,在部署hbase之前,需要为集群的各节点配置时间同步。
1)安装chrony
在虚拟机hadoop1上运行如下命令安装时间同步工具chrony。
yum install chrony –y
ssh hadoop2 "yum install chrony -y"
ssh hadoop3 "yum install chrony -y"
2)启动chrony服务
在虚拟机hadoop1上运行如下命令启动时间同步工具chrony的服务。
systemctl start chronyd
ssh hadoop2 "systemctl start chronyd"
ssh hadoop3 "systemctl start chronyd"
3)查看chrony服务运行状态
在虚拟机hadoop1、 hadoop2和hadoop3查看chrony服务的运行状态。
systemctl status chronyd
4)配置chrony服务端
在虚拟机hadoop1执行vi /etc/chrony.conf命令编辑chrony的配置文件chrony.conf,将chrony默认使用的时钟源指定为中国国家授时中心,并且允许处于任意网段的chrony客户端可以通过虚拟机hadoop1的chrony服务端进行时间同步。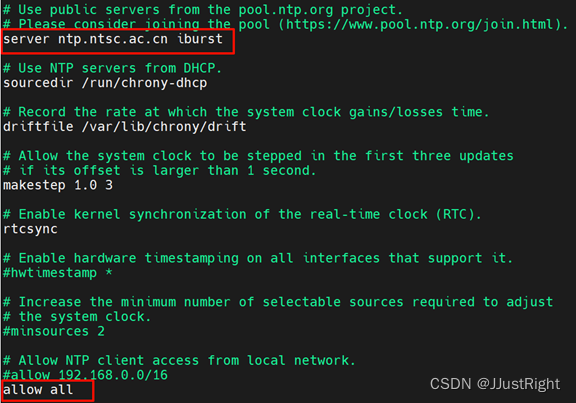
5)配置chrony客户端
分别在虚拟机hadoop2和虚拟机hadoop3执行vi /etc/chrony.conf命令编辑chrony的配置文件chrony.conf,指定chrony客户端进行时间同步的chrony服务端。

6)重新启动chrony服务
在虚拟机hadoop1上运行如下命令重新启动时间同步工具chrony的服务。
systemctl restart chronyd
ssh hadoop2 "systemctl restart chronyd"
ssh hadoop3 "systemctl restart chronyd"
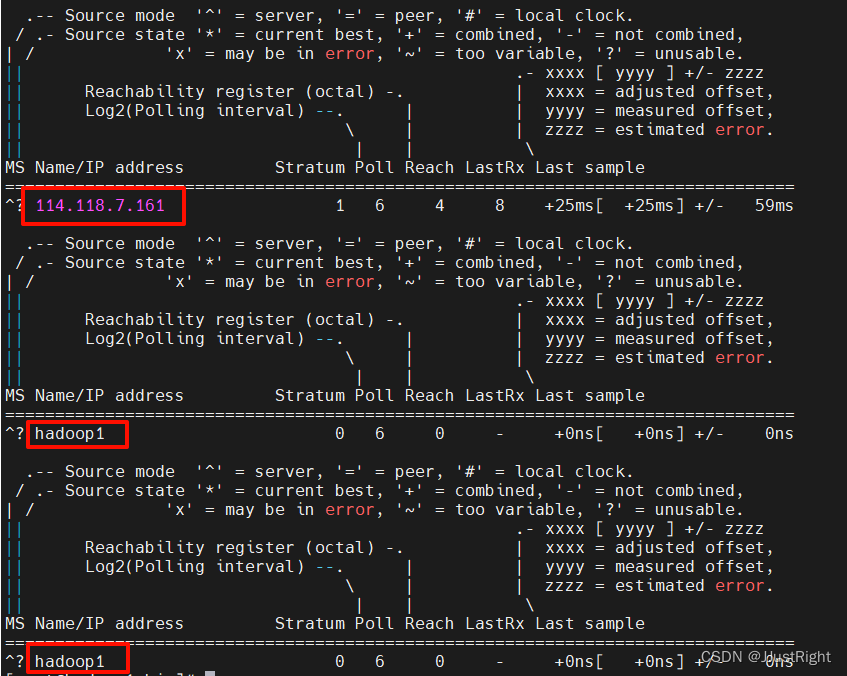
7)查看时钟源
在虚拟机hadoop1上运行如下命令查看chrony服务端和客户端的时钟源。
chronyc sources -v
ssh hadoop2 "chronyc sources -v"
ssh hadoop3 "chronyc sources -v"
二、安装hbase
1. 上传安装包
将hbase-2.5.8-bin.tar.gz上传到hadoop1的/software目录。
2. 安装hbase
以解压方式安装hbase,将hbase安装到/opt目录。
tar -zxvf /software/hbase-2.5.8-bin.tar.gz -c /opt
3. 配置hbase系统环境变量
在虚拟机hadoop1执行vi /etc/profile命令编辑系统环境变量文件profile,在该文件的底部添加如下内容。
export hbase_home=/opt/hbase-2.5.8
export path=$path:$hbase_home/bin
执行source /etc/profile命令初始化系统环境变量使添加的hbase系统环境变量生效。
三、配置hbase
| 虚拟机 | hmaster | hregionserver |
|---|---|---|
| hadoop1 | √ | |
| hadoop2 | √ | |
| hadoop3 | √ |
1. 配置文件介绍
