llm之rag之llamaindex:llama-index(一块轻快构建索引来查询本地文档的数据框架神器)的简介、安装、使用方法之详细攻略
目录
(2)、使用非 openai 的 llm(例如在 replicate 上托管的 llama 2)构建一个简单的向量存储索引
llm之rag之llamaindex:基于llamaindex框架和chatgpt接口设计rag系统来实现构建和查询本地文档索引实战代码之详细攻略
llamaindex的简介
2023年1月29日正式发布,llamaindex(gpt index)是一个用于 llm 应用的数据框架。使用 llamaindex 构建应用通常涉及使用 llamaindex 核心和一组选择的集成(或插件)。llms 是一种生成知识和推理的非凡技术。它们在大量公开可用数据上进行预训练。
llamaindex是一个数据框架,用于基于llm的应用程序摄取、构建和访问私有或特定领域的数据。它可以在python(这些文档)和typescript中使用。llm提供了人与数据之间的自然语言接口。广泛可用的模型已经在大量公开可用的数据上进行了预训练,如维基百科、邮件列表、教科书、源代码等。然而,尽管llm经过大量数据的训练,但它们并没有经过你自己数据的训练,而您的数据可能是私有的或特定于您尝试解决的问题。它可能位于api后面,存储在sql数据库中,或者被封存在pdf和幻灯片中。
llamaindex通过连接到这些数据源,并将数据添加到llm已经拥有的数据中来解决这个问题。这通常被称为检索增强生成(rag)。rag使您能够使用llm来查询数据、转换数据并生成新的见解。你可以询问有关数据的问题,创建聊天机器人,构建半自主代理等等。要了解更多信息,请查看左侧的用例。
llamaindex为初学者、高级用户以及介于两者之间的所有人提供了工具。我们的高级api允许初学者使用llamaindex在5行代码中摄取和查询他们的数据。对于更复杂的应用程序,我们的低级api允许高级用户定制和扩展任何模块——数据连接器、索引、检索器、查询引擎、重新排序模块——以满足他们的需求。对比langchain(重点是agent 和 chain 上),llamaindex的一个很大的优势,通过各种方式为文本建立索引,能够创建层次化的索引,这在语料库增长到一定大小时非常有帮助。
llama-index库目前在持续迭代。早期版本,对于中文支持存在一些小缺陷。它提供了许多dataconnector选项,包括pdf、epub等电子书格式以及youtube、notion、mongodb等外部数据源和api接入数据甚至本地数据库的数据。你可以在 llamahub.ai 上查看社区开发的各种不同数据源格式的dataconnector。
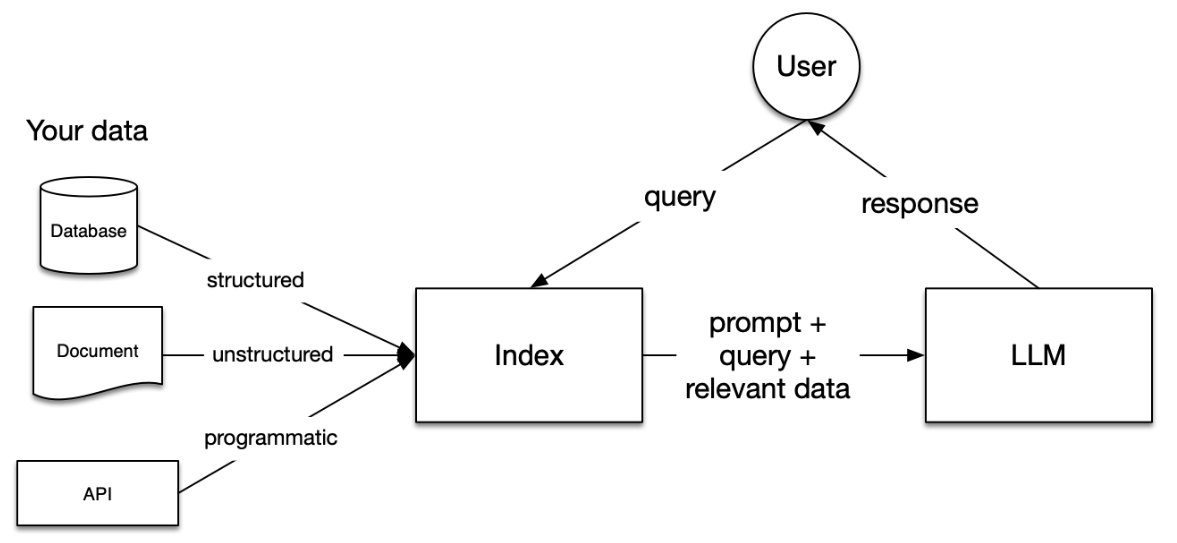
我们如何最好地用自己的私有数据增强 llms?我们需要一个综合工具包来帮助为 llms 执行这种数据增强。这就是 llamaindex 的作用所在。llamaindex 是一个“数据框架”,帮助你构建 llm 应用。它提供以下工具:
>> 提供数据连接器以摄取你现有的数据源和数据格式(api、pdf、文档、sql 等)。
>> 提供结构化数据的方法(索引、图表),以便这些数据可以轻松与 llms 一起使用。
>> 提供一个高级检索/查询接口:输入任何 llm 提示,获取检索到的上下文和知识增强的输出。
>> 允许与外部应用框架轻松集成(例如,与 langchain、flask、docker、chatgpt 等)。
llamaindex 为初学者和高级用户提供工具。我们的高级 api 允许初学者在 5 行代码中使用 llamaindex 来摄取和查询数据。我们的低级 api 允许高级用户定制和扩展任何模块(数据连接器、索引、检索器、查询引擎、重新排序模块),以满足他们的需求。
官网地址:llamaindex 🦙 0.8.61
llamaindex.ts (typescript/javascript): https://github.com/run-llama/llamaindexts
twitter: https://twitter.com/llama_index
discord: https://discord.gg/dgcwcsnxhu
github地址:github - run-llama/llama_index: llamaindex is a data framework for your llm applications
1、llamaindex有什么帮助?
llamaindex提供了以下工具:
>> 数据连接器从其原生源和格式中摄取现有数据。这些可以是api、pdf、sql等等。
>> 数据索引将您的数据结构化为中间表示形式,易于llm消耗且性能良好。
>> 引擎提供对数据的自然语言访问。例如:
--查询引擎是用于知识增强输出的强大检索接口;
--聊天引擎是用于与数据进行多消息“来回”交互的会话界面。
>> 数据代理是由llm支持的知识工作者,通过工具(从简单的辅助函数到api集成等)进行增强。
>> 应用程序集成将llamaindex与生态系统的其余部分联系起来。它可以是langchain, flask, docker, chatgpt,或者其他任何东西!
2、核心原理
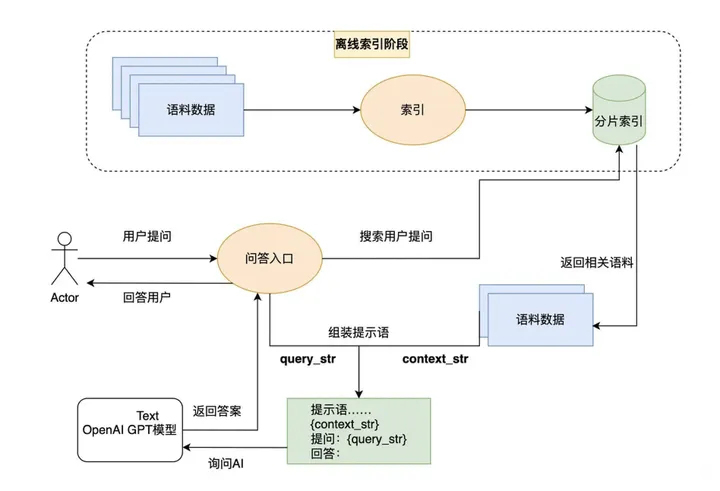
llama-index 提供了一种创新的大语言模型应用设计模式。它通过先为外部资料库建立索引,再在每次提问时从资料库中搜索相关内容,最后利用ai的语义理解能力基于搜索结果回答问题。
在索引和搜索的前两步,我们可以使用 openai 的 embedding 接口,也可以使用其他大语言模型的 embedding 接口,或者使用传统的文本搜索技术。只有在问答的最后一步,才必须使用 openai 的接口。我们不仅可以索引文本信息,还可以通过其他模型将图片转换为文本并进行索引,实现所谓的多模态功能。
llama-index的安装
1、安装
