这是继上一篇文章 “elasticsearch:painless scripting 语言(一)” 的续篇。
使用 field api 访问文档中的字段
使用 field api 访问文档字段:
field('my_field').get(<default_value>)
此 api 从根本上改变了你在 painless 中访问文档的方式。以前,你必须使用要访问的字段名称来访问 doc map:
doc['my_field'].value
以这种方式访问文档字段无法处理缺失值或缺失映射,这意味着要编写强大的 painless 脚本,你需要包含逻辑来检查字段和值是否存在。
相反,使用 field api,这是在 painless 中访问文档的首选方法。field api 处理缺失值,并将发展为抽象访问 _source 和 doc_values。
field api 返回一个 field 对象,该对象迭代具有多个值的字段,通过 get(<default_value>) 方法以及类型转换和辅助方法提供对基础值的访问。
field api 返回你指定的默认值,无论该字段是否存在或当前文档是否有任何值。这意味着 field api 可以处理缺失值而无需额外的逻辑。对于keyword 等引用类型,默认值可以为 null。对于 boolean 或 long 等原始类型,默认值必须是匹配的原始类型,例如 false 或 1。
方便、更简单的访问
你可以包含 $ 快捷方式,而不必使用 get() 方法显式调用字段 api。只需包含 $ 符号、字段名称和默认值(以防字段没有值):
$(‘field’, <default_value>)
借助这些增强的功能和简化的语法,你可以编写更短、更简单、更易读的脚本。例如,以下脚本使用过时的语法来确定索引文档中两个复杂 datetime 值之间的毫秒差:
if (doc.containskey('start') && doc.containskey('end')) {
if (doc['start'].size() > 0 && doc['end'].size() > 0) {
zoneddatetime start = doc['start'].value;
zoneddatetime end = doc['end'].value;
return chronounit.millis.between(start, end);
} else {
return -1;
}
} else {
return -1;
}
使用 field api,你可以更简洁地编写相同的脚本,而无需在操作字段之前添加额外的逻辑来确定字段是否存在:
zoneddatetime start = field('start').get(null);
zoneddatetime end = field('end').get(null);
return start == null || end == null ? -1 : chronounit.millis.between(start, end)
支持的 mapped 字段类型
