声明:
1. 本文针对的是一个知识的梳理,自行整理以及方便记忆
2. 若有错误不当之处, 请指出
scala是一种针对jvm 将面向函数和面向对象技术组合在一起的编程语言。scala编程语言近来抓住了很多开发者的眼球。它看起来像是一种纯粹的面向对象编程语言,而又无缝地结合了命令式和函数式的编程风格。
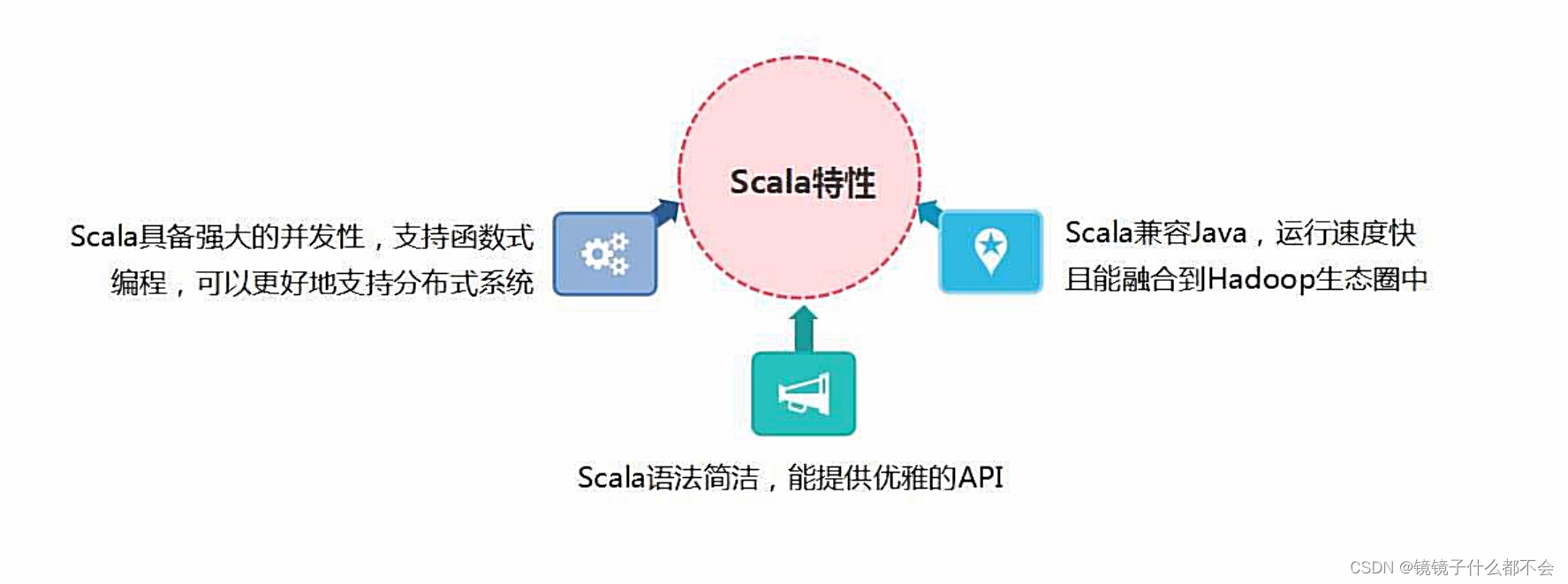
scala官网6个特征:
1).java和scala可以混编
2).类型推测(自动推测类型)
3).并发和分布式
4).特质,特征(类似java中interfaces 和 abstract结合)
5).模式匹配(类似java switch)
6).高阶函数
scala有个原则就是极简原则,不用写的东西一概不写。


