中途踩了好多坑,折腾了快一个礼拜才跑出来,真的好搞心态!!这篇帖子详细记录怎么用用阿里云服务器运行深度学习代码,雷点也都会说清楚。
我的代码运行环境:
一、购买云服务器
建议买的时候联系客服,说下自己的需求,客服会给出比较好的建议。现在有的优惠是300元优惠券和3个月试用,但3个月试用的配置好像比较一般。
这里提供下我的配置。付费类型,考虑到抢占式实例有可能会被自动释放、影响跑代码,我使用了按量付费。地域选择一个离自己比较近的。网络根据默认。
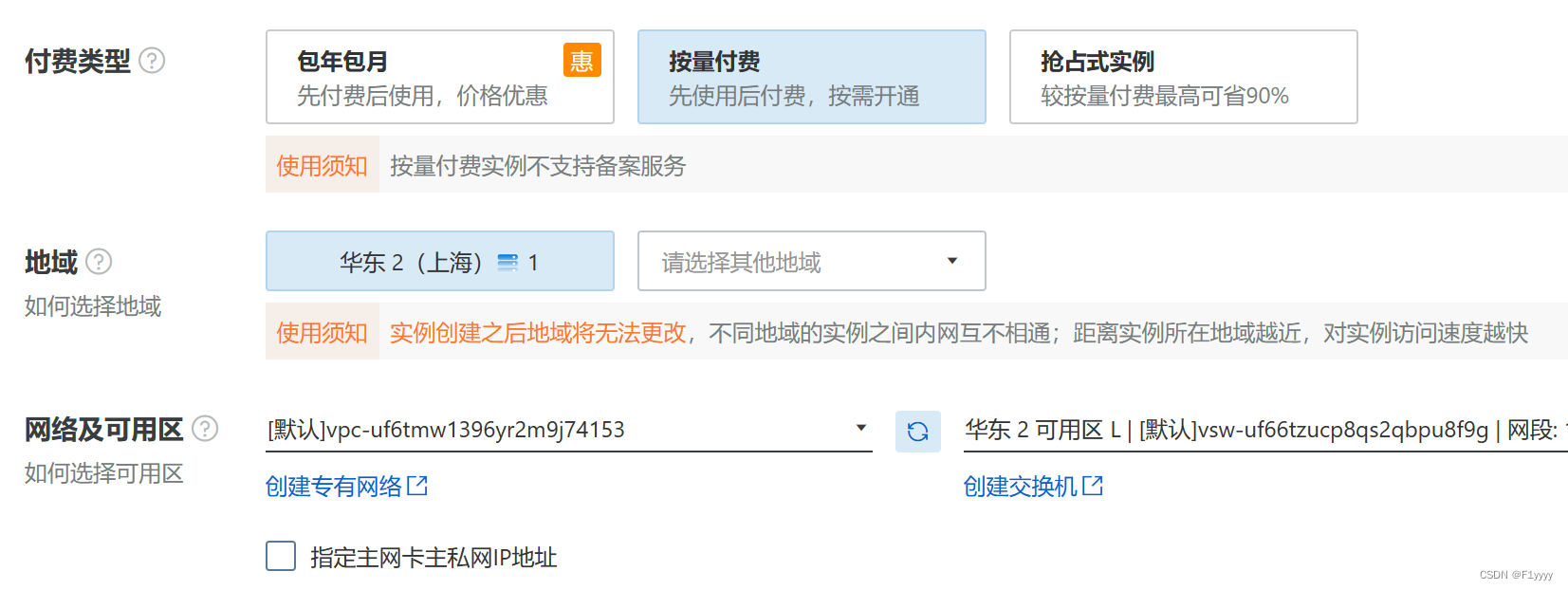
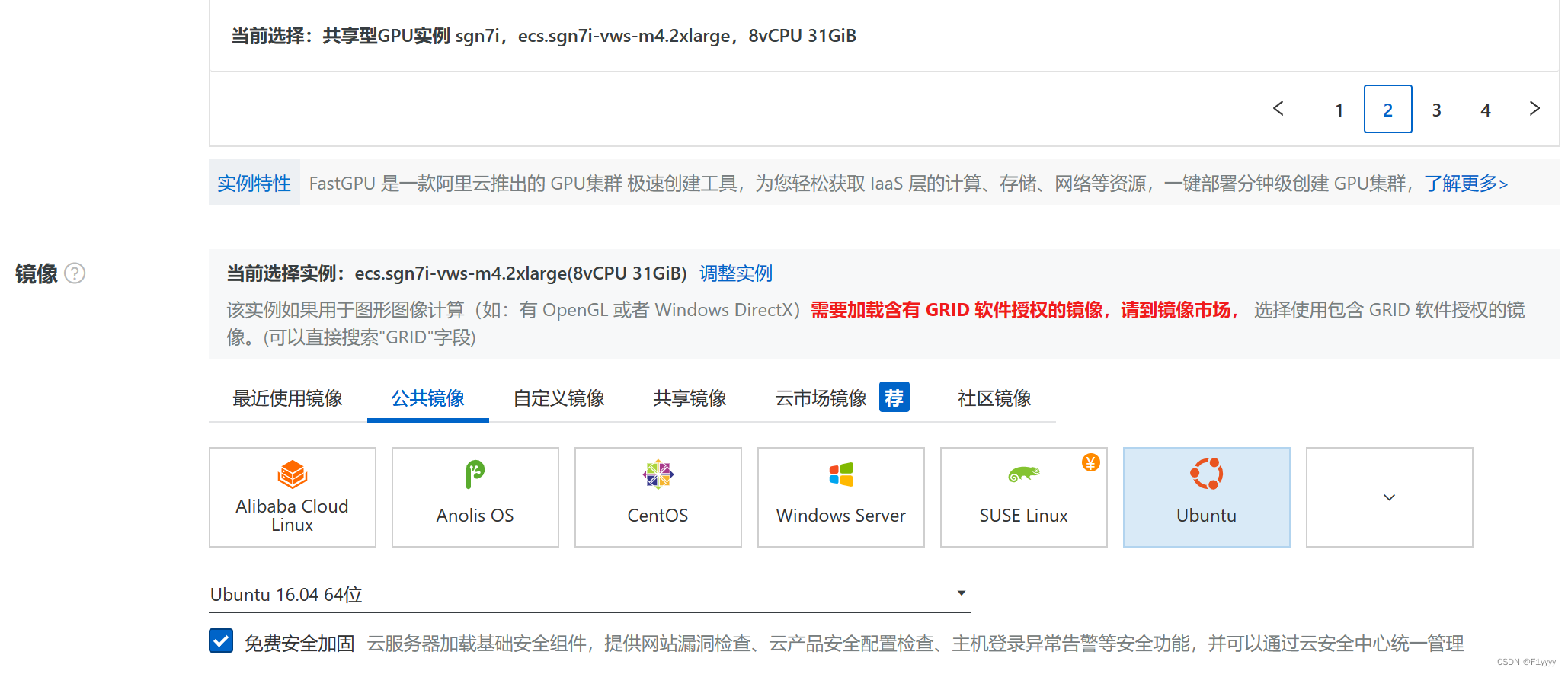
实例选择gpu类中的共享型gpu。镜像根据环境要求,选择了ubuntu16.04,并且安全加固。
这里附上阿里云提供的参考:
- 轻量级gpu是指gpu计算型实例,可以降低小规模ai推理过程的使用成本;共享型gpu是指gpu虚拟化型实例,cpu和网络资源采用共享模式提供,内存和gpu显存采用独享模式提供,为您提供数据隔离和性能保障。
