在数据科学的众多领域中,聚类算法无疑是探索数据集内在结构的强大工具。本文将带您深入了解如何应用主成分分析(pca)进行降维,以及如何使用k-means和dbscan这两种流行的聚类算法,来揭示数据的隐藏模式。
一、pca降维:理论到实践
在处理高维数据时,直观理解数据结构往往是一个挑战。这时,pca就显得尤为重要。pca是一种降维技术,能够将数据从原始的高维空间转换到低维空间,同时尽可能保留数据的变异性。
实践步骤:
- 导入必要的库:首先,我们需要导入
pandas用于数据处理,numpy进行数值计算,以及sklearn.decomposition中的pca。 - 标准化数据:pca对数据的规模非常敏感,因此在应用pca之前,先使用
sklearn.preprocessing.standardscaler对数据进行标准化。 - 应用pca:接下来,实例化pca对象,选择合适的组件数量,然后对数据集进行拟合和转换。
二、k-means聚类:寻找数据的自然分组
k-means算法通过将数据点分配到k个簇中,使得簇内的数据点尽可能相似,簇间的数据点尽可能不同,从而发现数据的自然分组。
实践步骤:
- 选择k值:k是事先设定的簇的数量。
yellowbrick库的kelbowvisualizer可以帮助我们通过肘部法则选择一个合适的k值。 - 应用k-means:使用
sklearn.cluster.kmeans,根据选择的k值对数据进行聚类。 - 结果分析:分析各个簇的特征,以及簇中心,从而对数据进行解释。
三、dbscan聚类:基于密度的聚类方法
与k-means不同,dbscan不需要预先指定簇的数量。它通过识别被低密度区域分隔的高密度区域,来形成簇。
实践步骤:
- 参数设置:dbscan的主要参数是
eps和min_samples,分别代表搜索邻居的半径和形成密集区域所需的最小样本数。 - 应用dbscan:使用
sklearn.cluster.dbscan对数据应用dbscan算法。 - 结果分析:识别核心样本、边界点和噪声点,分析每个簇的特性。
