高频数据的重复值处理
数据源为高频 trades 数据
1. 导入数据
import pandas as pd
df = pd.read_csv('hf_data.csv')
print(df)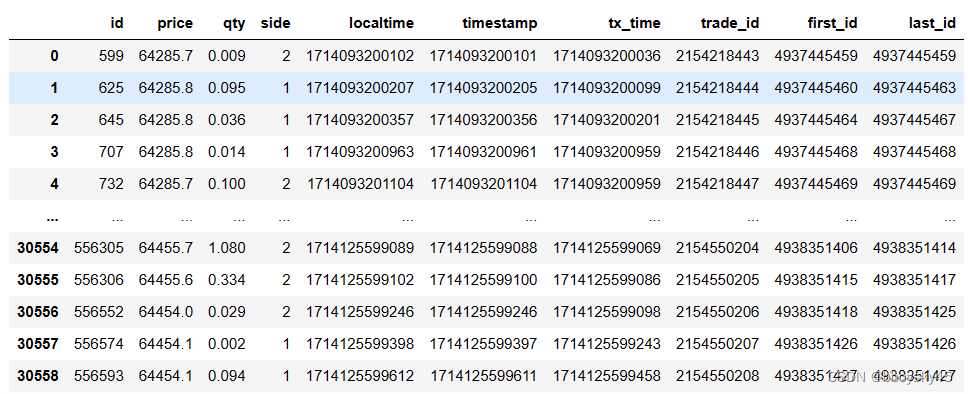
2. duplicate方法查看重复值
(1)subset 参数指定columns name
df.duplicated(subset='localtime').sum()subset指定localtime判断是否存在重复值,返回bool
check_localtime = df.duplicated(subset='localtime')
df[check_localtime>0].tail(20)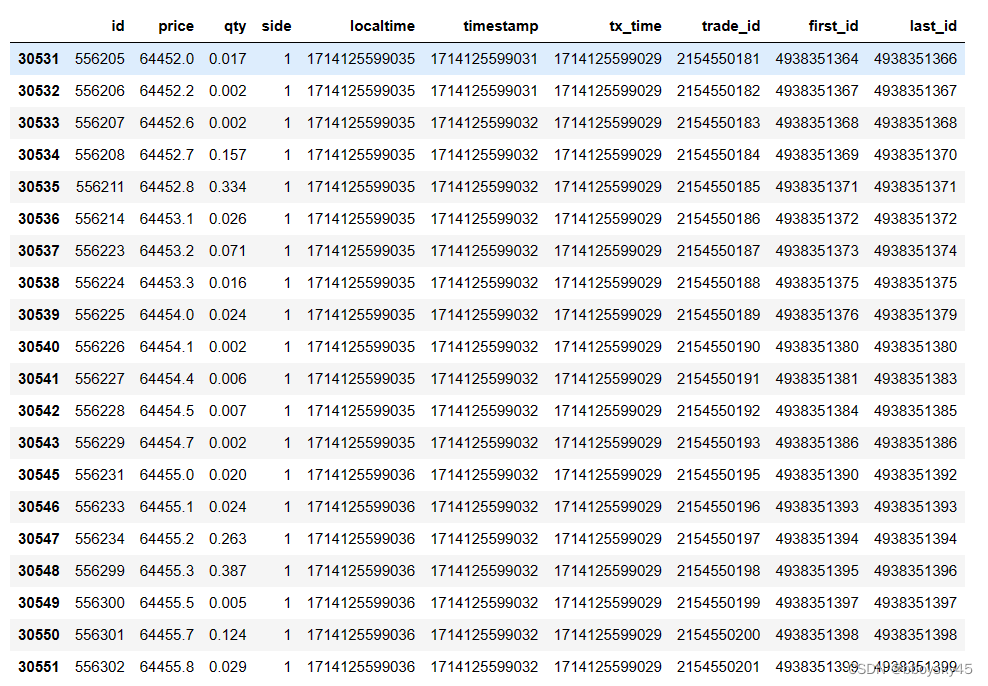
可以看到同个时间戳有多笔成交。
3. 重复值处理
针对不同的数据需求,最简单的三种重复值处理方法。
(1)drop_duplicated() 直接删除掉重复数据
df_drop_duplicate = df.drop_duplicates(subset='localtime')
print("原数据shape",df.shape)
print("删除重复值后数据shape",df_drop_duplicate.shape)
print("检验重复值,",df_drop_duplicate.duplicated().sum())
可以看到重复数据占比还是比较多的,若重复数据有意义,比如该数据描述的是 交易数据,则当同个时间戳有多个交易数据描述了当下市场的活跃情况;因此用该方案做数据处理并不一定合适。
(2)保留重复值中的第一个或最后一个:drop_duplicated的keep参数
df_keep_last = df.drop_duplicates(subset='localtime',keep='last')当我们想保留重复数据最后一个值,可以使用drop_duplicated的keep参数,"last"为最后一个值,“first”为第一个值。
(3)使用groupby对重复值做运算
分析原数据:localtime重复是因为同个时间多笔成交单形成,其次数据中有其他的属性比如价格(price),成交量(qty),交易方向(side);因此比较合适的处理方法是将数据时间戳合并到最小单位1ms,而针对不同的属性,可以采取:保留最后一个价格,总成交量等等;这样即处理了重复值的问题,也保留了数据中的信息
df.groupby(by='localtime').agg({'qty':"sum",'price':"last"})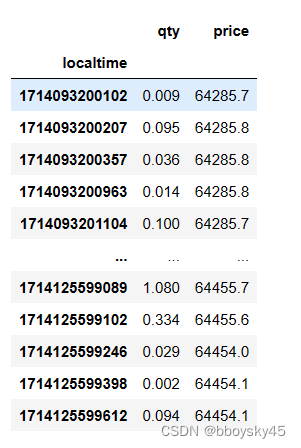


发表评论