pip install llama-index
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index
pip install -i https://mirrors.aliyun.com/pypi/simple llama-index llama-index-core
pip install -i https://mirrors.aliyun.com/pypi/simple -qu llama-index llama-index-core # -q:这个参数表示安静模式(quiet),它会减少输出的信息,只显示错误信息。
-u:这个参数表示升级模式(upgrade),它会升级指定的软件包到最新版本。
c:\windows\system32>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index
looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
collecting llama-index
downloading https://pypi.tuna.tsinghua.edu.cn/packages/43/03/f2669df2f5cce8a7b3f5f6fa50dbae9b6ee11cd5763aa34962aa13c26de5/llama_index-0.8.59-py3-none-any.whl (816 kb)
|████████████████████████████████| 816 kb 1.1 mb/s
collecting nest-asyncio<2.0.0,>=1.5.8
downloading https://pypi.tuna.tsinghua.edu.cn/packages/ab/d3/48c01d1944e0ee49fdc005bf518a68b0582d3bd201e5401664890b62a647/nest_asyncio-1.5.8-py3-none-any.whl (5.3 kb)
requirement already satisfied: pandas in d:\programdata\anaconda3\lib\site-packages (from llama-index) (1.3.5)
requirement already satisfied: typing-extensions>=4.5.0 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (4.8.0)
requirement already satisfied: fsspec>=2023.5.0 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (2023.10.0)
collecting deprecated>=1.2.9.3
downloading https://pypi.tuna.tsinghua.edu.cn/packages/20/8d/778b7d51b981a96554f29136cd59ca7880bf58094338085bcf2a979a0e6a/deprecated-1.2.14-py2.py3-none-any.whl (9.6 kb)
requirement already satisfied: numpy in d:\programdata\anaconda3\lib\site-packages (from llama-index) (1.24.4)
requirement already satisfied: tiktoken>=0.3.3 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (0.5.1)
requirement already satisfied: nltk<4.0.0,>=3.8.1 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (3.8.1)
requirement already satisfied: urllib3<2 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (1.26.9)
collecting aiostream<0.6.0,>=0.5.2
downloading https://pypi.tuna.tsinghua.edu.cn/packages/b3/2a/4140da24a81adce23b79e4fdc3fc722c9ff698460c1b9f8f7bd3742eb02e/aiostream-0.5.2-py3-none-any.whl (39 kb)
requirement already satisfied: tenacity<9.0.0,>=8.2.0 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (8.2.3)
requirement already satisfied: openai>=0.26.4 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (0.27.2)
requirement already satisfied: typing-inspect>=0.8.0 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (0.8.0)
requirement already satisfied: sqlalchemy[asyncio]>=1.4.49 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (2.0.22)