下表列出了 field api 支持的映射字段类型。对于每种支持的类型,列出了 field api(来自 get 和 as<type> 方法)和 doc map(来自 getvalue 和 get 方法)返回的值。
| mapped field type | returned type from field |
returned type from doc |
||
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
|
|
|
- |
|
|
常见脚本用例
你可以编写脚本来执行几乎任何操作,但有时,这就是问题所在。了解脚本的用途非常困难,因此以下示例介绍了脚本真正有用的常见用例。
字段提取 - field extraction
字段提取的目标很简单;你的数据中有一些包含大量信息的字段,但你只想提取部分信息。
你可以使用两种选项:
- grok 是一种正则表达式方言,支持你可以重复使用的别名表达式。由于 grok 位于正则表达式 (regex) 之上,因此任何正则表达式在 grok 中也有效。
- dissect 从文本中提取结构化字段,使用分隔符来定义匹配模式。与 grok 不同,dissect 不使用正则表达式。
让我们从一个简单的示例开始,将 和 message 字段作为索引字段添加到 my-index 映射中。为了保持灵活性,请使用通配符作为 message 的字段类型:
delete my-index
put /my-index/
{
"mappings": {
"properties": {
"@timestamp": {
"format": "strict_date_optional_time||epoch_second",
"type": "date"
},
"message": {
"type": "wildcard"
}
}
}
}
映射要检索的字段后,将日志数据中的几条记录索引到 elasticsearch 中。以下请求使用 bulk api 将原始日志数据索引到 my-index 中。你可以使用小样本来试验运行时字段,而不是索引所有日志数据。
post /my-index/_bulk?refresh
{"index":{}}
{"timestamp":"2020-04-30t14:30:17-05:00","message":"40.135.0.0 - - [30/apr/2020:14:30:17 -0500] \"get /images/hm_bg.jpg http/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30t14:30:53-05:00","message":"232.0.0.0 - - [30/apr/2020:14:30:53 -0500] \"get /images/hm_bg.jpg http/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30t14:31:12-05:00","message":"26.1.0.0 - - [30/apr/2020:14:31:12 -0500] \"get /images/hm_bg.jpg http/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30t14:31:19-05:00","message":"247.37.0.0 - - [30/apr/2020:14:31:19 -0500] \"get /french/splash_inet.html http/1.0\" 200 3781"}
{"index":{}}
{"timestamp":"2020-04-30t14:31:22-05:00","message":"247.37.0.0 - - [30/apr/2020:14:31:22 -0500] \"get /images/hm_nbg.jpg http/1.0\" 304 0"}
{"index":{}}
{"timestamp":"2020-04-30t14:31:27-05:00","message":"252.0.0.0 - - [30/apr/2020:14:31:27 -0500] \"get /images/hm_bg.jpg http/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30t14:31:28-05:00","message":"not a valid apache log"}
从日志消息中提取 ip 地址 (grok)
如果你想要检索包含客户端 ip 的结果,则可以将该字段作为运行时字段添加到映射中。以下运行时脚本定义了一个 grok 模式,该模式从消息字段中提取结构化字段。
该脚本与 %{commonapachelog} 日志模式匹配,该模式了解 apache 日志的结构。如果模式匹配 (clientip != null),则脚本会发出匹配 ip 地址的值。如果模式不匹配,则脚本只会返回字段值而不会崩溃。
put my-index/_mappings
{
"runtime": {
"http.clientip": {
"type": "ip",
"script": """
string clientip=grok('%{commonapachelog}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip); // 1
"""
}
}
}
- 条件确保即使消息的模式不匹配,脚本也不会发出任何内容。
你可以定义一个简单的查询来搜索特定的 ip 地址并返回所有相关字段。使用搜索 api 的 fields 参数来检索 http.clientip 运行时字段。
get my-index/_search
{
"query": {
"match": {
"http.clientip": "40.135.0.0"
}
},
"fields" : ["http.clientip"]
}
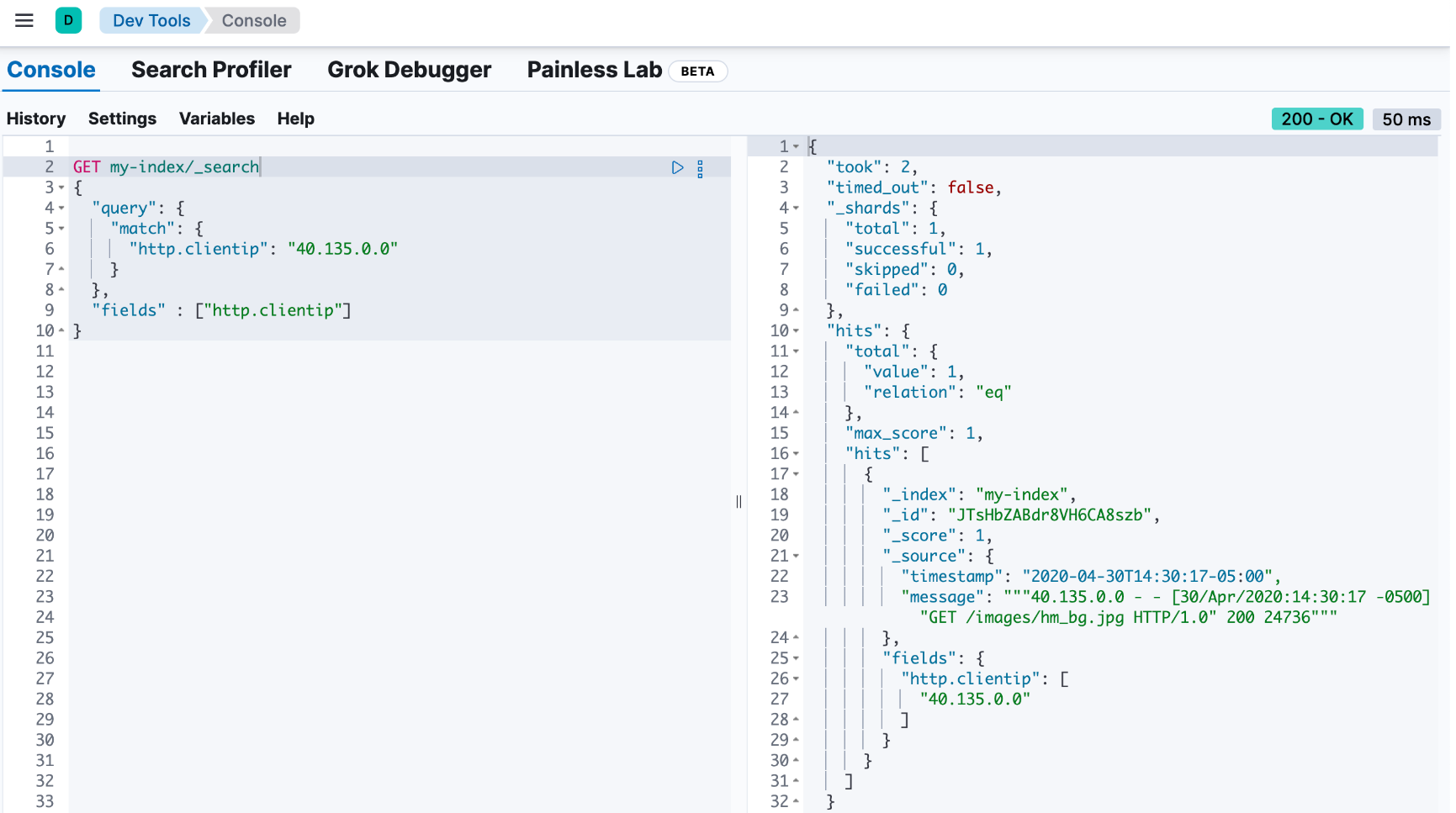
响应包括 http.clientip 的值与 40.135.0.0 匹配的文档。
解析字符串以提取字段的一部分(dissect)