- gpu与cpu配比:对于深度学习训练,考虑gpu与cpu的最佳比例在1:8到1:12之间。如果是通用深度学习、图像识别推理等场景,gpu与cpu的比例推荐为1:4到1:12之间。
- 如果涉及大规模的深度学习训练,推荐使用gpu加速型实例,如gn系列或p系列,这些实例配备高性能nvidia gpu,适合深度学习和科学计算场景。(可以选择安装gpu驱动,就不用自己配啦)
存储部分,开启了快照服务。

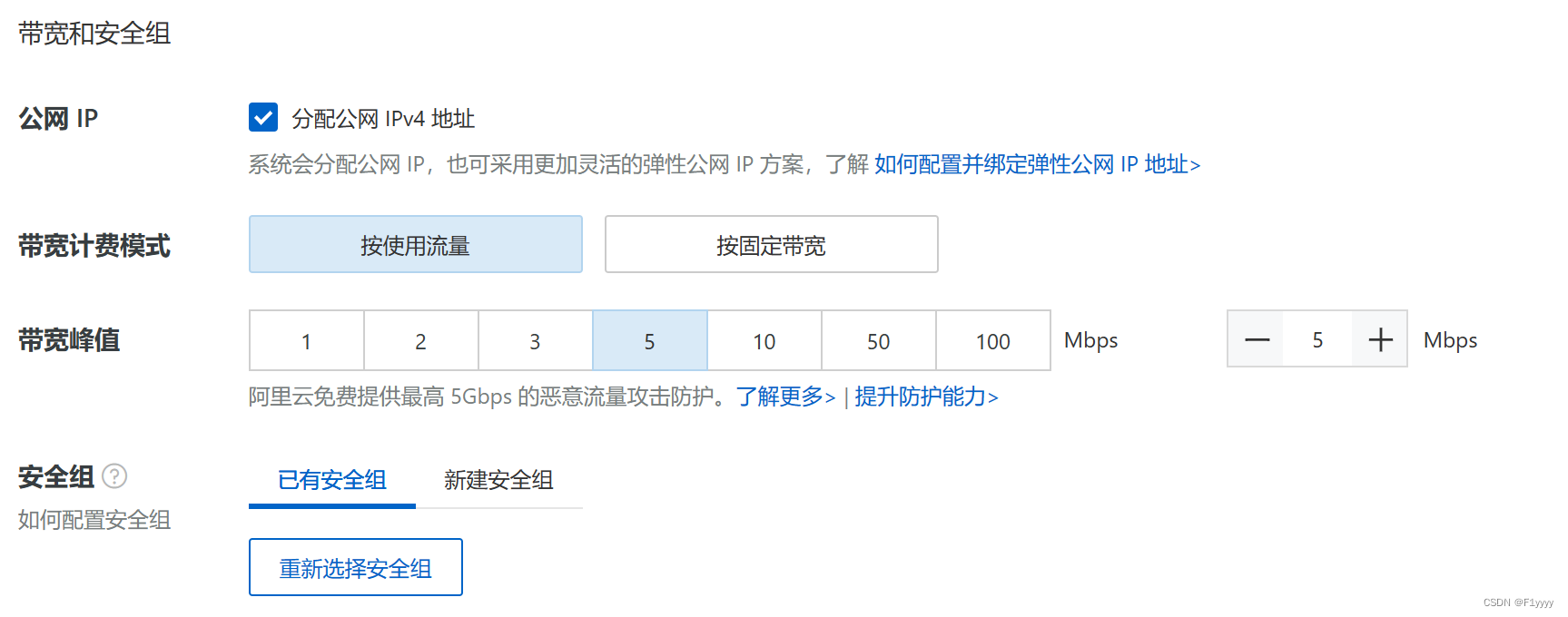
带宽和安全组部分,记得勾上公网ip,方便远程连接服务器。安全组默认。
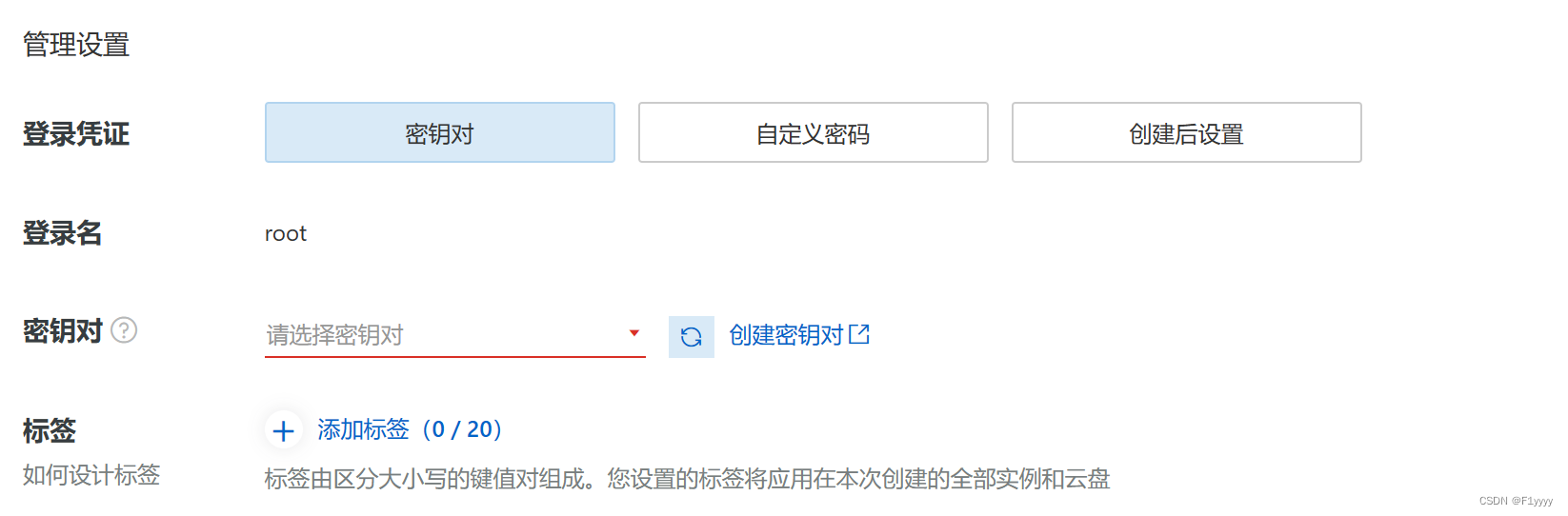
选择密钥对,登录服务器的时候就用密钥对验证。自己创建一个,并且保存好密钥对的.pem文件就好了。