requirement already satisfied: dataclasses-json<0.6.0,>=0.5.7 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (0.5.7)
requirement already satisfied: langchain>=0.0.303 in d:\programdata\anaconda3\lib\site-packages (from llama-index) (0.0.317)
requirement already satisfied: marshmallow<4.0.0,>=3.3.0 in d:\programdata\anaconda3\lib\site-packages (from dataclasses-json<0.6.0,>=0.5.7->llama-index) (3.19.0)
requirement already satisfied: marshmallow-enum<2.0.0,>=1.5.1 in d:\programdata\anaconda3\lib\site-packages (from dataclasses-json<0.6.0,>=0.5.7->llama-index) (1.5.1)
requirement already satisfied: wrapt<2,>=1.10 in d:\programdata\anaconda3\lib\site-packages (from deprecated>=1.2.9.3->llama-index) (1.12.1)
requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (3.8.6)
requirement already satisfied: requests<3,>=2 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (2.31.0)
requirement already satisfied: jsonpatch<2.0,>=1.33 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (1.33)
requirement already satisfied: langsmith<0.1.0,>=0.0.43 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (0.0.46)
requirement already satisfied: async-timeout<5.0.0,>=4.0.0 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (4.0.1)
requirement already satisfied: pydantic<3,>=1 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (2.4.2)
requirement already satisfied: pyyaml>=5.3 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (6.0)
requirement already satisfied: anyio<4.0 in d:\programdata\anaconda3\lib\site-packages (from langchain>=0.0.303->llama-index) (3.7.1)
requirement already satisfied: yarl<2.0,>=1.0 in d:\programdata\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.3->langchain>=0.0.303->llama-index) (1.6.3)
requirement already satisfied: attrs>=17.3.0 in d:\programdata\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.3->langchain>=0.0.303->llama-index) (21.4.0)
requirement already satisfied: multidict<7.0,>=4.5 in d:\programdata\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.3->langchain>=0.0.303->llama-index) (5.1.0)
requirement already satisfied: aiosignal>=1.1.2 in d:\programdata\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.3->langchain>=0.0.303->llama-index) (1.2.0)
requirement already satisfied: charset-normalizer<4.0,>=2.0 in d:\programdata\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.3->langchain>=0.0.303->llama-index) (2.0.12)
requirement already satisfied: frozenlist>=1.1.1 in d:\programdata\anaconda3\lib\site-packages (from aiohttp<4.0.0,>=3.8.3->langchain>=0.0.303->llama-index) (1.2.0)
