索泰 rtx 4080 super 16gb trinity oc 月白在默认模型下跑出了 16.49it/s、24.56it/s、28.14it/s
这是什么水准呢,从跑分天梯图来看就是妥妥的第二名(排名仅供参考,数据量目前很少)

换成 sdxl 大模型 + sdxl vae 的组合,分数就会骤降到 6.41it/s、11.73it/s、19.53it/s
要知道,这还是优化相对算好的高质量模型,想想要是用优化普通的模型 + lora + 额外扩展的组合,渲染量一大不崩才怪。
这应该就是高端卡的优势所在 ~ 生产力!

使用 sdxl 1.0 模型、搭配 sxdl/vae 模型,采样方法: dpm++2msde、迭代步数:60;图片宽度:1024;图片长度:1024;总批次数:1;单批数量:8。
耗时 1 分 56秒,显存最高达到了 13.3gb,基本上 4070ti super 以下阵亡了。

成品图

不仅如此,nvidia 还专门推出了用于加速 ai 矩阵运算 的 tensor cores ,这是一个针对深度学习推理的高性能 gpu 加速器,它可以自动对神经网络模型进行优化,提高运行速度并降低内存占用。

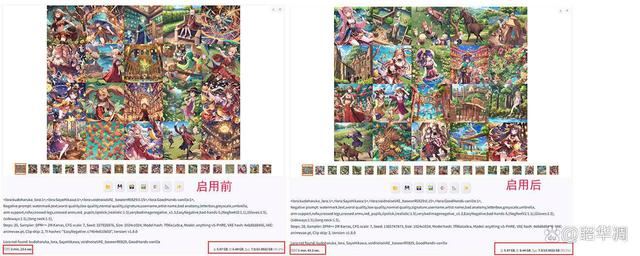
在 stable diffusion 中使用相同的提示词,一次生成 20 张图片,对比 tensor cores 加速前后耗时
tensor cores 加速前后,生成时间从 2 分 36 秒缩短到了 1 分 43 秒,加速实际效果达到了 51%。
这还只是用的基础模型库,关键字等各项参数也不复杂,换成高分辨率输出和多模型组合的话,这个差距只会越来越大。
而这才是老黄卡不愁卖的根本原因,生产力永远是核心需求。
总结
增量减价,堪称良心,这是我对 nvdida rtx 4080 super 显卡的看法。游戏性能相较于 rtx 4080 有 2%~10% 提升,可以很轻松满足 3a 大作对画质和帧率的需求,满血版 ad103 核心和 16gb 的超大显存,对于需要进行视频编辑、3d建模等高负载任务的生产力用户来说,简直就是雪中送炭。大显存意味着你可以同时打开更多的应用,处理更大的文件,而不会感受到丝毫的卡顿。
索泰 rtx 4080 super 16gb trinity oc 月白则是家用游戏显卡的典范。小巧纤细的机身,可以轻松适配各种小型机箱,让你的桌面空间不再受限。而且,它并没有因为体积小而牺牲性能,对比某些品牌用夸张的造型、过分的堆料来强行提高价格,索泰这样的做法无疑才是真正为玩家着想。





发表评论