数据可视化:理解聚类结果
无论是pca降维还是聚类,数据可视化都是理解结果的关键。matplotlib和seaborn提供了丰富的可视化工具,帮助我们深入理解数据集的潜在模式。
- pca结果可视化:通过绘制pca降维后的散点图,观察数据点在低维空间的分布。
- k-means聚类可视化:使用散点图显示不同簇的数据点,以及簇中心。
- dbscan结果可视化:标识出核心点、边界点和噪声点,理解数据的密度结构。
第一步,导入数据
以市场营销数据集为例,其中包含了客户的个人信息、购买行为以及对营销活动的响应。
每行代表一个客户,以下是每列的简要描述:
- id:客户的唯一标识符。
- year_birth:客户的出生年份。
- education:客户的教育水平(如graduation、phd等)。
- marital_status:客户的婚姻状况(如single、married、together等)。
- income:客户的年收入。
- kidhome:家中有小孩的数量。
- teenhome:家中有青少年的数量。
- dt_customer:客户首次成为公司客户的日期。
- recency:自客户最后一次购买以来的天数。
- mntwines:过去两年内购买葡萄酒的金额。
- 以下省略的列可能包括对其他产品类别的支出(如肉类、鱼类、甜品等),在线访问频次,以及对几轮特定营销活动的响应情况(如acceptedcmp1、acceptedcmp2等)。
- numwebvisitsmonth:过去一个月内访问公司网站的次数。
- acceptedcmp3、acceptedcmp4、acceptedcmp5、acceptedcmp1、acceptedcmp2:表示客户是否接受了第3、4、5、1、2轮的营销活动。
- complain:客户是否在最近两年内投诉过。
- z_costcontact、z_revenue:这两列的含义不太清楚,可能是与客户联系的成本和产生的收益相关的内部指标。