下单,成功购买服务器啦。进入管理控制台,进行接下来的操作。
二、连接服务器
可以使用阿里云提供的workbench进行远程连接。我使用的是xshell进行远程连接,xftp进行文件传输。安装教程:windows 下 xshell 和 xftp 安装与使用_window安装xshell xftp-csdn博客
连接教程:如何用云服务器进行深度学习 - 知乎 (zhihu.com)(第二节~)
连接上了以后我出现了提示:/usr/bin/xauth: file /root/.xauthority does not exist ,这个不是问题,具体可看:【庖丁解牛】xshell链接服务器 /usr/bin/xauth: file /root/.xauthority does not exist_/usr/bin/xauth: file /root/.xauthority does not ex-csdn博客
三、配置环境
1、安装gpu驱动
一般都是上网下载nvidia驱动并安装,不过在我各种报错并咨询阿里云客服后,发现因为购买的是gpu虚拟化实例 ecs.sgn7i-vws,需要安装grid驱动^^...
参考文档:https://help.aliyun.com/zh/egs/user-guide/use-cloud-assistant-to-automatically-install-and-upgrade-grid-drivers?spm=a2c4g.11186623.0.0.7f807130fqby5c#464af6d03ffcn 通过云助手安装一下grid驱动就可以了,中途遇到问题可以咨询客服解决。在附录补充了nvidia驱动的安装教程,别的实例类型也可以参考~
安装好后,输入以下命令查看当前gpu的所有基础信息:
nvidia-smi这里你会看到有个cuda的版本,这是cuda driver api的型号,也是硬件可以支持的cuda的最高型号。
2、安装cuda
这里有个大雷点:一定要注意cuda版本!!
