目标跟踪
1、delving into the trajectory long-tail distribution for muti-object tracking
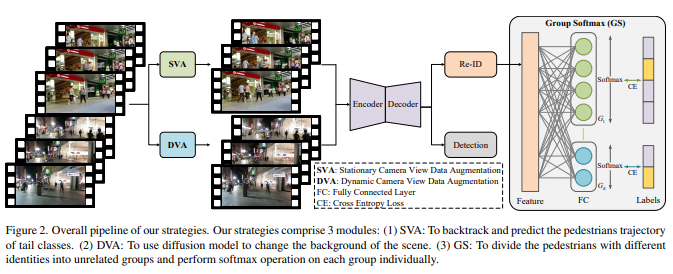
多目标跟踪(multiple object tracking,mot)是计算机视觉领域中一个关键领域,有广泛应用。当前研究主要集中在跟踪算法的开发和后处理技术的改进上。然而,对跟踪数据本身的特性缺乏深入的研究。
本研究首次对跟踪数据的分布模式进行探索,并发现现有 mot 数据集中存在明显的长尾分布问题。发现不同行人分布存在显著不平衡现象,将其称为“行人轨迹长尾分布”。针对这一挑战,提出一种专门设计用于减轻这种分布影响的策略。具体而言,提出两种数据增强策略,包括静态摄像机视图数据增强(sva)和动态摄像机视图数据增强(dva),针对视点状态,以及面向 re-id 的 group softmax(gs)模块。sva 是为了回溯并预测尾部类别的行人轨迹,而 dva 则使用扩散模型改变场景的背景。gs 将行人划分为不相关的组,并对每个组进行 softmax 操作。
策略可以集成到许多现有的跟踪系统中,实验证实方法在降低长尾分布对多目标跟踪性能的影响方面的有效性。https://github.com/chen-si-jia/trajectory-long-tail-distribution-for-mot
目标检测
2、safdnet: a simple and effective network for fully sparse 3d object detection
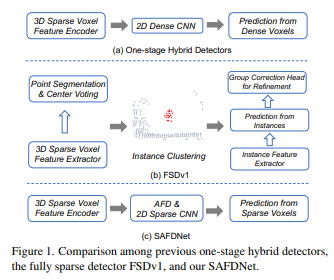
基于 lidar 的三维物体检测,在自动驾驶中起关键作用。目前已有的高性能三维物体检测器通常在骨干网络和预测头中构建密集特征图。然而,随着感知范围增加,密集特征图带来的计算成本呈二次增长,使得这些模型很难扩展到长距离检测。最近一些研究尝试构建完全稀疏的检测器来解决这个问题,然而所得模型要么依赖于复杂的多阶段流水线,要么表现不佳。
本文提出 safdnet,简单高效,专为完全稀疏的三维物体检测而设计。在 safdnet 中,设计了一种自适应特征扩散策略来解决中心特征丢失的问题。在 waymo open、nuscenes 和 argoverse2 数据集上进行大量实验证明,safdnet 在前两个数据集上的性能略优于先前的 sota,但在具有长距离检测特点的最后一个数据集上表现更好,验证 safdnet 在需要长距离检测的场景中的有效性。
在 argoverse2 上,safdnet 在速度上比先前最好的混合检测器 hednet 快 2.1 倍,并且相对于先前最好的稀疏检测器 fsdv2 提高了 2.1% 的 map,速度提高了 1.3 倍。https://github.com/zhanggang001/hednet
3、detdiffusion: synergizing generative and perceptive models for enhanced data generation and perception
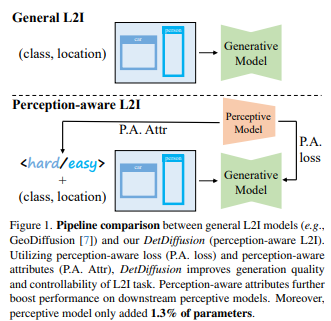