requirement already satisfied: idna>=2.8 in d:\programdata\anaconda3\lib\site-packages (from anyio<4.0->langchain>=0.0.303->llama-index) (3.3)
requirement already satisfied: sniffio>=1.1 in d:\programdata\anaconda3\lib\site-packages (from anyio<4.0->langchain>=0.0.303->llama-index) (1.2.0)
requirement already satisfied: exceptiongroup in d:\programdata\anaconda3\lib\site-packages (from anyio<4.0->langchain>=0.0.303->llama-index) (1.1.3)
requirement already satisfied: jsonpointer>=1.9 in d:\programdata\anaconda3\lib\site-packages (from jsonpatch<2.0,>=1.33->langchain>=0.0.303->llama-index) (2.4)
requirement already satisfied: packaging>=17.0 in d:\programdata\anaconda3\lib\site-packages (from marshmallow<4.0.0,>=3.3.0->dataclasses-json<0.6.0,>=0.5.7->llama-index) (21.3)
requirement already satisfied: click in d:\programdata\anaconda3\lib\site-packages (from nltk<4.0.0,>=3.8.1->llama-index) (8.0.4)
requirement already satisfied: tqdm in d:\programdata\anaconda3\lib\site-packages (from nltk<4.0.0,>=3.8.1->llama-index) (4.66.1)
requirement already satisfied: regex>=2021.8.3 in d:\programdata\anaconda3\lib\site-packages (from nltk<4.0.0,>=3.8.1->llama-index) (2022.3.15)
requirement already satisfied: joblib in d:\programdata\anaconda3\lib\site-packages (from nltk<4.0.0,>=3.8.1->llama-index) (1.1.0)
requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in d:\programdata\anaconda3\lib\site-packages (from packaging>=17.0->marshmallow<4.0.0,>=3.3.0->dataclasses-json<0.6.0,>=0.5.7->llama-index) (3.0.4)
requirement already satisfied: annotated-types>=0.4.0 in d:\programdata\anaconda3\lib\site-packages (from pydantic<3,>=1->langchain>=0.0.303->llama-index) (0.6.0)
requirement already satisfied: pydantic-core==2.10.1 in d:\programdata\anaconda3\lib\site-packages (from pydantic<3,>=1->langchain>=0.0.303->llama-index) (2.10.1)
requirement already satisfied: certifi>=2017.4.17 in d:\programdata\anaconda3\lib\site-packages (from requests<3,>=2->langchain>=0.0.303->llama-index) (2021.10.8)
requirement already satisfied: greenlet!=0.4.17 in d:\programdata\anaconda3\lib\site-packages (from sqlalchemy[asyncio]>=1.4.49->llama-index) (2.0.2)
requirement already satisfied: mypy-extensions>=0.3.0 in d:\programdata\anaconda3\lib\site-packages (from typing-inspect>=0.8.0->llama-index) (0.4.3)
requirement already satisfied: colorama in d:\programdata\anaconda3\lib\site-packages (from click->nltk<4.0.0,>=3.8.1->llama-index) (0.4.4)
requirement already satisfied: pytz>=2017.3 in d:\programdata\anaconda3\lib\site-packages (from pandas->llama-index) (2021.3)