你可以定义 dissect 模式来包含要丢弃的字符串部分,而不是像上例中那样匹配日志模式。
例如,本节开头的日志数据包含一个 message 字段。该字段包含几部分数据:
"message" : "247.37.0.0 - - [30/apr/2020:14:31:22 -0500] \"get /images/hm_nbg.jpg http/1.0\" 304 0"
你可以在运行时字段中定义一个 dissect 模式来提取 http 响应代码,在前面的示例中为 304。
put my-index/_mappings
{
"runtime": {
"http.response": {
"type": "long",
"script": """
string response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} http/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;
if (response != null) emit(integer.parseint(response));
"""
}
}
}
然后,你可以运行查询以使用 http.response 运行时字段检索特定的 http 响应:
get my-index/_search
{
"query": {
"match": {
"http.response": "304"
}
},
"fields" : ["http.response"]
}
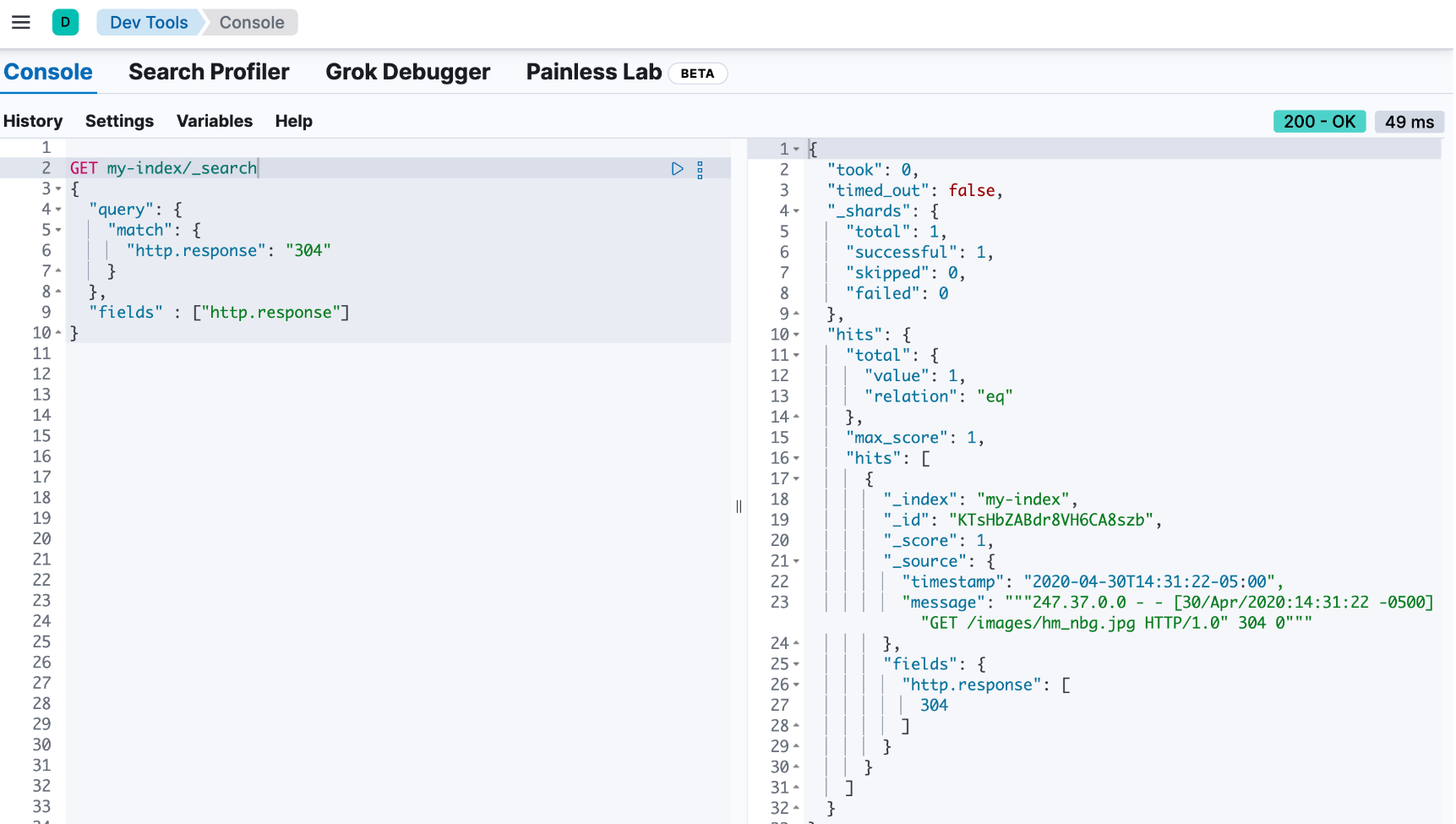
响应包含一个文档,其中 http 响应为 304。
使用分隔符拆分字段中的值(dissect)
假设你想要提取字段的一部分(如上例所示),但想要按特定值进行拆分。你可以使用分解模式仅提取所需的信息,并以特定格式返回该数据。
例如,假设你有一堆来自 elasticsearch 的 garbage collection (gc) 日志数据,格式如下:
[2021-04-27t16:16:34.699+0000][82460][gc,heap,exit] class space used 266k, capacity 384k, committed 384k, reserved 1048576k
你只想提取 used、capacity 和 commited 数据以及相关值。让我们索引一些包含日志数据的文档以用作示例:
delete my-index
post /my-index/_bulk?refresh
{"index":{}}
{"gc": "[2021-04-27t16:16:34.699+0000][82460][gc,heap,exit] class space used 266k, capacity 384k, committed 384k, reserved 1048576k"}
{"index":{}}
{"gc": "[2021-03-24t20:27:24.184+0000][90239][gc,heap,exit] class space used 15255k, capacity 16726k, committed 16844k, reserved 1048576k"}