当前的感知模型严重依赖于资源密集型数据集,因此需要创新性的解决方案。利用最近在扩散模型和合成数据方面的进展,通过构造各种标签图像输入,合成数据有助于下游任务。尽管之前的方法已经分别解决了生成和感知模型的问题,但是 detdiffusion 是第一个在生成有效数据的感知模型方面进行了整合的方法。
为增强感知模型的图像生成能力,引入感知损失(p.a. loss)通过分割来改善质量和可控性。为提高特定感知模型的性能,方法通过提取和利用感知感知属性(p.a. attr)来定制数据增强。来自目标检测任务的实验结果凸显了 detdiffusion 在布局导向生成方面的出色性能,显著提高了下游检测性能。
4、sddgr: stable diffusion-based deep generative replay for class incremental object detection

在类别增量学习(cil)领域,generative replay已成为缓解灾难性遗忘的方法,随着生成模型的不断改进,越来越受到关注。然而,在类别增量物体检测(ciod)中的应用受到很大限制,主要是由于涉及多个标签的场景的复杂性。
本文提出一种名为stable diffusion deep generative replay(sddgr)的用于 ciod 的新方法。方法利用基于扩散的生成模型与预训练的文本到扩散网络相结合,生成真实多样的合成图像。sddgr采用迭代优化策略,生成高质量的旧类别样本。此外,采用l2知识蒸馏技术,以提高合成图像中先前知识的保留。此外,方法还包括对新任务图像中的旧对象进行伪标签,以防止将其错误分类为背景元素。
对coco 2017数据集的大量实验表明,sddgr在各种ciod场景下明显优于现有算法,达到了新的技术水平。
关键点检测
5、pose-guided self-training with two-stage clustering for unsupervised landmark discovery
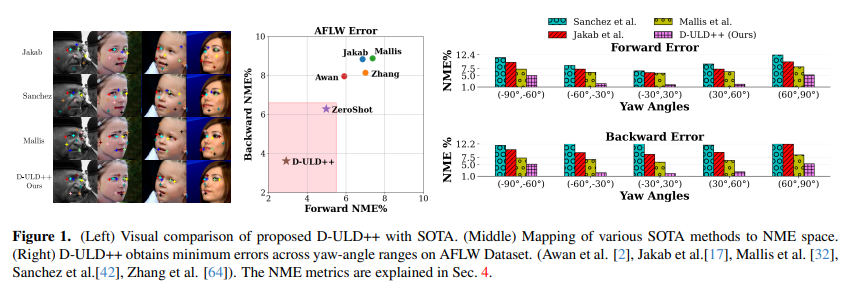
无监督的unsupervised landmarks discovery(uld)是具有挑战性的计算机视觉问题。为利用扩散模型在uld任务中的潜力,首先,提出一种基于随机像素位置的简单聚类的零样本uld基线,通过最近邻匹配提供了比现有uld方法更好的结果。其次,在零样本性能的基础上,通过自训练和聚类开发了一种基于扩散特征的uld算法,以显著超越以前的方法。第三,引入一个基于生成潜在姿势代码的新代理任务,并提出了一个两阶段的聚类机制,以促进有效的伪标签生成,从而显著提高性能。
总的来说,方法在四个具有挑战性的基准测试(aflw、mafl、catheads 和 ls3d)上一贯优于现有的最先进方法。
deepfake检测
6、latent reconstruction error based method for diffusion-generated image detection
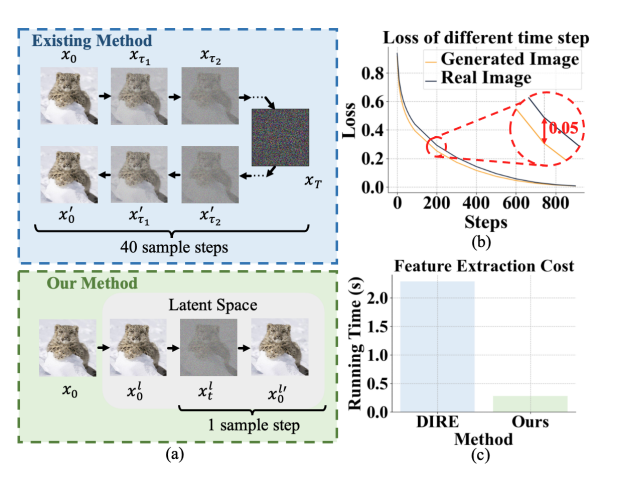
扩散模型极大提高了图像生成质量,使得真实图像和生成图像之间越来越难以区分。然而,这一发展也引发了重大的隐私和安全问题。针对这一问题,提出一种新的潜变量重构误差引导特征优化方法(latent reconstruction error guided feature refinement, lare2),用于检测生成图像。