- response:客户对最近一次营销活动的响应(1表示接受,0表示未接受)。
data = pd.read_csv("data.csv")
print("number of datapoints:", len(data))
data.head()查看数据
id year_birth education marital_status income kidhome teenhome dt_customer recency mntwines ... numwebvisitsmonth acceptedcmp3 acceptedcmp4 acceptedcmp5 acceptedcmp1 acceptedcmp2 complain z_costcontact z_revenue response
0 5524 1957 graduation single 58138.0 0 0 04-09-2012 58 635 ... 7 0 0 0 0 0 0 3 11 1
1 2174 1954 graduation single 46344.0 1 1 08-03-2014 38 11 ... 5 0 0 0 0 0 0 3 11 0
2 4141 1965 graduation together 71613.0 0 0 21-08-2013 26 426 ... 4 0 0 0 0 0 0 3 11 0
3 6182 1984 graduation together 26646.0 1 0 10-02-2014 26 11 ... 6 0 0 0 0 0 0 3 11 0
4 5324 1981 phd married 58293.0 1 0 19-01-2014 94 173 palette = ["#ff6b6b", "#fdd835", "#1de9b6", "#81d4fa", "#b39ddb", "#ff8a65"]
to_plot = [ "income", "recency", "customer_for", "age", "spent", "is_parent"]
print("reletive plot of some selected features: a data subset")
# 绘制图形
plt.figure()
sns.pairplot(data[to_plot], hue="is_parent", palette=palette)
plt.show()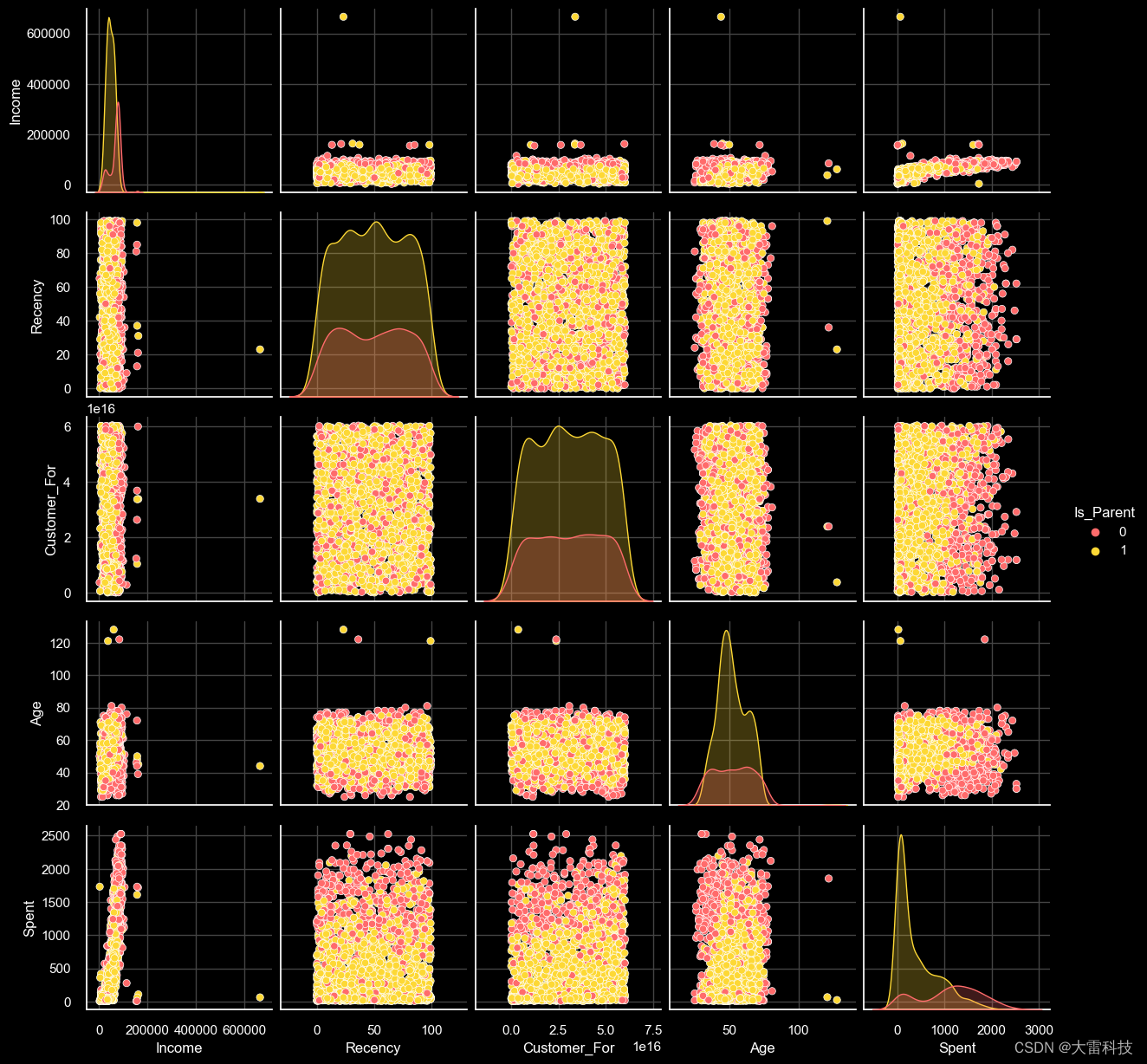
第二步,计算相关性矩阵
data_encoded = pd.get_dummies(data, drop_first=true)
# 计算相关性矩阵
corrmat = data_encoded.corr()
# 设置图形的风格和大小
plt.figure(figsize=(20, 20))
sns.heatmap(corrmat, annot=true, cmap='viridis', center=0)
# 显示图形
plt.show()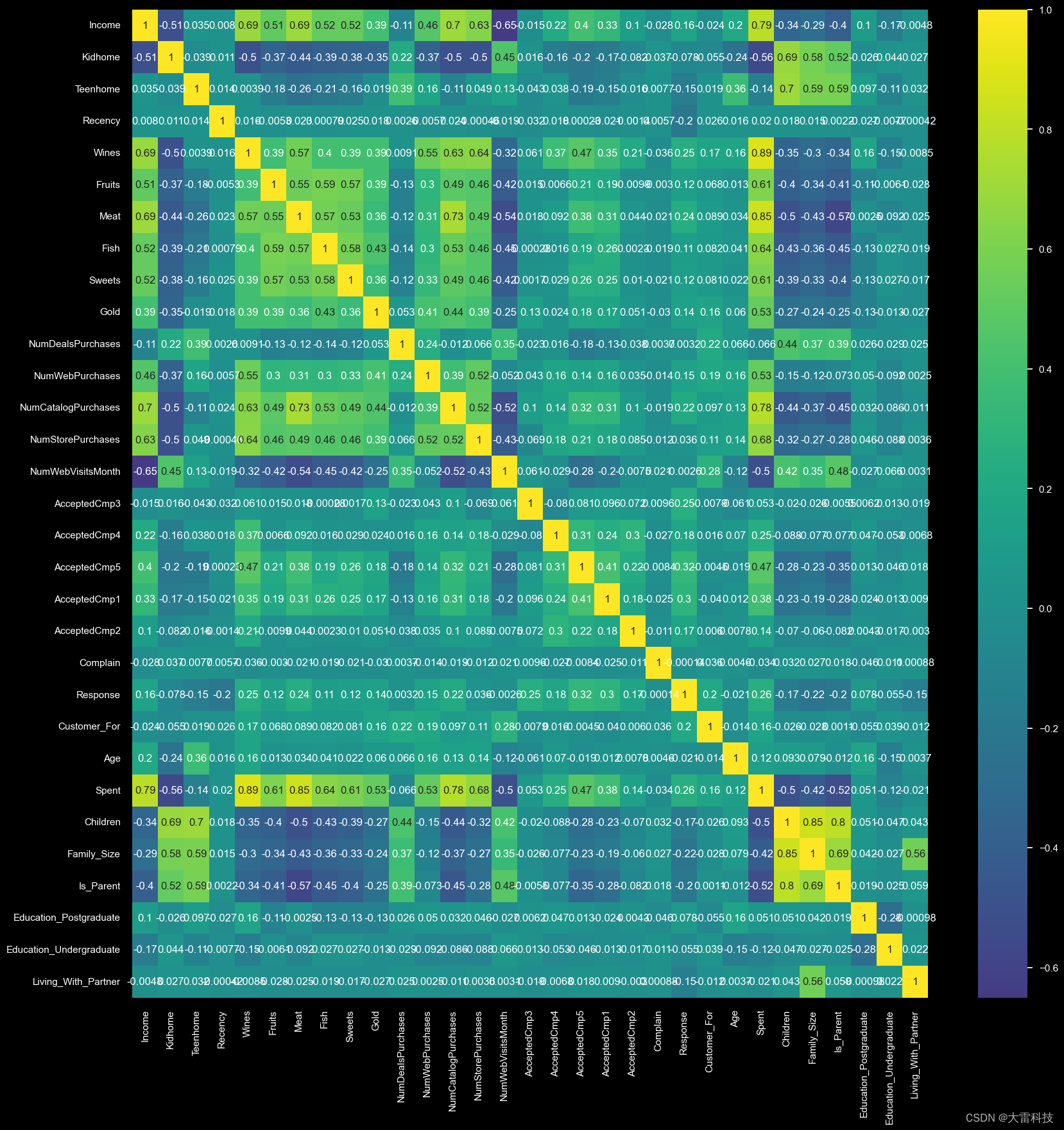
三步,pca降维
pca = pca(n_components=3)
pca.fit(scaled_ds)
pca_ds = pd.dataframe(pca.transform(scaled_ds), columns=(["col1","col2", "col3"]))
pca_ds.describe().t查看降维后的数据分布
x =pca_ds["col1"]
y =pca_ds["col2"]
z =pca_ds["col3"]
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection="3d")
ax.scatter(x,y,z, c="maroon", marker="o" )