查看电脑gpu的算力:cuda gpus - compute capability | nvidia developer,以我为例,在实例中看到型号是nvidia a10,查找到算力为8.6。
根据算力,找到支持该算力的对应的cuda版本。虽然我的开源代码是在cuda10.1上运行,但是其仅支持算力3.7,5.0,6.0,7.0;于是我重新安装了cuda11.1,符合算力要求。
补充说下,使用以下命令,在终端进入python,可查看当前版本的pytorch依赖的cuda算力支持:
import torch
torch.cuda.get_arch_list()接下来就是安装cuda11.1,在官网中找到安装链接:cuda toolkit 11.1.0 | nvidia developer
根据官网给出的教程操作就好了,附上代码:
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run
sudo sh cuda_11.1.0_455.23.05_linux.run接下来进行环境变量的配置:
#修改~/.bashrc文件
vim ~/.bashrc
#在文件的末尾加入下面两行(记得换成自己安装的cuda版本号)
export path=/usr/local/cuda-11.1/bin${path:+:${path}}
export ld_library_path=/usr/local/cuda-11.1/lib64${ld_library_path:+:${ld_library_path}}
#按esc,输入:wq,并回车,保存退出
#更新环境变量
source ~/.bashrc通过以下命令查看cuda版本(cuda runtime api),验证是否安装成功:
nvcc -v3、安装cudnn
参考文章:如何用云服务器进行深度学习 - 知乎 (zhihu.com)(3.1.2部分)
补充一些出入,传输文件的端口打开部分,阿里云界面略有变化,点击侧栏的【安全组】【操作-管理规则】:
【快速添加】,之后根据文章中来就好了:
最后验证环节,我找了半天才找到,可以参考:
cat /usr/local/cuda-11.1/include/cudnn_version.h | grep cudnn_major -a 24、安装anaconda
清华镜像源好像不对阿里云服务器开放,所以我用阿里云镜像源下载了,地址:anaconda-archive安装包下载_开源镜像站-阿里云 (aliyun.com)
找到要下载的版本(这里选择 anaconda3-5.0.0.1-linux-x86_64.sh
),复制链接:
#下载安装包
wget https://mirrors.aliyun.com/anaconda/archive/anaconda3-5.0.0.1-linux-x86_64.sh
#查看安装包名
ls
#安装
bash 下载文件名.sh参考文章:如何用云服务器进行深度学习 - 知乎 (zhihu.com)(3.2部分),添加变量就好了~
介绍一些常用的环境管理代码:
#创建环境
conda create -n 环境名 python=python版本
#激活环境,从base进入到创建的环境
conda activate 环境名
#退出该环境
conda deactivate
#删除环境(需要先退出该环境)
conda remove -n 环境名 --all
#查看全部环境
conda env list
#查看环境中安装的包
conda list5、修改conda镜像源
修改成国内的阿里云镜像源,代码如下:
conda config --add channels http://mirrors.aliyun.com/anaconda/pkgs/main
conda config --add channels http://mirrors.aliyun.com/anaconda/pkgs/r
conda config --add channels http://mirrors.aliyun.com/anaconda/pkgs/msys2
conda config --set show_channel_urls yes四、源码上传
参考文章:记录一次服务器跑数据的全过程_如何使用远程服务器跑数据-csdn博客(第五节)
五、虚拟环境中配置深度学习框架
又是一个大雷点,一定要注意版本匹配!