scala的基本操作具体参考:scala快速入门(适用于学习spark)_scala spark-csdn博客
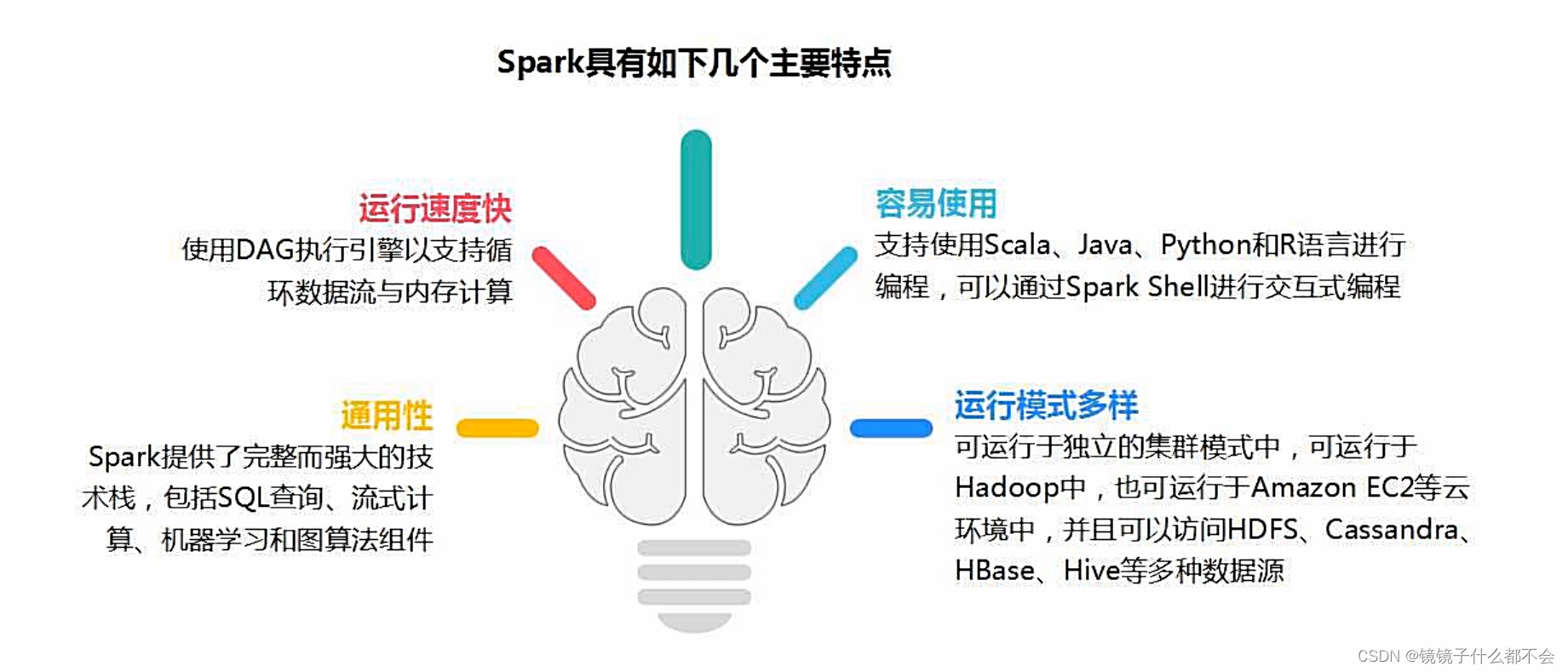
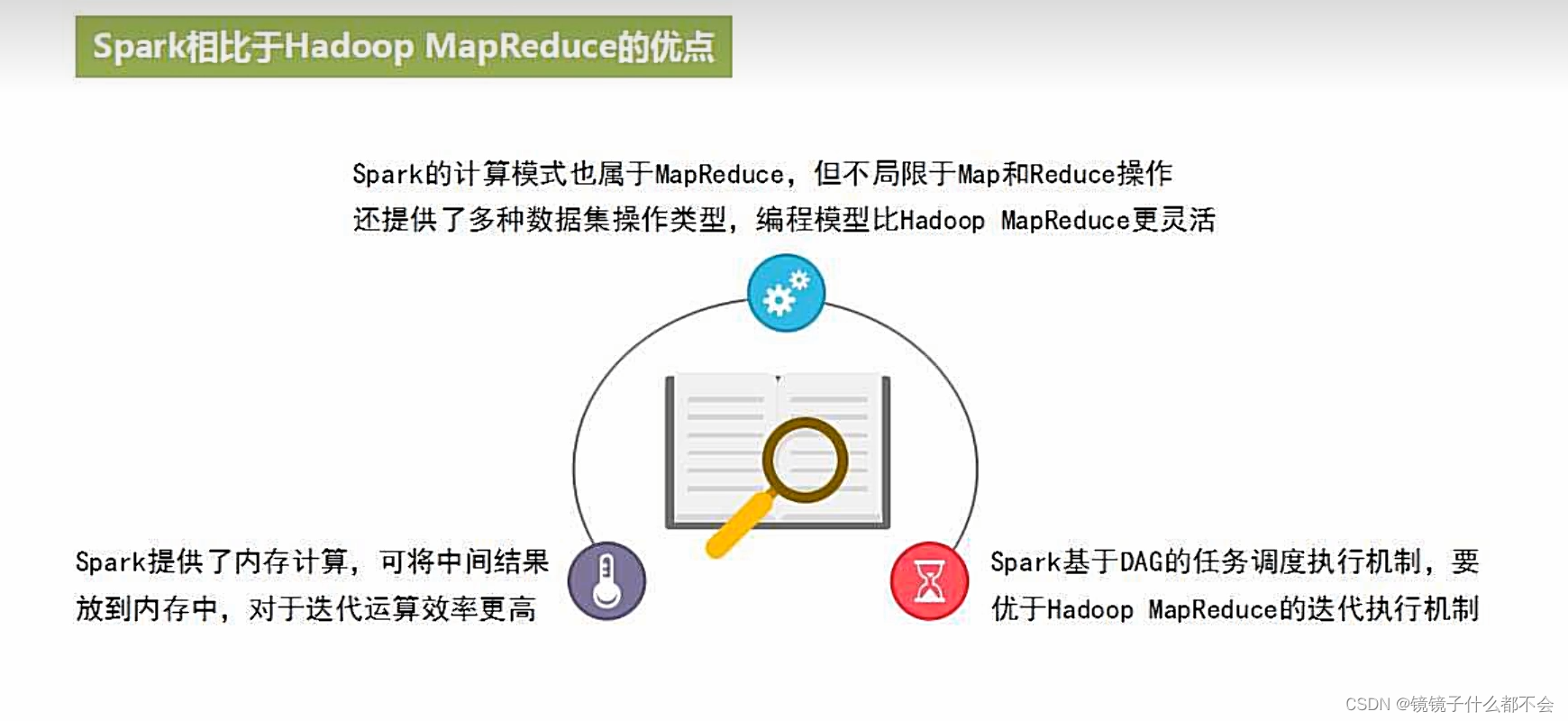
spark的特点:快速,易用,通用,随处运行
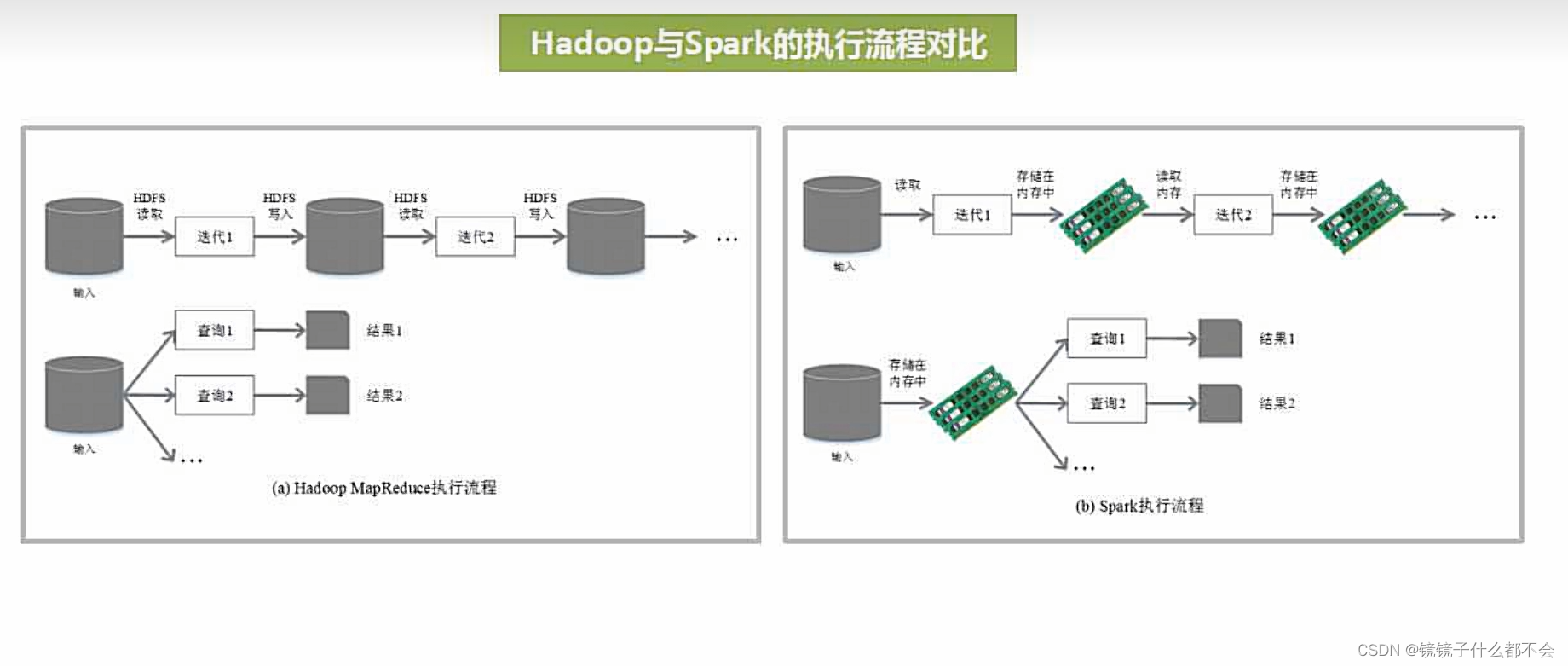