提出潜变量重构误差(latent reconstruction error,lare),一种基于重构误差的潜在空间特征,用于生成图像检测。lare 在特征提取效率方面超过了现有方法,同时保留了区分真实与伪造图像所需的关键线索。为了利用 lare,提出一个带有误差引导特征优化模块(egre)的方法,通过 lare 引导图像特征的优化,以增强特征的辨别力。
egre 采用对齐然后细化机制,可以从空间和通道角度有效地细化图像特征,以进行生成图像检测。在大规模 genimage 基准测试上的大量实验证明lare2 的优越性,在 8 个不同的图像生成器中超过了最好的 sota 方法,平均 acc/ap 高达 11.9%/12.1%。lare 在特征提取成本方面也超越了现有方法,速度提升8倍。
异常检测
7、realnet: a feature selection network with realistic synthetic anomaly for anomaly detection

自监督特征重建方法在工业图像异常检测和定位方面显示出有希望进展。这些方法在合成真实且多样化的异常样本以及解决预训练特征的特征冗余和预训练偏差方面仍然面临挑战。
这项工作提出 realnet,一种具有现实合成异常和自适应特征选择的特征重建网络。它包含三个关键创新:首先,提出强度可控扩散异常合成(sdas),一种基于扩散过程的合成策略,能够生成具有不同异常强度的样本,模仿真实异常样本的分布。其次,开发了异常感知特征选择(afs),一种选择具有代表性和判别性的预训练特征子集的方法,以提高异常检测性能,同时控制计算成本。第三,引入了重建残差选择(rrs),一种自适应选择判别残差以跨多个粒度级别全面识别异常区域的策略。
在四个基准数据集上评估 realnet,结果表明与当前最先进的方法相比,图像 auroc 和像素 auroc 都有改进。https://github.com/cnulab/realnet
更多:
cvpr 2024 | 图像超分、图像恢复汇总!用aigc扩散模型diffusion来解决图像low-level任务的思路
cvpr 2024 | 风格迁移和人像生成汇总!扩散模型diffusion用于经典aigc方向
cvpr 2024 | 从6篇论文看扩散模型diffusion的改进方向
cvpr 2024 | 前沿而相对小众!几个aigc扩散模型diffusion应用一览
关注公众号【机器学习与ai生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我t m直接用来跟进 aigc+cv视觉 前沿技术,它不香?!
iccv 2023 | 最全aigc梳理,5w字30个diffusion扩散模型方向,近百篇论文!
卧剿,6万字!30个方向130篇!cvpr 2023 最全 aigc 论文!一口气读完
深入浅出stable diffusion:ai作画技术背后的潜在扩散模型论文解读
深入浅出controlnet,一种可控生成的aigc绘画生成算法!

最新最全100篇汇总!生成扩散模型diffusion models
附下载 |《tensorflow 2.0 深度学习算法实战》
点击跟进 aigc+cv视觉 前沿技术,真香!,加入 ai生成创作与计算机视觉 知识星球!

发表评论