{"index":{}}
{"gc": "[2021-03-24t20:27:24.184+0000][90239][gc,heap,exit] metaspace used 115409k, capacity 119541k, committed 120248k, reserved 1153024k"}
{"index":{}}
{"gc": "[2021-04-19t15:03:21.735+0000][84408][gc,heap,exit] class space used 14503k, capacity 15894k, committed 15948k, reserved 1048576k"}
{"index":{}}
{"gc": "[2021-04-19t15:03:21.735+0000][84408][gc,heap,exit] metaspace used 107719k, capacity 111775k, committed 112724k, reserved 1146880k"}
{"index":{}}
{"gc": "[2021-04-27t16:16:34.699+0000][82460][gc,heap,exit] class space used 266k, capacity 367k, committed 384k, reserved 1048576k"}
再次查看数据,有一个时间戳,一些你不感兴趣的其他数据,然后是 used、capacity 和 commited 数据:
[2021-04-27t16:16:34.699+0000][82460][gc,heap,exit] class space used 266k, capacity 384k, committed 384k, reserved 1048576k
你可以在 gc 字段中为数据的每个部分分配变量,然后仅返回所需的部分。花括号 {} 中的任何内容都被视为变量。例如,变量 [%{@timestamp}][%{code}][%{desc}] 将匹配前三个数据块,它们都在方括号 [] 中。
[%{@timestamp}][%{code}][%{desc}] %{ident} used %{usize}, capacity %{csize}, committed %{comsize}, reserved %{rsize}
你的分解模式可以包含 used 术语、capacity 和 commited 术语,而不是使用变量,因为你希望准确返回这些术语。你还可以将变量分配给要返回的值,例如 %{usize}、%{csize} 和 %{comsize}。日志数据中的分隔符是逗号,因此你的 dissect 模式也需要使用该分隔符。
现在你有了 dissect 模式,可以将其作为运行时字段的一部分包含在 painless 脚本中。该脚本使用你的 dissect 模式拆分 gc 字段,然后准确返回 emit 方法定义的所需信息。由于分解使用简单的语法,因此你只需准确告诉它你想要什么。
