数据同步在业务开发中比较普遍,例如 订阅mysql的binlog将数据同步至异构数据库。数据同步方案需要考虑一下几点:
- 数据实时性要求
- 数据量级
- 是否有数据转换逻辑
可分为两种模式
- 发布订阅模式:分为订阅数据库log还是订阅应用层发的消息
- 点对点模式:分为推和拉
以下讨论几种比较通用的方法:
- 日志订阅:订阅数据生产方库表日志,如mysql的binlog
- 双写:数据生产方应用层双写,直接写入数据消费方或写入mq
- 定时批量select:基于updatetime等字段定时批量推送/拉取数据
同时,数据同步会存在以下几个普遍问题:
- 延迟
- 写放大
日志订阅
订阅db的日志,如mysql的binlog,进行数据同步,其他的异构数据源均以db数据作为 source-of-truth。
该方法实现了应用层的解耦,但系统复杂度增加。
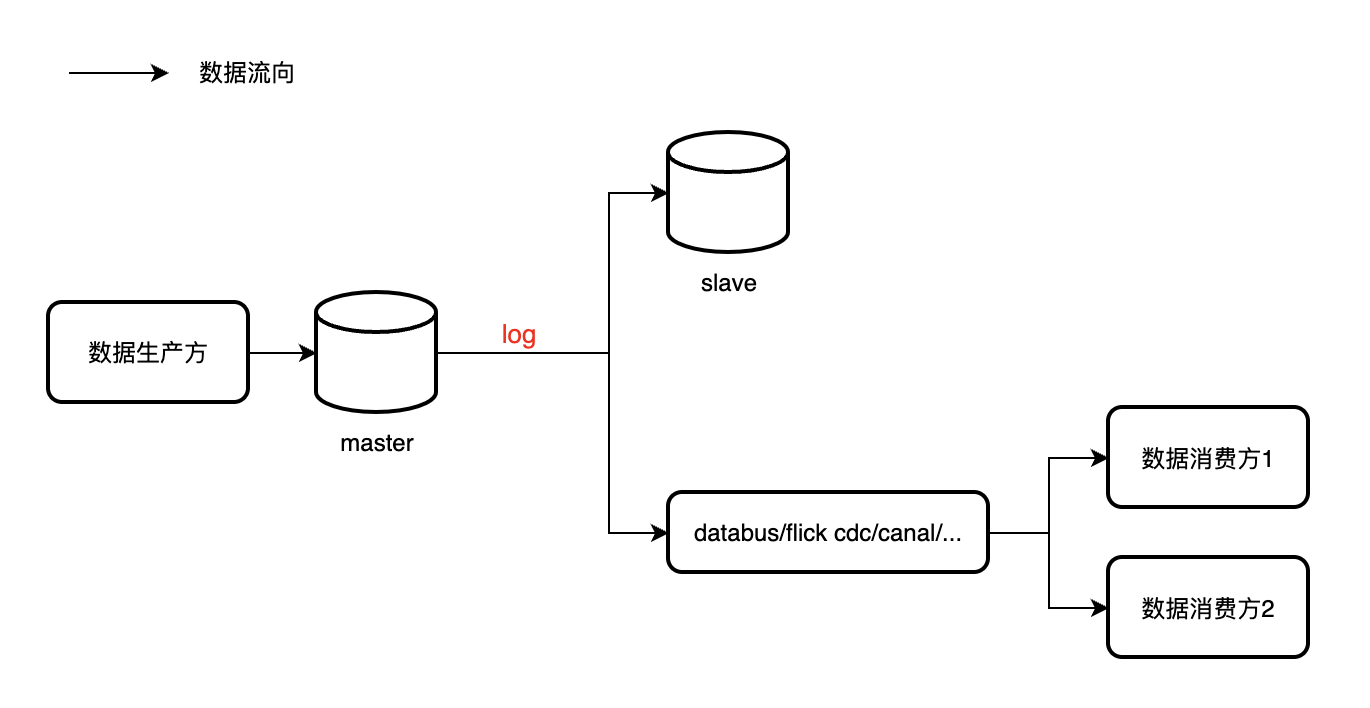
mysql 主从同步
同步进度跟踪方式分为:
- binary log based replication
- global transaction identifiers (gtids) based replication