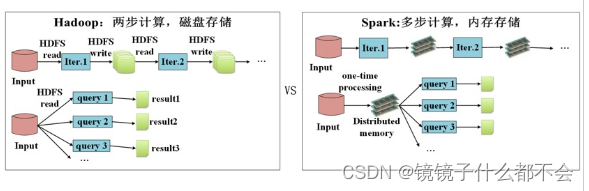
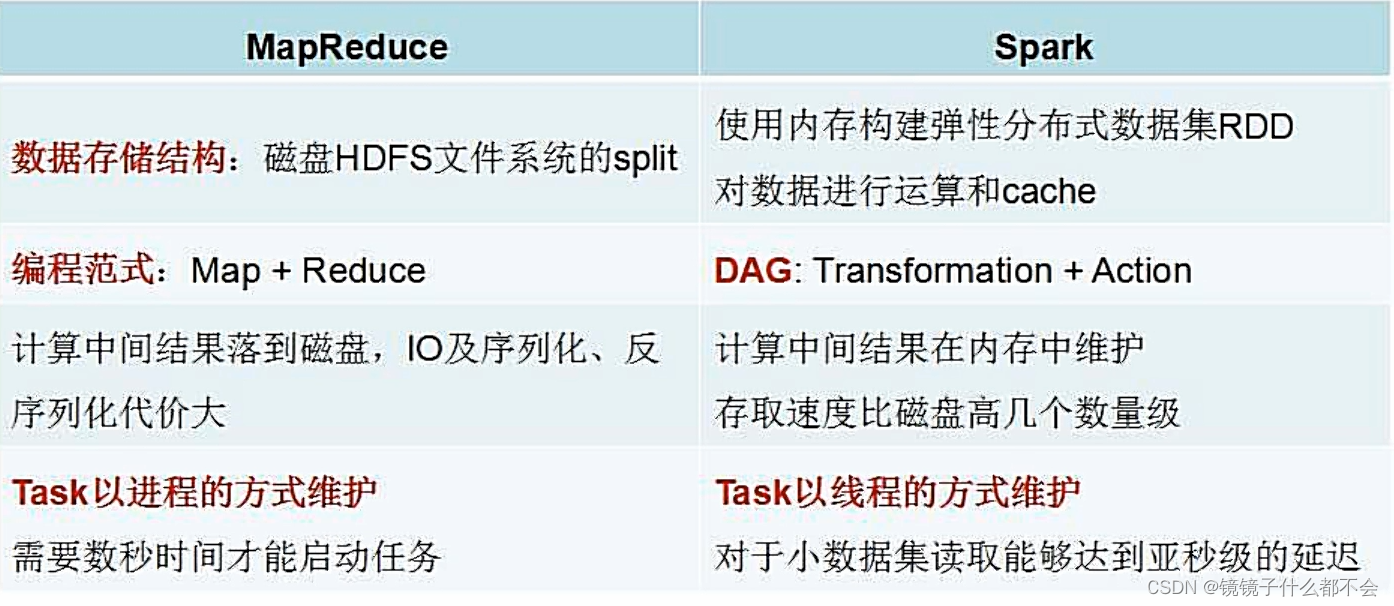
mapreduce和spark的对比:
spark是内存计算框架,mapreduce是磁盘计算框架
这张图显而易见,性能高
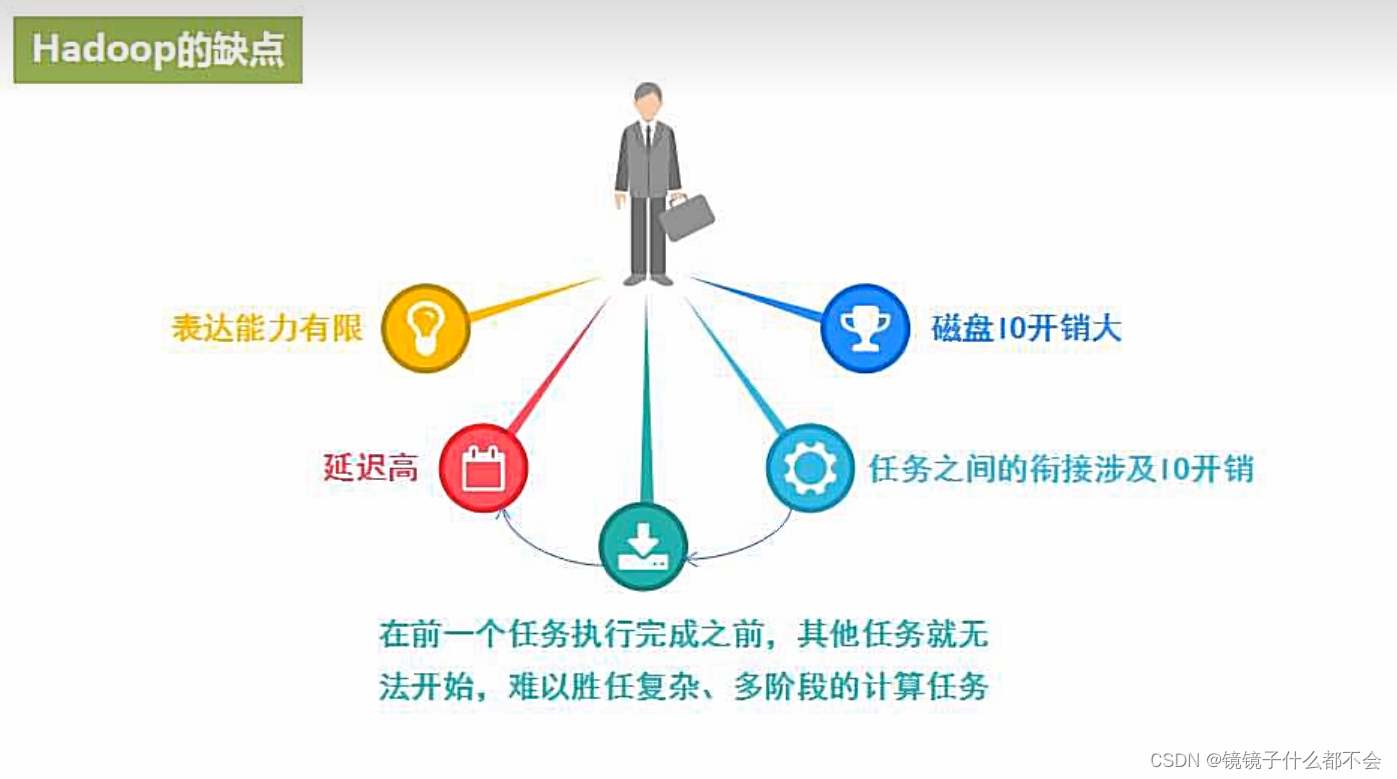


