1.前言
2.项目回顾
到目前为止,我们已经实现了2个类,parser和index。
实现parser类:
1.通过递归枚举出所有的html文件。
2.针对每一个html进行解析操作。
a)标题:直接使用文件名称
b)url:基于文件路径进行简单的字符串拼接
c)正文:去掉script和html标签
3.把解析内容通过adddoc放入index类中
实现index类:
正排索引:arraylist
倒排索引:hashmap<string,arraylist>
1.查正排:直接按照下标来取arraylist中的元素
2.查倒排:直接按照key,来区hashmap中的元素
3.添加文档,供parser类调用
a)构建正排索引,构造docinfo对象,添加到索引末尾
b)构建倒排索引,先对标题,正文进行分词操作,统计词频,添加到map中去
4.保存索引:基于json格式把索引数据保存到指定文件中。
5.加载索引:基于json格式对数据进行解析,存入内存。
3.搜索流程
- 1.【分词】根据输入内容进行分词操作
- 2.【触发】针对分词结果来查倒排
- 3.【去重】针对相同的文档进行去重
- 4.【排序】针对去重结果按照权重排序
- 5.【包装】针对排序结果查正牌,包装为result进行返回数据
3.1分词
在使用ansj技术进行分词操作的时候,会把空格,以及一些高频词例如a,an,is 等词语都分出来,但这些词语和我们的查询内容关联性并不大,我们就单独罗列出来,进行排除。网上有许多暂停词表可以自行下载,例如:
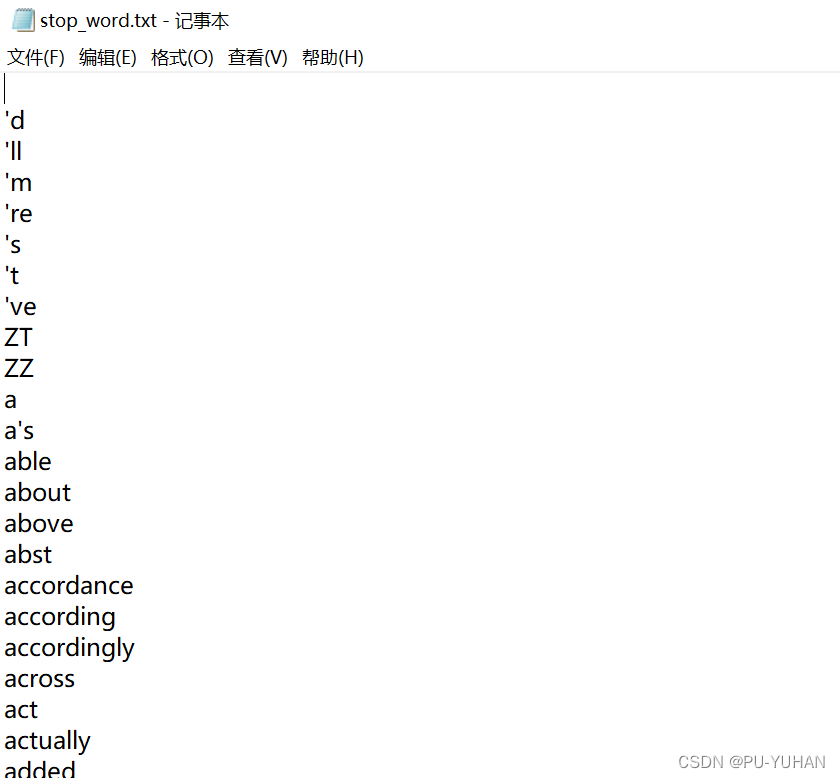
private static string stop_word_path="d:/doc_searcher_index/stop_word.txt";
private hashset<string> stopwords=new hashset<>();
public docsearcher(){
index.load();
loadstopwords();
}
public void loadstopwords(){
try (bufferedreader bufferedreader=new bufferedreader(new filereader(stop_word_path))){
while (true){
string line=bufferedreader.readline();
if (line==null){
break;
}
stopwords.add(line);
}
} catch (ioexception e) {
throw new runtimeexception(e);
}
}
list<term> oldterms=toanalysis.parse(query).getterms();
list<term> terms=new arraylist<>();
for (term term:oldterms){
if (stopwords.contains(term.getname())){
continue;
}
terms.add(term);
}
3.2触发
list<list<weight>> termresult=new arraylist<>();
for (term term:terms){
string word=term.getname();
list<weight> invertedlist=index.getinverted(word);
if (invertedlist==null){
continue;
}
termresult.add(invertedlist);
}
3.3去重
前面,我们对用户输入的结果进行触发操作的时候,一个词可能出现在多个文档中,同理,一个文档也可能存在多个分词结果,如果我们不对相同的文档进行去重,那么一个文档针对不同的分词结果就会出现多次,这样显然不合理的。索引我们需要对相同的文档进行去重。那么具体该如何操作呢?触发的结果是一个二维数组,可以利用两个有序数组排序的思想进行去重,只不过这里运用的是多个有序数组排序。
- 1.针对每一行按照升序排序
- 2.借助优先级队列,争对多个有序数组进行合并
- 3.初始化队列,把每一行第一个元素放入队列
- 4.循环的取每行首个元素,遇到相同的docid,权重相加
list<weight> alltermresult=mergeresult(termresult);
static class pos{
public int row;
public int col;
public pos(int row, int col) {
this.row = row;
this.col = col;
}
}
private list<weight> mergeresult(list<list<weight>> source) {
//1.针对每一行按照升序排序
for (list<weight> currow:source){
currow.sort(new comparator<weight>() {
@override
public int compare(weight o1, weight o2) {
return o1.getdocid()-o2.getdocid();
}
});
}
//2.借助优先级队列,争对多个有序数组进行合并
list<weight> target=new arraylist<>();
priorityqueue<pos> queue=new priorityqueue<>(new comparator<pos>() {
@override
public int compare(pos o1, pos o2) {
weight w1=source.get(o1.row).get(o1.col);
weight w2=source.get(o2.row).get(o2.col);