以下模式告诉分解返回 used 术语、空格、gc.usize 的值和逗号。此模式重复用于你要检索的其他数据。虽然此模式在生产中可能不那么有用,但它提供了很大的灵活性来试验和操作你的数据。在生产设置中,你可能只想使用 emit(gc.usize),然后聚合该值或在计算中使用它。
emit("used" + ' ' + gc.usize + ', ' + "capacity" + ' ' + gc.csize + ', ' + "committed" + ' ' + gc.comsize)
综上所述,你可以在搜索请求中创建一个名为 gc_size 的运行时字段。使用 fields 选项,你可以检索 gc_size 运行时字段的所有值。此查询还包括一个用于对数据进行分组的 bucket 聚合。
get my-index/_search
{
"runtime_mappings": {
"gc_size": {
"type": "keyword",
"script": """
map gc=dissect('[%{@timestamp}][%{code}][%{desc}] %{ident} used %{usize}, capacity %{csize}, committed %{comsize}, reserved %{rsize}').extract(doc["gc.keyword"].value);
if (gc != null) emit("used" + ' ' + gc.usize + ', ' + "capacity" + ' ' + gc.csize + ', ' + "committed" + ' ' + gc.comsize);
"""
}
},
"size": 1,
"aggs": {
"sizes": {
"terms": {
"field": "gc_size",
"size": 10
}
}
},
"fields" : ["gc_size"]
}
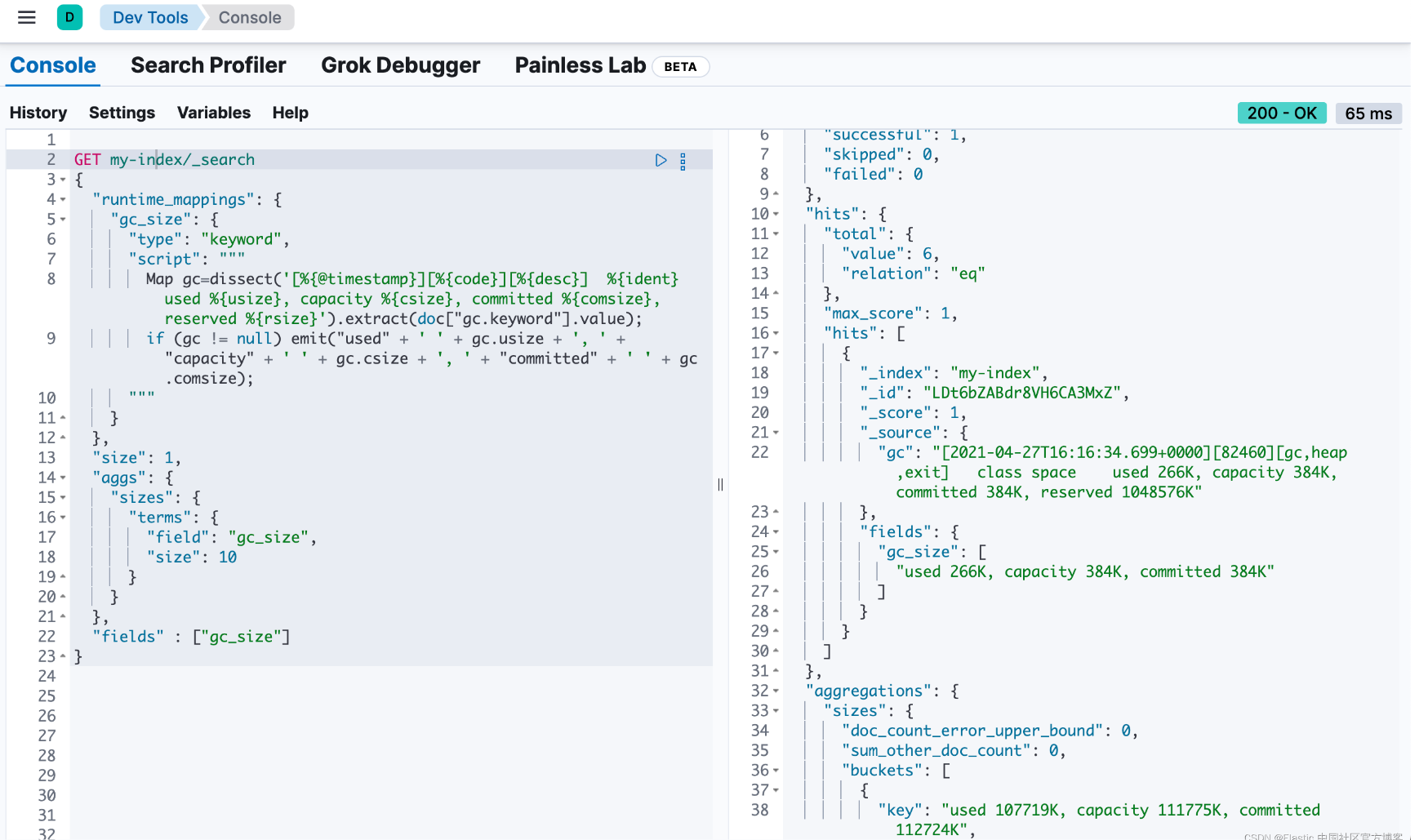
响应包括来自 gc_size 字段的数据,其格式与你在 dissect 模式中定义的格式完全一致!
访问文档字段和特殊变量
根据脚本的使用位置,它将可以访问某些特殊变量和文档字段。
更新脚本
在 update、update-by-query 或 reindex api 中使用的脚本将可以访问 ctx 变量,该变量公开:
| 条目 | 描述 |
|---|---|
| ctx._source | 访问文档的 _source 字段 |
| ctx.op | 应对文档应用的操作:index 或 delete。 |
ctx._index etc |
访问文档元数据字段,其中一些可能是只读的。 |
这些脚本无法访问 doc 变量,而必须使用 ctx 来访问它们操作的文档。
搜索和聚合脚本
除了每次搜索命中执行一次的 script fields 外,搜索和聚合中使用的脚本将针对可能与查询或聚合匹配的每个文档执行一次。根据你拥有的文档数量,这可能意味着数百万或数十亿次执行:这些脚本需要快速运行!