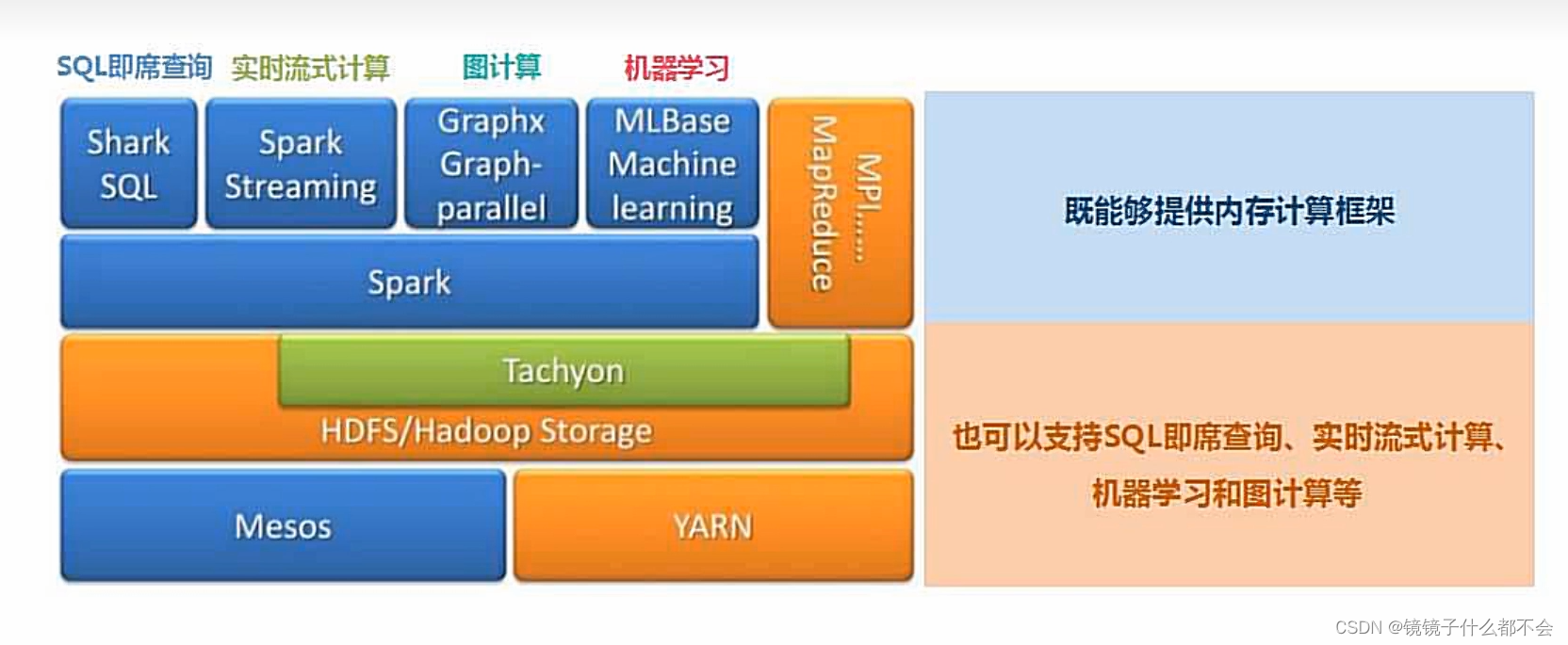
spark的生态系统良好,学习起来方便
基本概念与架构
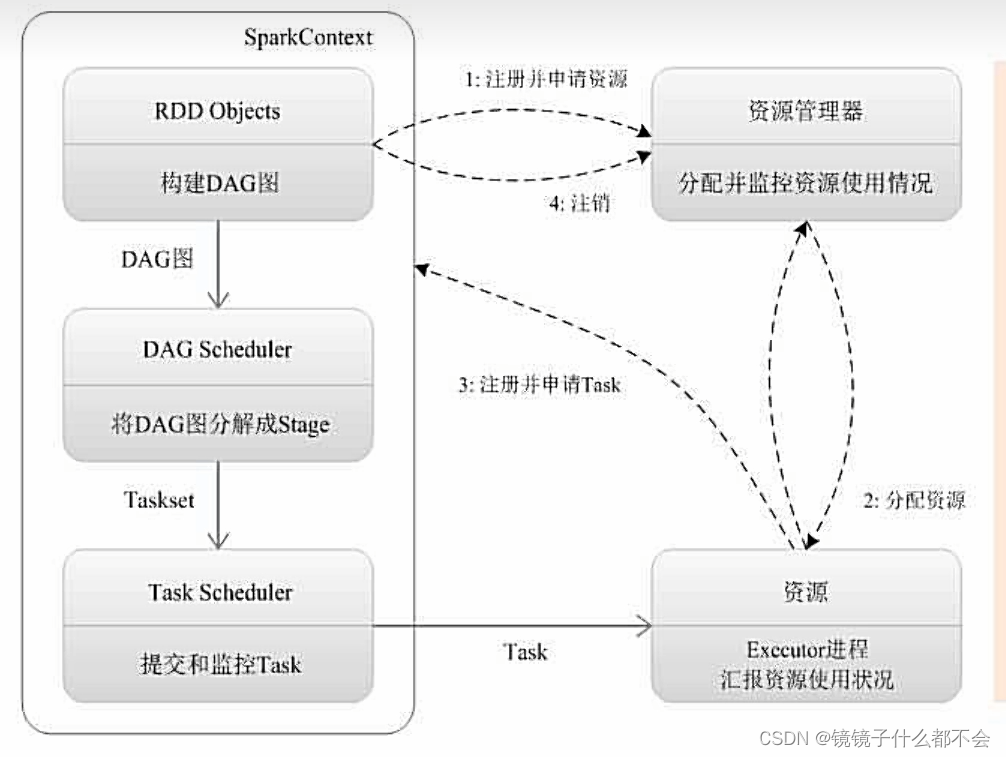
driver作为管家结点,当执行一个application时,driver会向集群管理器申请资源,启动executor,并向executor发送应用程序代码和文件,然后在executor上执行task,运行结束后,执行结果会返回给driver,或者写到hdfs或者其他数据库中