return w1.getdocid()-w2.getdocid();
}
});
//3.初始化队列,把每一行第一个元素放入队列
for (int row=0;row<source.size();row++){
queue.offer(new pos(row,0));
}
//循环的取每行首个元素
while (!queue.isempty()){
pos minpos=queue.poll();
weight curweight=source.get(minpos.row).get(minpos.col);
if (target.size()>0){
weight lastweight=target.get(target.size()-1);
//遇到相同的文章,权重相加
if (lastweight.getdocid()==curweight.getdocid()){
lastweight.setweight(lastweight.getweight()+curweight.getweight());
}else {
target.add(curweight);
}
}else {
target.add(curweight);
}
pos newpos=new pos(minpos.row,minpos.col+1);
if (newpos.col>=source.get(newpos.row).size()){
continue;
}
queue.offer(newpos);
}
return target;
}
3.4排序
alltermresult.sort(new comparator<weight>() {
@override
public int compare(weight o1, weight o2) {
//按照降序排序
return o2.getweight()-o1.getweight();
}
});
3.5包装
需要注意的是返回的结果为标题,url,描述,而描述不能直接把正文返回,而是返回一段包含用户分词结果的一小段描述。生成描述的思路:可以回去到所有分词结果,遍历分词结果,看哪个结果在正文中出现,那么直接截取分词的前10个字符和后160个字符来进行描述。
public class result {
private string title;
private string url;
private string desc;
@override
public string tostring() {
return "result{" +
"title='" + title + '\'' +
", url='" + url + '\'' +
", desc='" + desc + '\'' +
'}';
}
public string gettitle() {
return title;
}
public void settitle(string title) {
this.title = title;
}
public string geturl() {
return url;
}
public void seturl(string url) {
this.url = url;
}
public string getdesc() {
return desc;
}
public void setdesc(string desc) {
this.desc = desc;
}
}
list<result> results=new arraylist<>();
for (weight weight:alltermresult){
docinfo docinfo=index.getdocinfo(weight.getdocid());
result result=new result();
result.settitle(docinfo.gettitle());
result.seturl(docinfo.geturl());
result.setdesc(gendesc(docinfo.getcontent(),terms));
results.add(result);
}
private string gendesc(string content, list<term> terms) {
int firstpos=-1;
for (term term:terms){
string word=term.getname();
//避免出现word前后带有标点符号
content=content.tolowercase().replaceall("\\b"+word+"\\b"," "+word+" ");
firstpos=content.indexof(" "+word+" ");
if (firstpos>=0){
break;
}
}
if (firstpos==-1){
if (content.length()>160){
return content.substring(0,160)+"...";
}
return content;
}
string desc="";
int descbeg=firstpos<60?0:firstpos-60;
if (descbeg+160>content.length()){
desc=content.substring(descbeg);
}else {
desc=content.substring(descbeg,descbeg+160)+"...";
}
//把描述中和分词结果相同的部分设置为斜体加上<i>标签,方便前端标红
for (term term:terms){
string word=term.getname();
//进行忽略大小写的全词匹配
desc=desc.replaceall("(?i) "+word+" ","<i> "+word+" </i>");
}
return desc;
}
4.总结
下期预告:搜索引擎(四)



发表评论