所有配置文件都位于 conf 目录中,需要保持集群中每个节点同步。
-
backup-masters
默认情况下不存在。文件中添加运行备用hmaster进程的虚拟机主机名或ip。
-
hadoop-metrics2-hbase.properties
用于连接hbase hadoop的metrics2框架
-
hbase-env.cmd和hbase-env.sh
用于windows和linux/unix环境的脚本来设置hbase的工作环境,包括java、java选项和其他环境变量的位置。
-
h base-policy.xml
它是一个rpc服务器使用的默认策略配置文件,根据文件配置内容对客户端请求进行授权决策。仅在启用hbase安全性时使用。
-
hbase-site.xml
该文件指定覆盖hbase默认的配置选项。
配置项 说明 hbase.tmp.dir 本地文件系统的临时目录,默认目录在 /tmp目录下,该目录会在系统重启后清空,所以需要注意该参数的值
默认值为: j a v a . i o . t m p d i r / h b a s e − {java.io.tmpdir}/hbase- java.io.tmpdir/hbase−{user.name}hbase.rootdir regionservers使用的目录,指定了hbase的数据存放目录,该路径需要完全限定(full-qualified),比如需要指定一个9000端口的hdfs文件系统下的/hbase目录,应写成:hdfs://namenode.example.org:9000/hbase
默认值:${hbase.tmp.dir}/hbasehbase.cluster.distributed 是否分布式
默认值:falsehbase.zookeeper.quorum 用逗号分隔的zookeeper集群中的服务器列表 hbase.zookeeper.property.datadir 存放hbase自己管理的zookeeper的属性数据信息的目录 zookeeper.znode.parent 指定了hbase在zookeeper上使用的节点路径 hbase.wal.provider 配置wal的实现方式:
asyncfs:默认值。自hbase-2.0.0(hbase-1536、hbase-14790)以来新增。它构建在一个新的非阻塞dfsclient实现上。
filesystem:这是hbase-1.x版本中的默认设置。它构建在阻塞的dfsclient上,并以经典的dfsclient管道模式写入副本。
multiwal:由多个asyncfs或filesystem实例组成 -
log4j.properties
通过log4j进行hbase日志记录的配置文件。修改这个文件中的参数可以改变hbase的日志级别。
-
regionservers
包含hbase集群中运行的所有region server主机列表(默认情况下,这个文件包含单个条目localhost)。该文件是一个纯文本文件,每行是一个主机名或ip地址
2. 配置hbase
1)修改hbase配置文件hbase-env.sh
hbase的配置文件hbase-env.sh主要用于配置hbase的运行环境。进入虚拟机hadoop1的/opt/hbase-2.5.8/conf目录,执行vi hbase-env.sh命令编辑配置文件hbase-env.sh,在文件的尾部添加如下内容。
export hbase_manages_zk=false