这是我的代码需要的包:
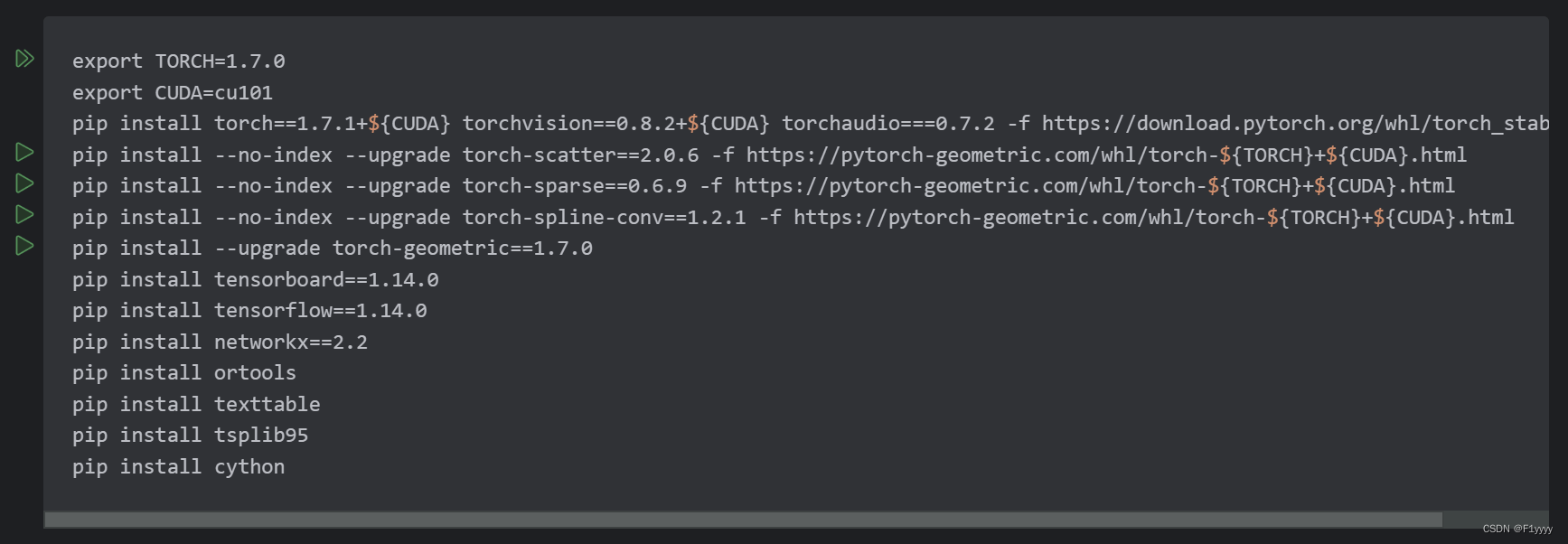
1、安装pytorch
因为安装的cuda版本变化,所以相应的pytorch版本也发生了变化。根据官网来:
previous pytorch versions | pytorch
pip install --no-cache-dir torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
安装好以后,终端进入python验证:
import torch
#查看pytorch版本
print(torch.__version__)
#验证cuda是否被pytorch检测到
torch.cuda.is_available()
#output:true
#验证pytorch能不能调用cuda加速
torch.tensor([1.0, 2.0]).cuda()
#output:tensor([1., 2.], device='cuda:0')2、安装pytorch-geometric
进入链接https://pytorch-geometric.com/whl/,找到对应torch版本并进入,安装相关包。
pip install --no-index --upgrade torch-scatter==2.0.6 -f https://pytorch-geometric.com/whl/torch-${torch}+${cuda}.html
pip install --no-index --upgrade torch-sparse==0.6.9 -f https://pytorch-geometric.com/whl/torch-${torch}+${cuda}.html
pip install --no-index --upgrade torch-spline-conv==1.2.1 -f https://pytorch-geometric.com/whl/torch-${torch}+${cuda}.html
pip install --upgrade torch-geometric==1.7.03、安装其他相关包
和截图中一样,全部包安装完就可以跑代码啦~
附录a 安装nvidia驱动
注意驱动一定要和gpu型号对应!