可以使用 doc-values、_source 字段或 stored fields 从脚本访问字段值,下面将对每个字段进行解释。
在脚本中访问文档的分数
function_score 查询、基于脚本的排序或聚合中使用的脚本可以访问 _score 变量,该变量表示文档的当前相关性分数。
以下是在 function_score 查询中使用脚本更改每个文档的相关性 _score 的示例:
put my-index-000001/_doc/1?refresh
{
"text": "quick brown fox",
"popularity": 1
}
put my-index-000001/_doc/2?refresh
{
"text": "quick fox",
"popularity": 5
}
get my-index-000001/_search
{
"query": {
"function_score": {
"query": {
"match": {
"text": "quick brown fox"
}
},
"script_score": {
"script": {
"lang": "expression",
"source": "_score * doc['popularity']"
}
}
}
}
}
doc values
到目前为止,从脚本访问字段值的最快、最有效的方法是使用 doc['field_name'] 语法,该语法从 doc values 中检索字段值。doc values 是列式字段值存储,默认情况下在除已分析的 text 字段之外的所有字段上启用。
put my-index-000001/_doc/1?refresh
{
"cost_price": 100
}
get my-index-000001/_search
{
"script_fields": {
"sales_price": {
"script": {
"lang": "expression",
"source": "doc['cost_price'] * markup",
"params": {
"markup": 0.2
}
}
}
}
}
doc-values 只能返回 “简单” 字段值,如数字、日期、地理点、术语等,如果字段是多值的,则返回这些值的数组。它不能返回 json 对象。
文档 _source
可以使用 _source.field_name 语法访问文档 _source。_source 以映射的映射形式加载,因此可以以例如 _source.name.first 的形式访问对象字段内的属性。
例如:
put my-index-000001
{
"mappings": {
"properties": {
"first_name": {
"type": "text"
},
"last_name": {
"type": "text"
}
}
}
}
put my-index-000001/_doc/1?refresh
{
"first_name": "barry",
"last_name": "white"
}
get my-index-000001/_search
{
"script_fields": {
"full_name": {
"script": {
"lang": "painless",
"source": "params._source.first_name + ' ' + params._source.last_name"
}
}
}
}
stored fields
存储字段(在映射中明确标记为 “store”:true 的字段)可以使用 _fields['field_name'].value 或 _fields['field_name'] 语法访问:
put my-index-000001
{
"mappings": {
"properties": {
"full_name": {
"type": "text",
"store": true
},
"title": {
"type": "text",
"store": true
}
}
}
}
put my-index-000001/_doc/1?refresh
{
"full_name": "alice ball",
"title": "professor"
}
get my-index-000001/_search
{
"script_fields": {
"name_with_title": {
"script": {
"lang": "painless",
"source": "params._fields['title'].value + ' ' + params._fields['full_name'].value"
}
}
}
}
脚本和安全
painless 和 elasticsearch 实施了多层安全措施,以构建纵深防御策略,从而安全地运行脚本。
painless 使用细粒度的允许列表。任何不属于允许列表的内容都会导致编译错误。此功能是脚本纵深防御策略中的第一层安全措施。
第二层安全措施是 java 安全管理器。作为启动序列的一部分,elasticsearch 启用 java 安全管理器来限制部分代码可以执行的操作。painless 使用 java 安全管理器作为额外的防御层,以防止脚本执行诸如写入文件和监听套接字之类的操作。
elasticsearch 在 linux 中使用 seccomp,在 macos 中使用 seatbelt,在 windows 上使用 activeprocesslimit 作为额外的安全层,以防止 elasticsearch 分叉或运行其他进程。
你可以修改以下脚本设置以限制允许运行的脚本类型,并控制脚本可以在其中运行的可用 contexts。要在纵深防御策略中实施额外的层,请遵循 elasticsearch 安全原则。
允许的脚本类型设置
elasticsearch 支持两种脚本类型:inline 和 stored。默认情况下,elasticsearch 配置为运行这两种类型的脚本。要限制运行的脚本类型,请将 script.allowed_types 设置为 inline 或 stored。要阻止任何脚本运行,请将 script.allowed_types 设置为 none。
例如,要运行 inline 脚本但不运行存储脚本:
script.allowed_types: inline
允许的脚本上下文设置
默认情况下,所有脚本上下文(contexts)都是允许的。使用 script.allowed_contexts 设置指定允许的上下文。要指定不允许任何上下文,请将 script.allowed_contexts 设置为 none。
例如,要允许脚本仅在 scoring 和 update 上下文中运行:
script.allowed_contexts: score, update






发表评论