export java_home=/opt/jdk1.8.0_261
2)修改hbase配置文件hbase-site.xml
hbase的配置文件hbase-site.xml主要用于配置hbase的参数。进入虚拟机hadoop1的/opt/hbase-2.5.8/conf目录,执行vi hbase-site.xml命令编辑配置文件hbase-site.xml,将该文件的<configuration>标签中的默认配置替换为如下内容。
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/data/hbase/tmp</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.datadir</name>
<value>/opt/data/zookeeper/zkdata</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
3)修改hbase配置文件regionservers
hbase的配置文件regionservers用于通过主机名指定运行regionserver的计算机。由于这里在虚拟机hadoop2和hadoop3运行hregionserver进程,执行 vi regionservers 命令编辑配置如下内容。
hadoop2
hadoop3
4)分发hbase安装目录
为了便捷地在虚拟机hadoop2和hadoop3安装和配置hbase,这里通过scp命令将虚拟机hadoop1的相关配置同步到两台主机。
scp -r /opt/hbase-2.5.8 root@hadoop2:/opt/
scp /etc/profile root@hadoop2:/etc/
scp -r /opt/hbase-2.5.8 root@hadoop3:/opt/
scp /etc/profile root@hadoop3:/etc/
四、启动与测试
1. 启动
在hadoop1主机运行如下命令启动集群。
1)启动hadoop
start-all.sh
2)启动zookeeper
xzkserver.sh start
3)启动hbase
start-hbase.sh
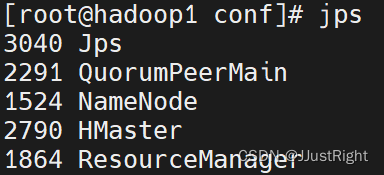
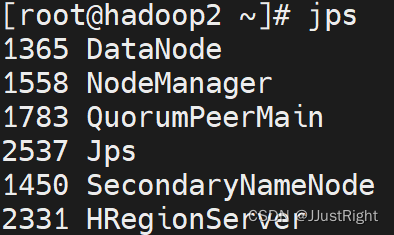
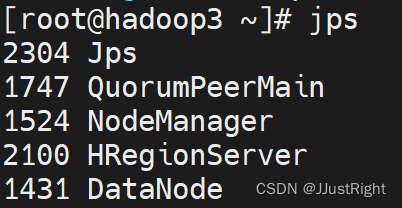
2. 查看进程
分别在hadoop1、hadoop2和hadoop3运行jps命令查看
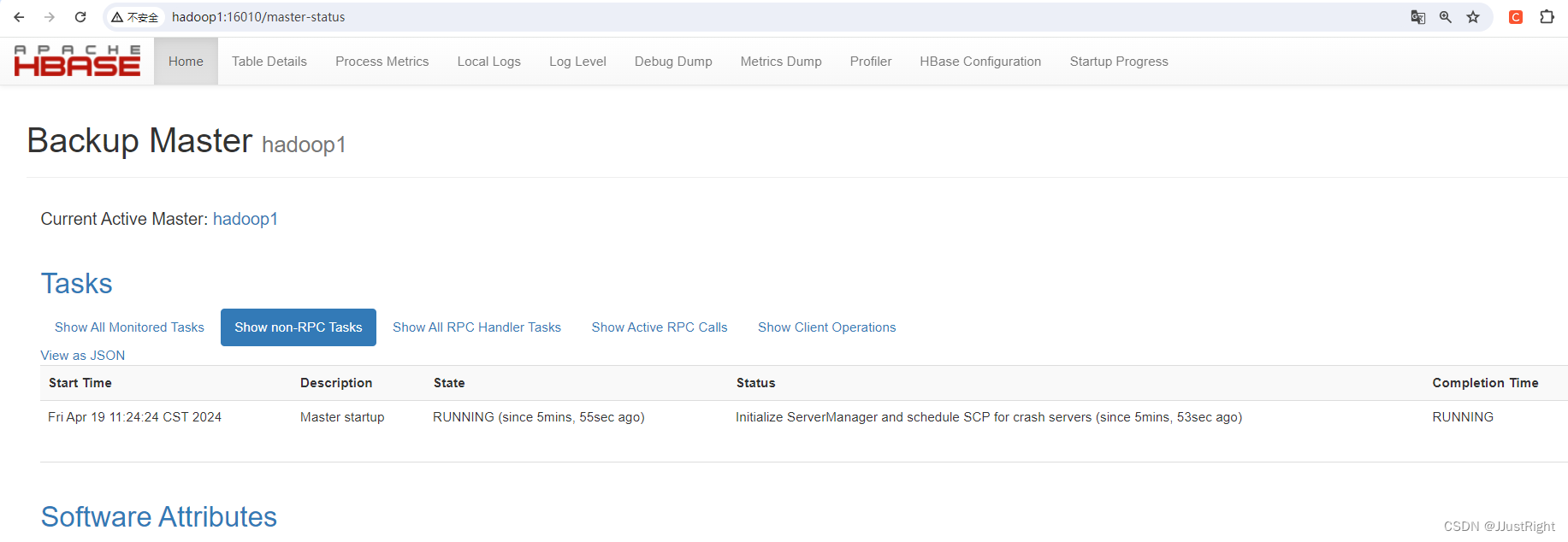
3. 网页查看
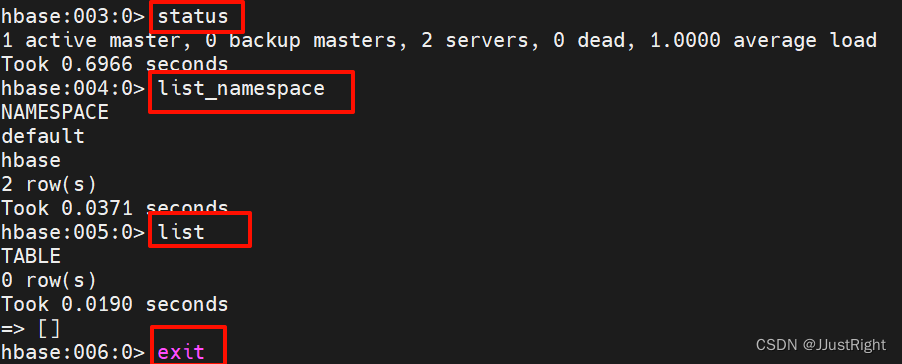
4. shell测试
进入hbase shell交互界面,查看集群状态、命名空间列表、表列表,最后退出交互界面
hbase shell
> status
> list_namespace
> list
> exit
5. 关闭集群
在hadoop1主机运行如下命令关闭集群。
stop-hbase.sh #关闭hbase集群
xzkserver.sh stop #关闭zookeeper集群
stop-all.sh #关闭hadoop集群
附、网盘资源
链接:https://pan.baidu.com/s/1msudwbpariaglqtdrhojrg?pwd=jiau
提取码:jiau


发表评论