简述spark集群的基本运行流程
1)spark集群启动后,worker向master注册信息,spark-submit命令提交程序后,driver和application也会向master注册信息,创建sparkcontext对象:主要的对象包含dagscheduler和taskscheduler
2)driver把application信息注册给master后,master会根据app信息去worker节点启动executor
3)executor内部会创建运行task的线程池,然后把启动的executor反向注册给dirver
4)dagscheduler:负责把spark作业转换成stage的dag(directed acyclic graph有向无环图),根据宽窄依赖切分stage,然后把stage封装成taskset的形式发送个taskscheduler;同时dagscheduler还会处理由于shuffle数据丢失导致的失败;
5)taskscheduler:维护所有taskset,分发task给各个节点的executor(根据数据本地化策略分发task),监控task的运行状态,负责重试失败的task;
6)所有task运行完成后,sparkcontext向master注销,释放资源;
1.为应用构建起基本的运行环境,即由driver创建一个sparkcontext进行资源的申请、任务的分配和监控(sparkcontext构建起应用和集群直接的联系,连接集群的通道)
2.资源管理器为executor分配资源,并启动executor进程
写入rdd的原因

rdd提供了一组丰富的操作以支持常见的数据运算,分为“动作”(action)和“”(transformation)两种类型,rdd提供的转换接口都非常简单,都是类似map、filter、groupby、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改(不适合网页爬虫)
执行过程
惰性机制,转换记录轨迹,到了动作的时候才会真正的计算


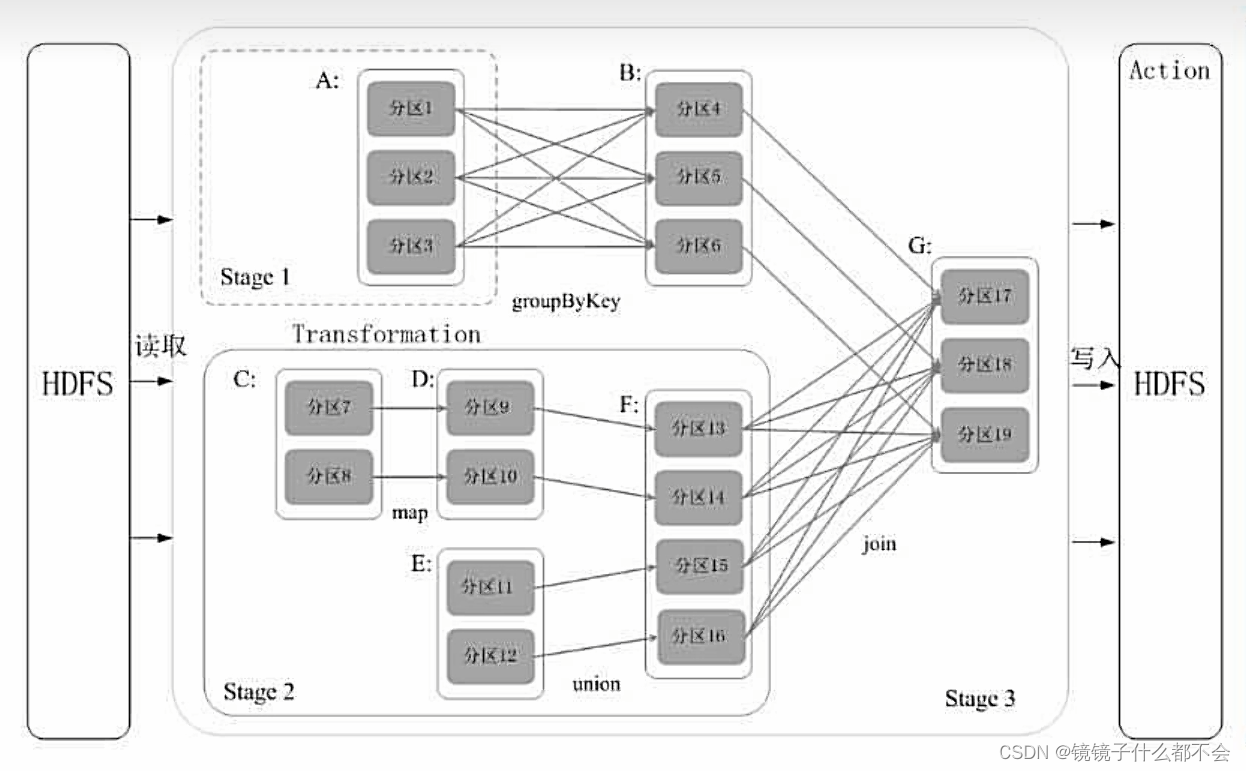
rdd的依赖关系和划分
宽依赖和窄依赖

窄依赖
表现为一个父rdd的分区对应于一个子rdd的分区或多个父rdd的分区对应
于一个子rdd的分区(一对一,多对一)
宽依赖
表现为存在一个父rdd的一个分区对应一个子rdd的多个分区(多对一)