requirement already satisfied: python-dateutil>=2.7.3 in d:\programdata\anaconda3\lib\site-packages (from pandas->llama-index) (2.8.2)
requirement already satisfied: six>=1.5 in d:\programdata\anaconda3\lib\site-packages (from python-dateutil>=2.7.3->pandas->llama-index) (1.16.0)
installing collected packages: nest-asyncio, deprecated, aiostream, llama-index
attempting uninstall: nest-asyncio
found existing installation: nest-asyncio 1.5.5
uninstalling nest-asyncio-1.5.5:
successfully uninstalled nest-asyncio-1.5.5
successfully installed aiostream-0.5.2 deprecated-1.2.14 llama-index-0.8.59 nest-asyncio-1.5.8
2、使用方法
在 python 中有两种方式开始使用 llamaindex:
入门版:llama-index(https://pypi.org/project/llama-index/)。一个包含核心 llamaindex 以及一部分集成的入门 python 包。
定制版:llama-index-core(https://pypi.org/project/llama-index-core/)。安装核心 llamaindex,并添加你在 llamahub 上选择的适用于你应用的 llamaindex 集成包。共有超过300个与核心无缝协作的 llamaindex 集成包,允许你使用你喜欢的 llm、嵌入和向量存储提供商。
llamaindex python 库的命名空间规定,包含 core 的 import 语句表示使用核心包,而不包含 core 的语句表示使用集成包。
典型模式
from llama_index.core.xxx import classabc # 核心子模块 xxx
from llama_index.xxx.yyy import (
subclassabc,
) # 子模块 xxx 的集成 yyy
具体示例
from llama_index.core.llms import llm
from llama_index.llms.openai import openai
示例用法
使用核心的自定义集成选择
pip install llama-index-core
pip install llama-index-llms-openai
pip install llama-index-llms-replicate
pip install llama-index-embeddings-huggingface
示例在 docs/examples 文件夹中。索引在 indices 文件夹中(请参阅下方索引列表)。
(1)、使用 openai 构建一个简单的向量存储索引:
import os
os.environ["openai_api_key"] = "your_openai_api_key"
from llama_index.core import vectorstoreindex, simpledirectoryreader
documents = simpledirectoryreader("your_data_directory").load_data()
index = vectorstoreindex.from_documents(documents)
(2)、使用非 openai 的 llm(例如在 replicate 上托管的 llama 2)构建一个简单的向量存储索引
# 你可以轻松创建一个免费试用 api 令牌:
import os
os.environ["replicate_api_token"] = "your_replicate_api_token"
from llama_index.core import settings, vectorstoreindex, simpledirectoryreader
from llama_index.embeddings.huggingface import huggingfaceembedding
from llama_index.llms.replicate import replicate
from transformers import autotokenizer
# 设置 llm
llama2_7b_chat = "meta/llama-2-7b-chat:8e6975e5ed6174911a6ff3d60540dfd4844201974602551e10e9e87ab143d81e"
settings.llm = replicate(
model=llama2_7b_chat,
temperature=0.01,
additional_kwargs={"top_p": 1, "max_new_tokens": 300},
)
# 设置与 llm 匹配的 tokenizer
settings.tokenizer = autotokenizer.from_pretrained(
"nousresearch/llama-2-7b-chat-hf"
)
# 设置嵌入模型
settings.embed_model = huggingfaceembedding(
model_name="baai/bge-small-en-v1.5"
)
documents = simpledirectoryreader("your_data_directory").load_data()
index = vectorstoreindex.from_documents(