进入官网official drivers | nvidia,选择对应配置。我的gpu型号是ga102gl [a10],对应下图:
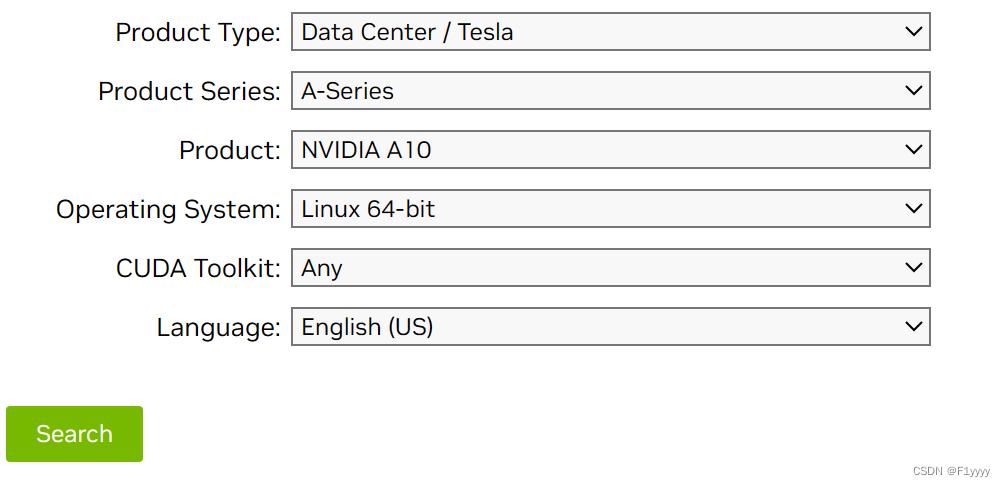
点击search后,可在supported products中查看支持的型号。点击download,进入下一页面,复制agree& download的链接。
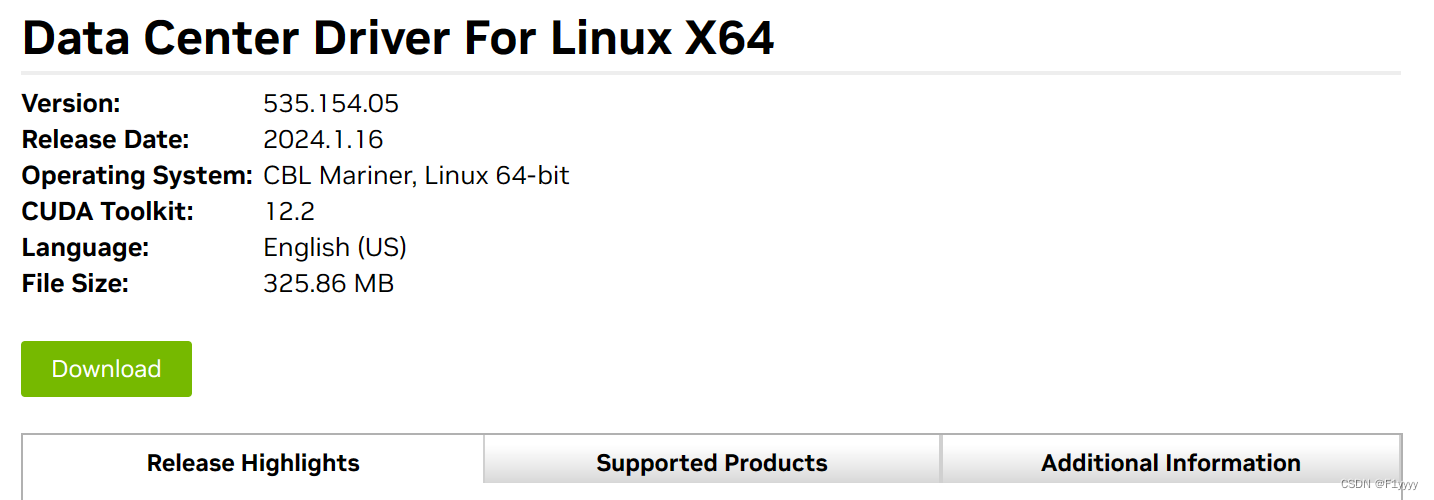
wget https://us.download.nvidia.com/tesla/535.154.05/nvidia-linux-x86_64-535.154.05.run
sudo chmod a+x nvidia-linux-x86_64-535.154.05.run
sudo sh ./nvidia-linux-x86_64-535.154.05.run -no-opengl-files参考文章:ubuntu18-22.04安装和干净卸载nvidia显卡驱动——超详细、最简单_ubuntu安装nvidia显卡驱动-csdn博客
补充一个问题和解决方法:“you appear to be running an x server please exit x before installing”
sudo /etc/init.d/lightdm stop
sudo /etc/init.d/lightdm status



发表评论