遇到宽依赖断开,遇到窄依赖就把rdd加到阶段中,就可以生成多个阶段。每个阶段包含很多任务,这些阶段派发给各个结点执行
看个例子:
先划分出stage2,然后遇到f到g断开,a-b断开...最终形成
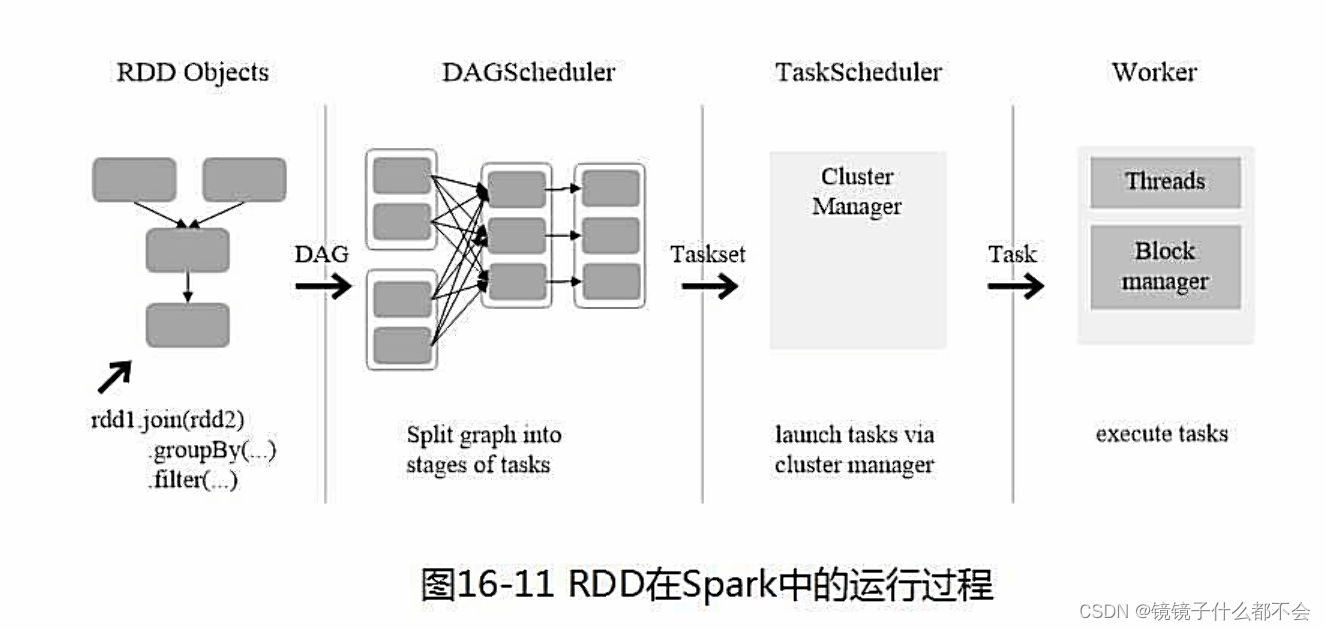
所以rdd的运行流程就是:
(1)创建rdd对象
(2)sparkcontext负责计算rdd之间的依赖关系,构建dag
(3)dagscheduler负责把dag图分解成多个stage每个stage中包含了多个task每个task会被taskscheduler分发给各个workernode上的executor去执行
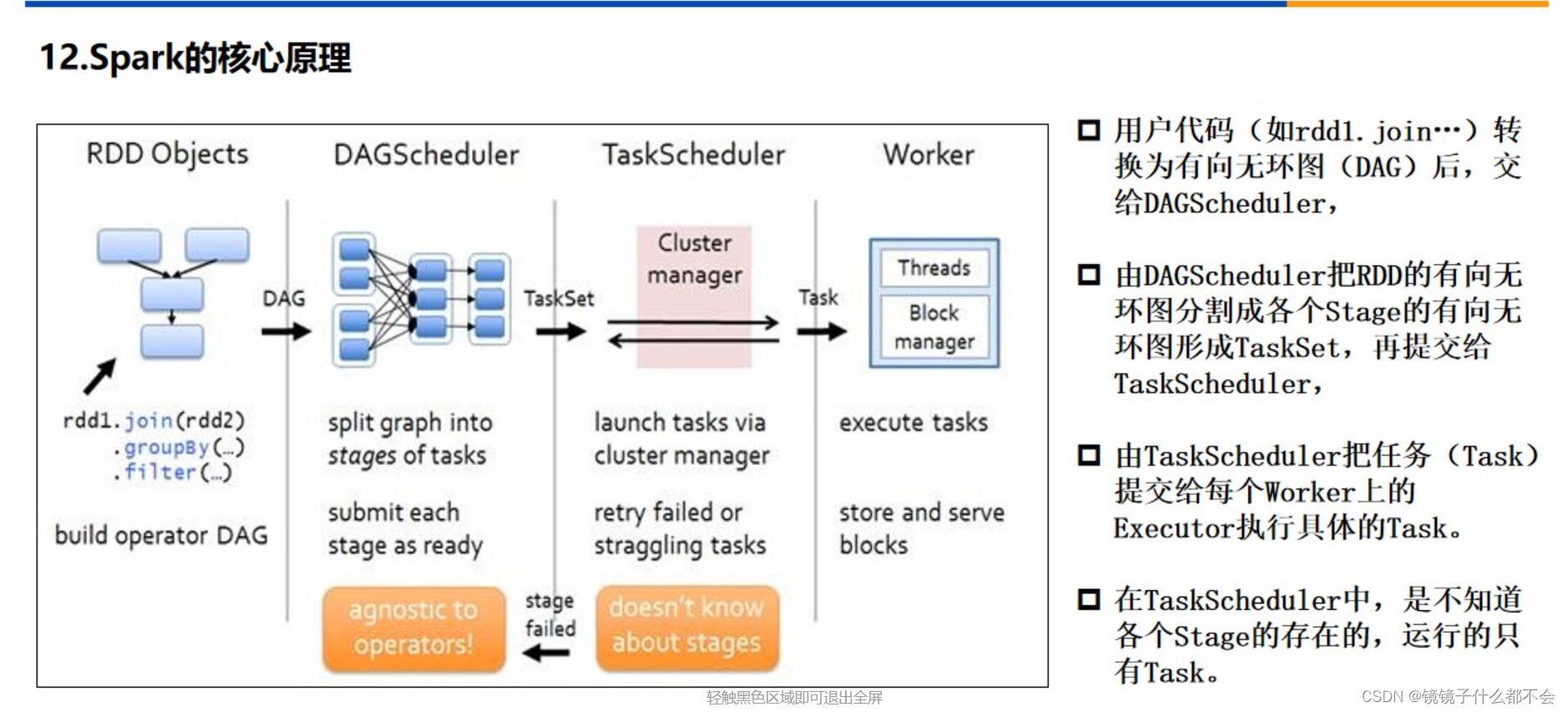
这张图能详细说明spark的核心原理
创建rdd的方式
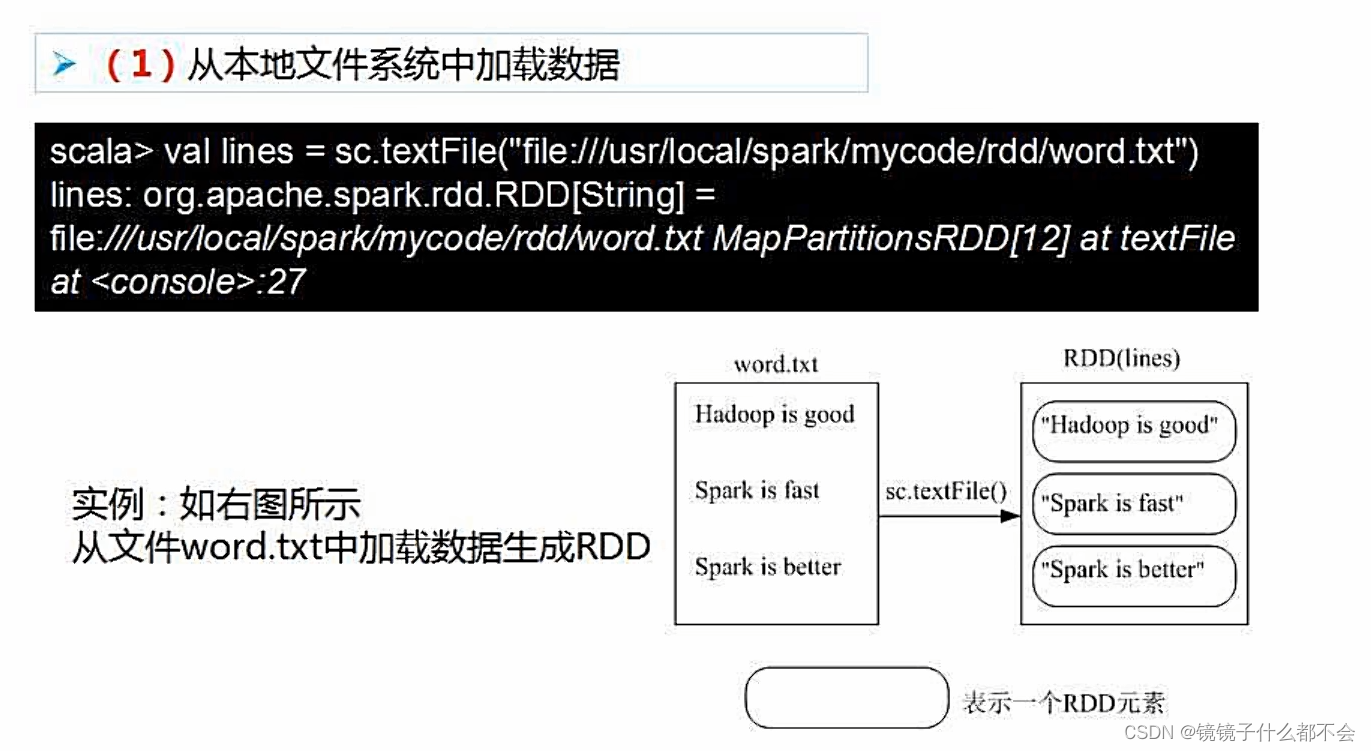
1.文件系统创建