ax.set_title("a 3d projection of data in the reduced dimension")
plt.show()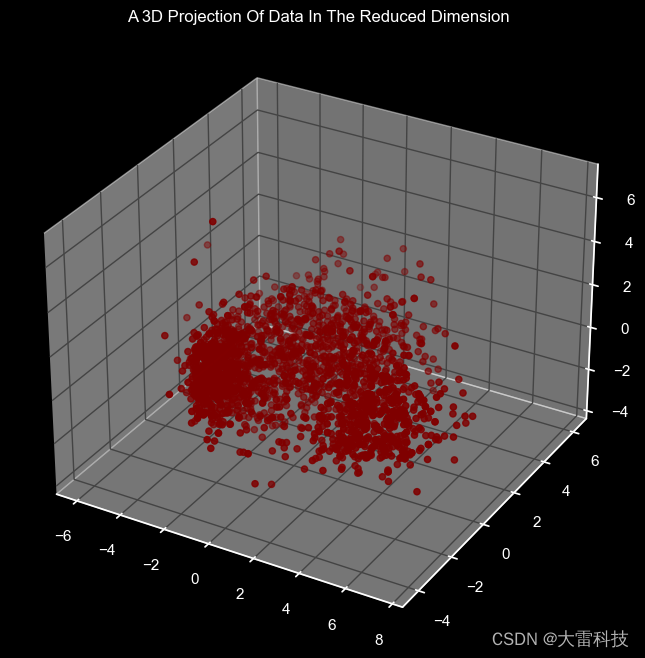
第四步,使用kelbowvisualizer计算需要聚类的种类
elbow_m = kelbowvisualizer(kmeans(), k=10)
elbow_m.fit(pca_ds)
elbow_m.show()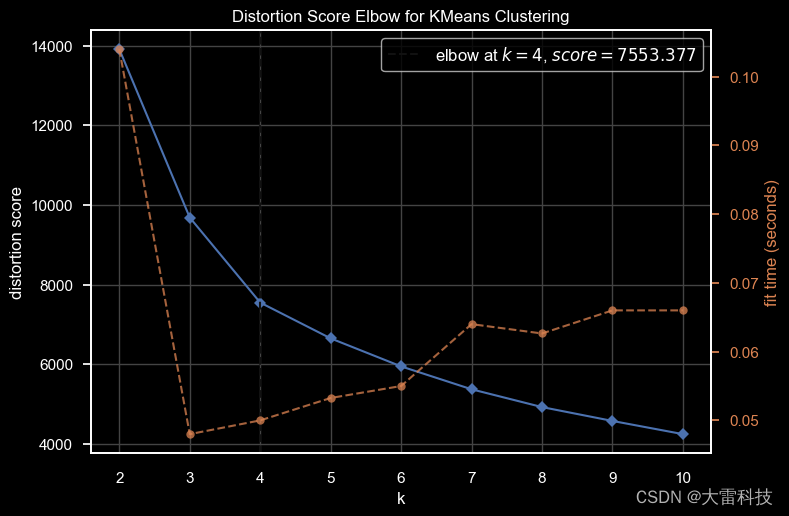
第五步,agglomerative聚类
ac = agglomerativeclustering(n_clusters=4)
yhat_ac = ac.fit_predict(pca_ds)
pca_ds["clusters"] = yhat_ac
data["clusters"]= yhat_ac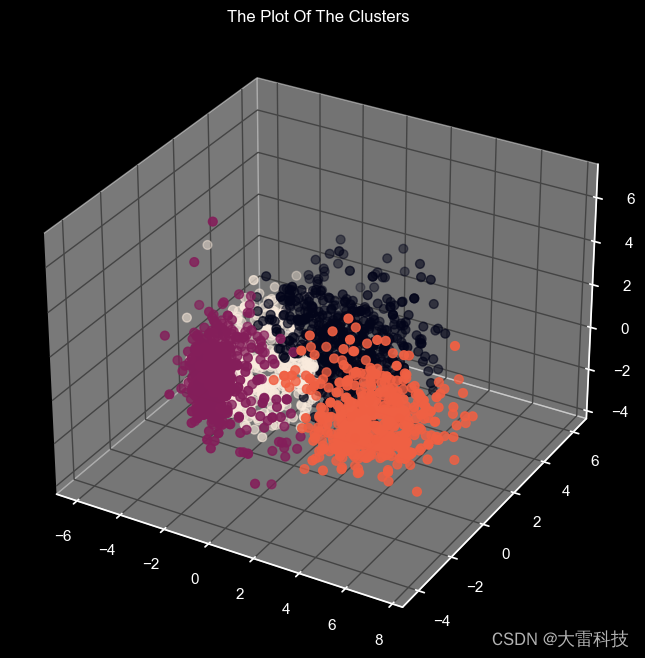
第六步,dbscan聚类
dbscan = dbscan(eps=0.5, min_samples=5)
dbscan_labels = dbscan.fit_predict(scaled_ds)
data['dbscan_cluster'] = dbscan_labels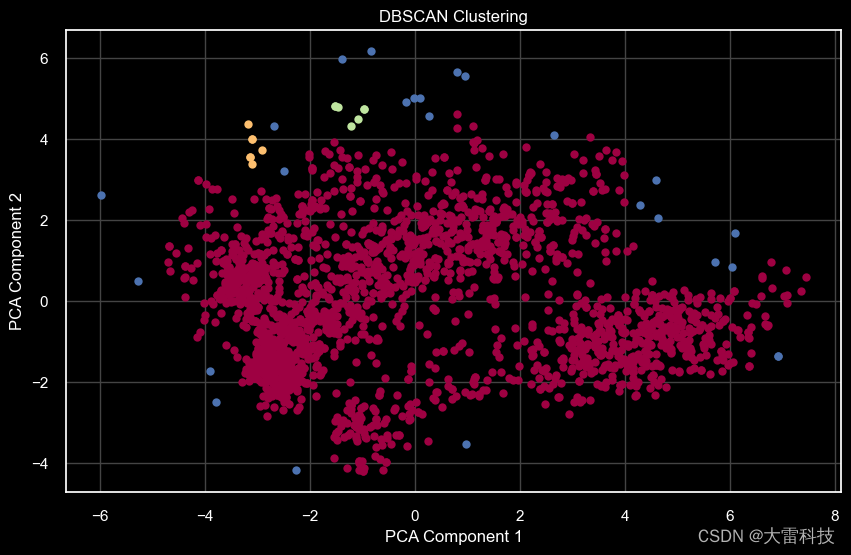
第七步,kmeans聚类
k = 5 # example number of clusters
kmeans = kmeans(n_clusters=k, random_state=42)
kmeans_labels = kmeans.fit_predict(scaled_ds)
centroids = kmeans.cluster_centers_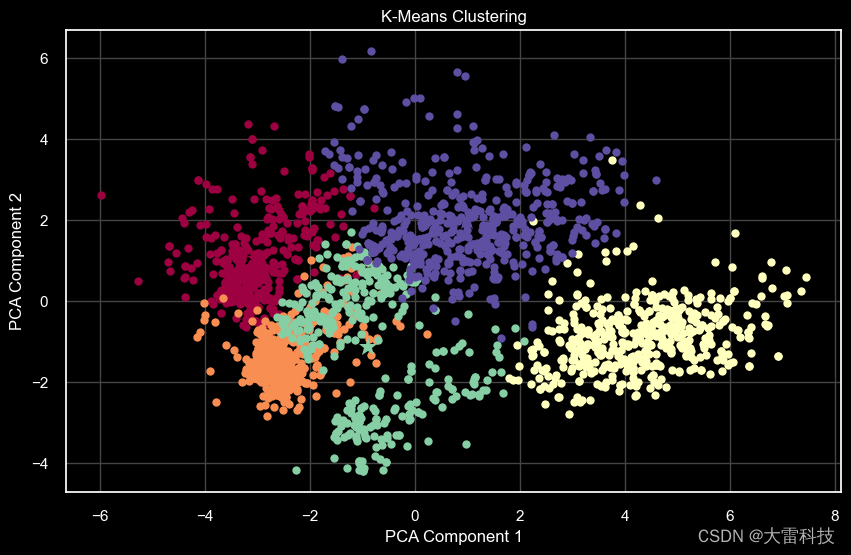




发表评论