documents,
)
# 查询:
query_engine = index.as_query_engine()
query_engine.query("your_question")
# 默认情况下,数据存储在内存中。要持久化到磁盘(在 ./storage 下):
index.storage_context.persist()
# 从磁盘重新加载:
from llama_index.core import storagecontext, load_index_from_storage
# 重建存储上下文
storage_context = storagecontext.from_defaults(persist_dir="./storage")
# 加载索引
index = load_index_from_storage(storage_context)
llama-index的案例应用
1、基础用法
(1)、5行代码来高效地查询指定文件内你所需的内容
第一步,下载数据
此示例使用paul graham的文章《我做了什么》的文本。您可以在我们的存储库的示例文件夹中找到此示例和许多其他示例。获取它的最简单方法是通过此链接下载它,并将其保存在名为“data”的文件夹中。
第二步,设置您的openai api密钥
llamaindex默认使用openai的gpt-3.5-turbo。请确保将您的api密钥设置为环境变量,以使其可供您的代码使用。
| linux系统 | 在macos和linux中,这是命令: export openai_api_key=xxxxx |
| windows系统 | 在windows中,使用以下命令: set openai_api_key=xxxxx |
第三步,加载数据并构建索引
在创建“data”文件夹的同一文件夹中,创建一个名为“starter.py”的文件,其中包含以下内容:
from llama_index import vectorstoreindex, simpledirectoryreader
documents = simpledirectoryreader('data').load_data()
index = vectorstoreindex.from_documents(documents)# 这将在“data”文件夹中的文档上构建一个索引(在这种情况下,仅包括文章文本,但可能包含许多文档)。
最后,你的目录结构应如下所示:
├── starter.py
└── data
└── paul_graham_essay.txt
第四步,查询您的数据
在“starter.py”中添加以下行,这将创建一个用于在索引上进行问答的引擎,并提出一个简单的问题。您应该会收到类似以下内容的回复:作者写了短篇小说,并尝试在ibm 1401上编程。
query_engine = index.as_query_engine()
response = query_engine.query("作者在成长过程中做了什么?")
print(response)
第五步,使用日志查看查询和事件
想要查看底层发生了什么?让我们添加一些日志。在“starter.py”的顶部添加以下行,您可以将级别设置为debug以获取详细输出,或使用level=logging.info以获取较少的输出。
import logging
import sys
logging.basicconfig(stream=sys.stdout, level=logging.debug)
logging.getlogger().addhandler(logging.streamhandler(stream=sys.stdout))
第六步,存储您的索引
默认情况下,您刚刚加载的数据以一系列向量嵌入的形式存储在内存中。通过将嵌入保存到磁盘,您可以节省时间(以及对openai的请求)。可以使用以下行来完成此操作:
index.storage_context.persist()默认情况下,这将数据保存到名为“storage”的目录中,但您可以通过传递persist_dir参数来更改目录。
当然,除非加载数据,否则您无法享受持久化的好处。因此,让我们修改“starter.py”,如果索引不存在则生成并存储索引,如果存在则加载索引:
import os.path
from llama_index import (
vectorstoreindex,
simpledirectoryreader,
storagecontext,
load_index_from_storage,
)
# 检查存储是否已经存在
if not os.path.exists("./storage"):
# 加载文档并创建索引
documents = simpledirectoryreader("data").load_data()
index = vectorstoreindex.from_documents(documents)
# 为以后存储它
index.storage_context.persist()
else:
# 加载现有的索引
storage_context = storagecontext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
# 无论如何,现在我们可以查询索引
query_engine = index.as_query_engine()
response = query_engine.query("what did the author do growing up?")
print(response)
现在,您可以高效地查询您所需的内容!但这只是您可以使用llamaindex做的事情的开端。
2、进阶用法
(1)、使用 llamaindex 构建和查询本地文档索引
llm之rag之llamaindex:基于llamaindex框架和chatgpt接口设计rag系统来实现构建和查询本地文档索引实战代码之详细攻略



发表评论