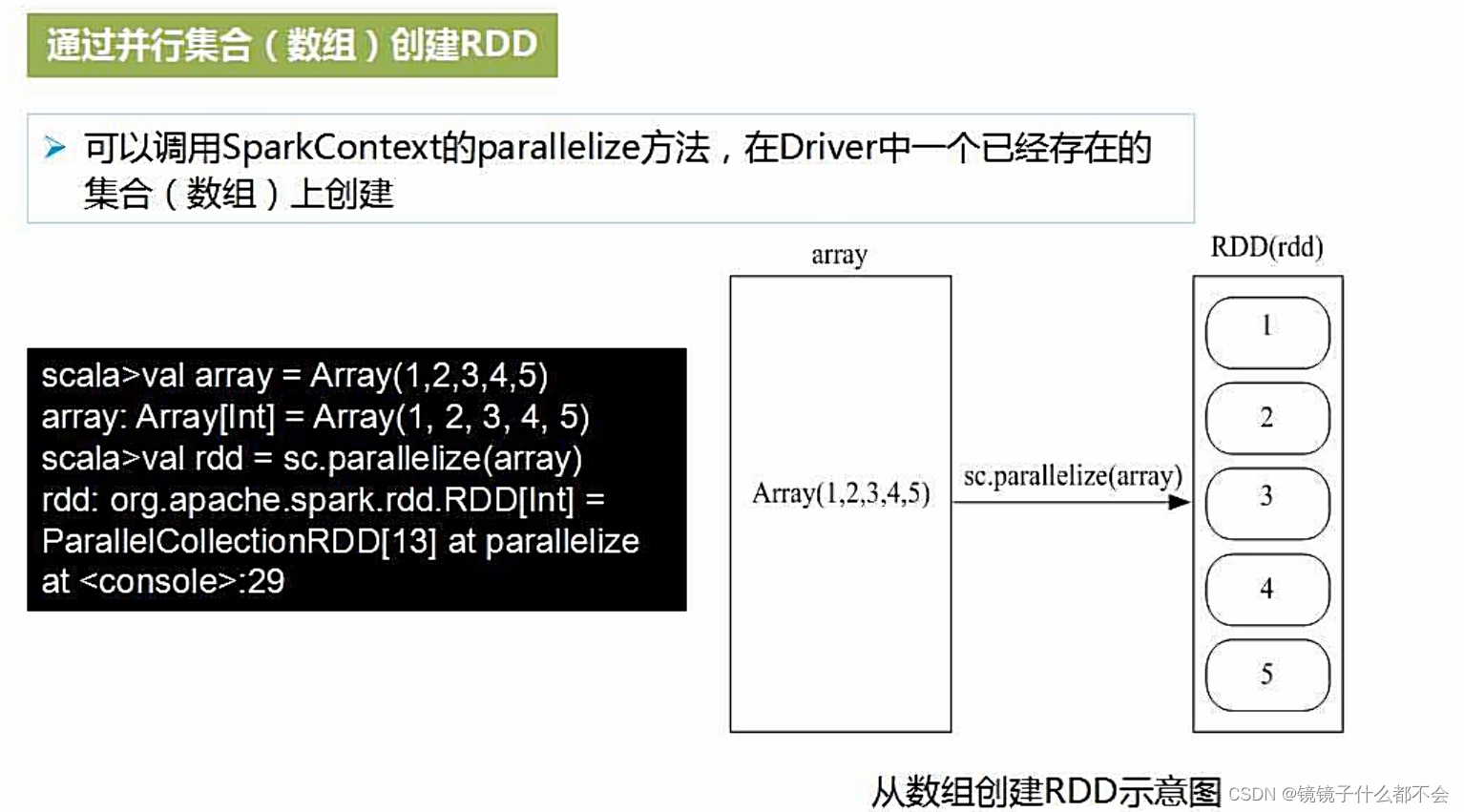
2.数组的方式创建

看个例子:
从文件系统创建rdd

通过数组读取
通过parallelize生成每个rdd

转换操作
行动操作
行动(action)操作是真正触发计算的地方。spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,计算得到结果

前两行不会真正执行,只会记录这个行动,第三行reduce操作才会行动,第二行为求每行的长度。
第三行执行的时候会先求每行长度,然后做一个汇总

再来个例子:

切割每行,统计每行单词数,返回最大的

键值对rdd
pairrdd


文件数据读写
1.本地文件读写

把文件写回去

json数据读写


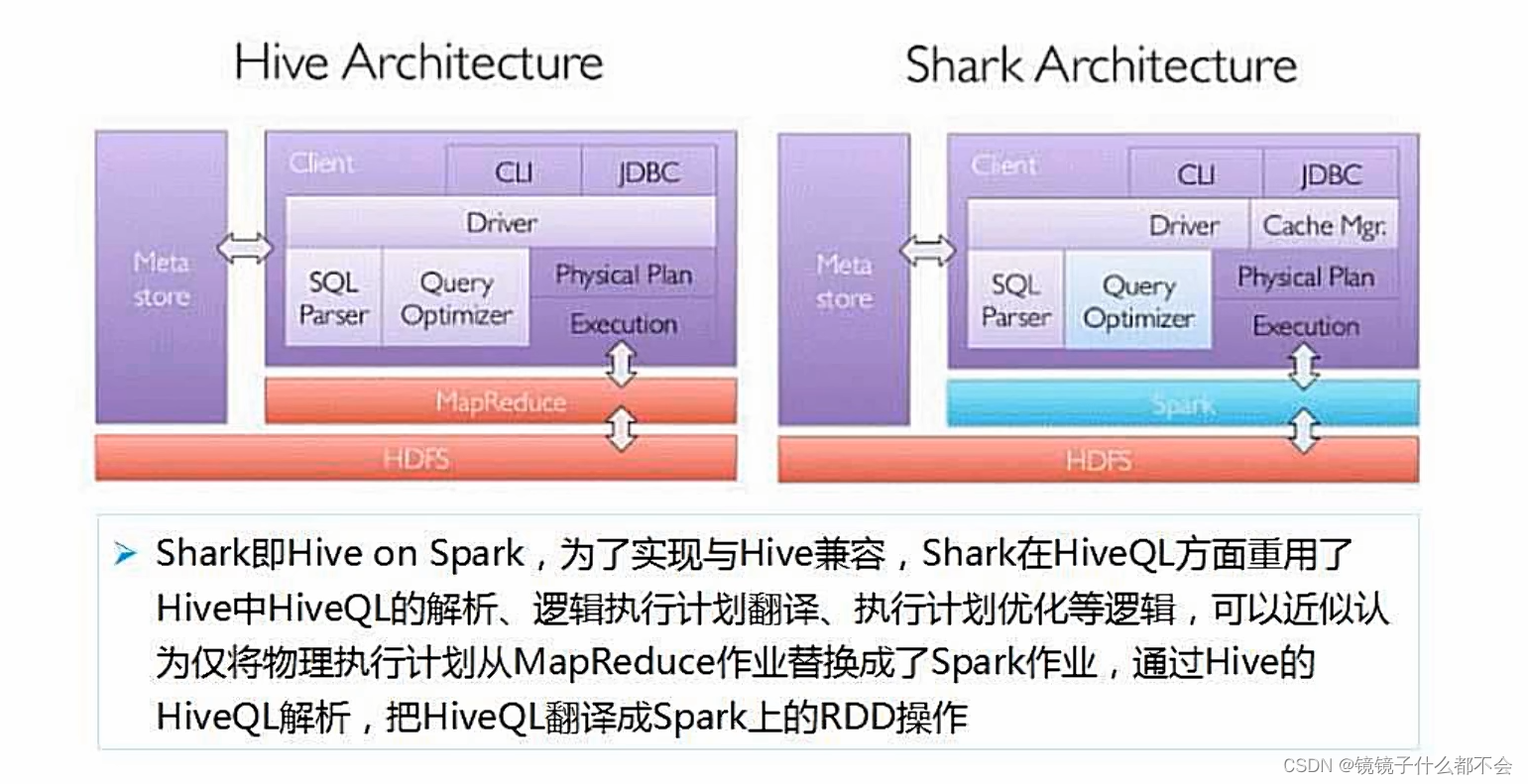
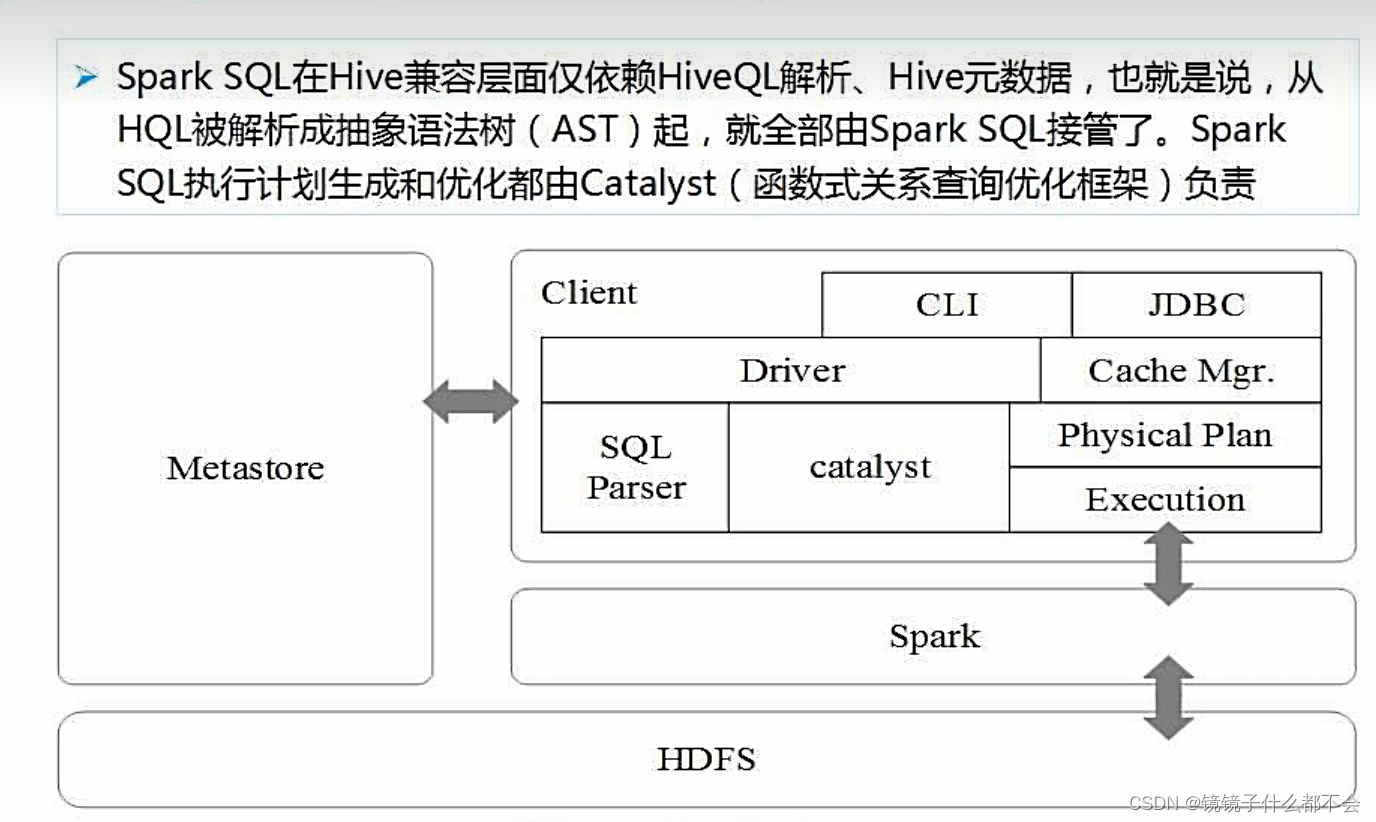
sparksql简介
shark直接从hive里面搬过来的,只有蓝色部分,转换成spark,提升性能



发表评论