
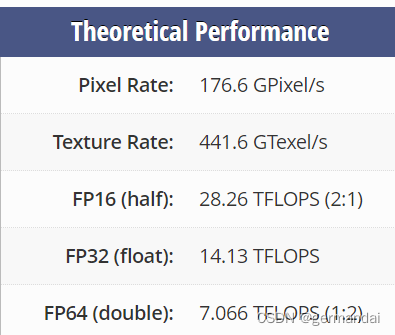

v100是volta架构,a10是ampere架构,架构上讲a10先进点,其实只是制程区别,用起来没区别。
v100是hbm的内存读取,带宽大,但是ddr5的。
二块卡都是全精度为主的算力卡,半精度优势不明显。
需要用大内存的,选a10, 24g用起来舒服。核心也多。
需要用复杂运算的,选v100tensorrt多出不少,而且现在的ai都支持tensorrt了。如果玩双精度,就优势很明显了。
如果是人民币玩家,当生产力工具的,肯定是选择a10了,毕竟性价比优势摆着。
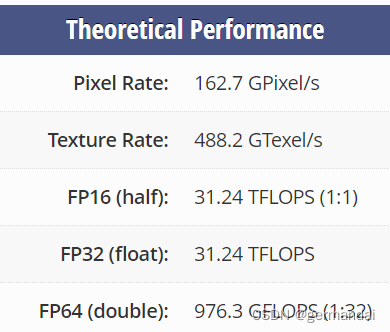
v100是volta架构,a10是ampere架构,架构上讲a10先进点,其实只是制程区别,用起来没区别。
v100是hbm的内存读取,带宽大,但是ddr5的。
二块卡都是全精度为主的算力卡,半精度优势不明显。
需要用大内存的,选a10, 24g用起来舒服。核心也多。
需要用复杂运算的,选v100tensorrt多出不少,而且现在的ai都支持tensorrt了。如果玩双精度,就优势很明显了。
如果是人民币玩家,当生产力工具的,肯定是选择a10了,毕竟性价比优势摆着。

最近在用PyTorch时发现在本地训练模型速度一言难尽,然后发现阿里云可以白嫖gpu服务器,只要没有申请过PAI-DSW资源的新老用户都可以申请5000CU*H的免费额度,三个月内…
免费的GPT接口国内的使用一段实践就会失效,阿里云的==qwen-1.8b-chat==限时免费,可对接!目前本账号小助手也是对接了该模型…

【大数据 OLAP 技术新书推荐】 字节跳动阿里巴巴大厂资深架构师程序员多年实践经验总结《ClickHouse入门、实战与进阶》ClickHouse领域集大成之作,入门标准参考书日常工作案头必备手册
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。 如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。

发表评论