同步ack策略分为:
- one way (asynchronous) replication
- semi-synchronous replication
- delayed replication
同步数据格式:
- statement based replication (sbr)
- row based replication (rbr)
- mixed based replication (mbr)
主从同步同步数据格式一般为row based,同步ack策略根据从库读写要求,一般主库备库设为semi-sync方式,其他ro库、大数据抽数库设为one way sync。
日志订阅中间件
databus, flink cdc, canal
数据同步工具之flinkcdc/canal/debezium对比
双写
在应用层执行数据落库之后可以进行数据同步操作,比如直接调数据接口、发mq消息。
该方法实现简单、灵活性高, 但数据不一致的风险增加,需要配合巡检任务等兜底校验来减小不一致对业务的影响。
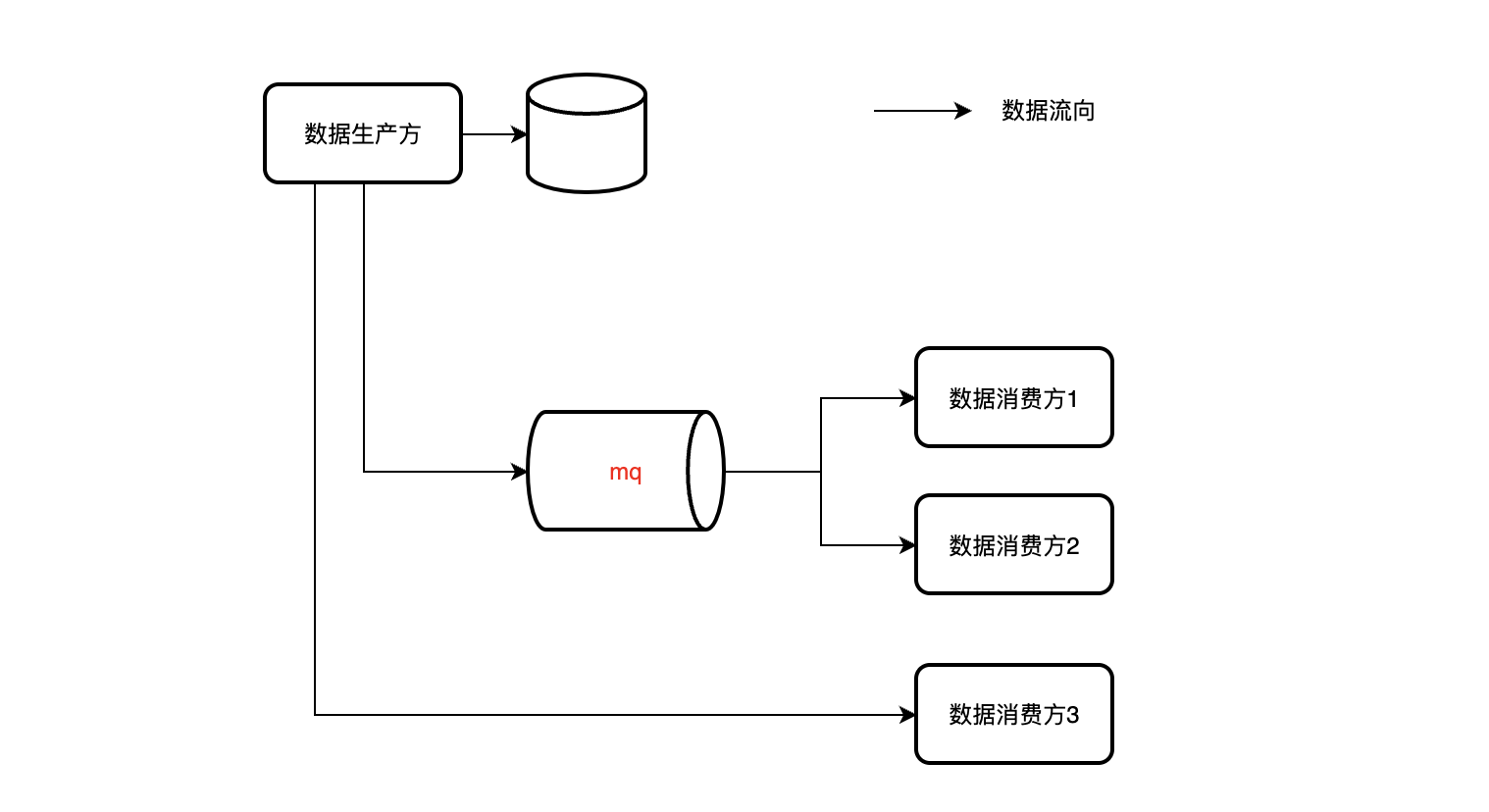
消息订阅
rocketmq kafka …
本地消息表
基于本地消息表确保业务数据落库和消息发送的原子性,开源组件可参考spring-tx-message
spring event扩展点
基于spring event实现双写
mybatis 拦截器
基于 mybatis interceptor实现双写
定时批量select
数据消费方可以定时拉取数据生产方的数据,批量导入消费方的本地库。
该方法同样可以自定义条件拉取数据并做逻辑转换,相当于定时etl。
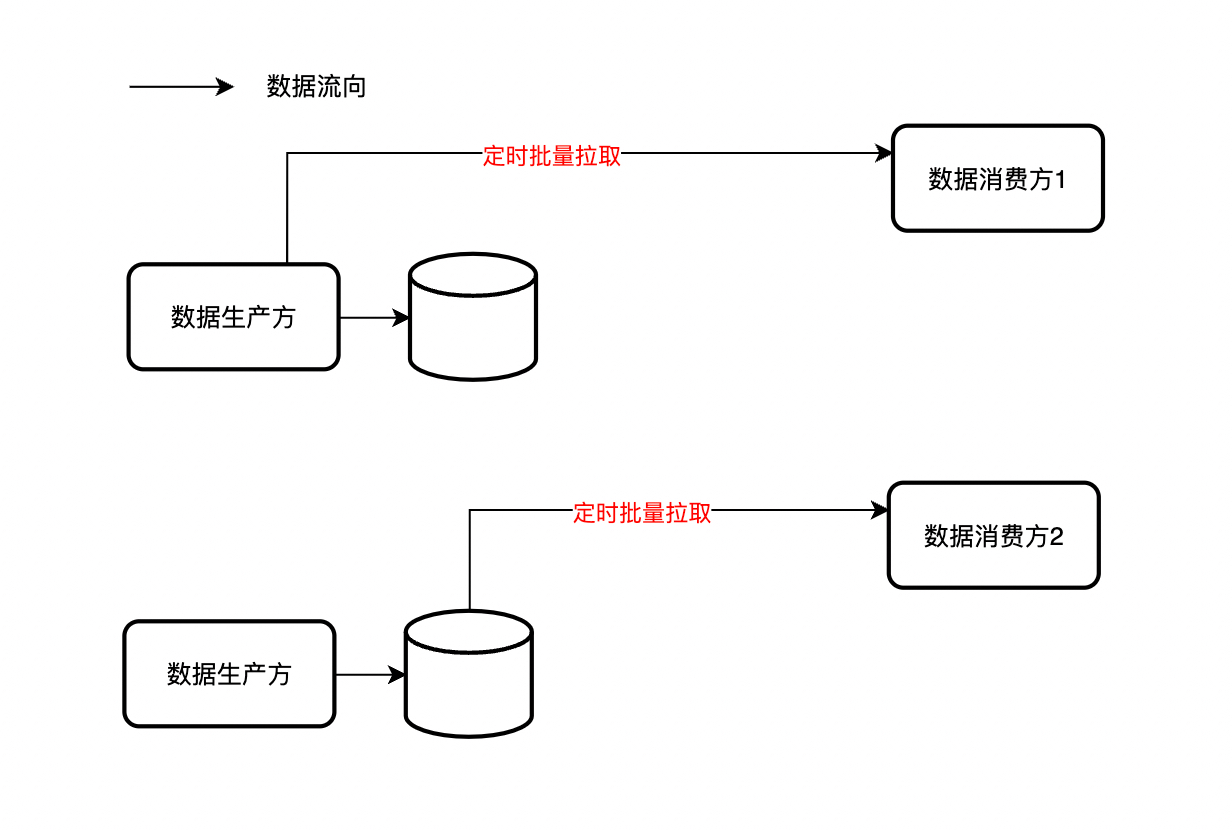
定时任务
xxl-job elasticjob
任务执行需要保证幂等
批量
spring batch
同步延迟
同步延迟无法避免,在使用同步时需要考虑场景,强一致要求的场景还是得读数据源头。
此外,可以通过一些妥协避免延迟带来的业务影响,比如:前端调写库接口,写库后需要将数据同步到es,es本身也是准实时的(写入后1s内能查到),如果前端写完返回成功直接读后台接口,后台接口在es查不到数据,就很奇怪。这时可以在前端写完后转圈圈1~2s,用户体验不会差,同时极大程度减小同步延迟带来的影响。
写放大
微批处理,根据业务主键只写最新数据


发表评论