es全文检索支持拼音和繁简检索
1. 实现目标
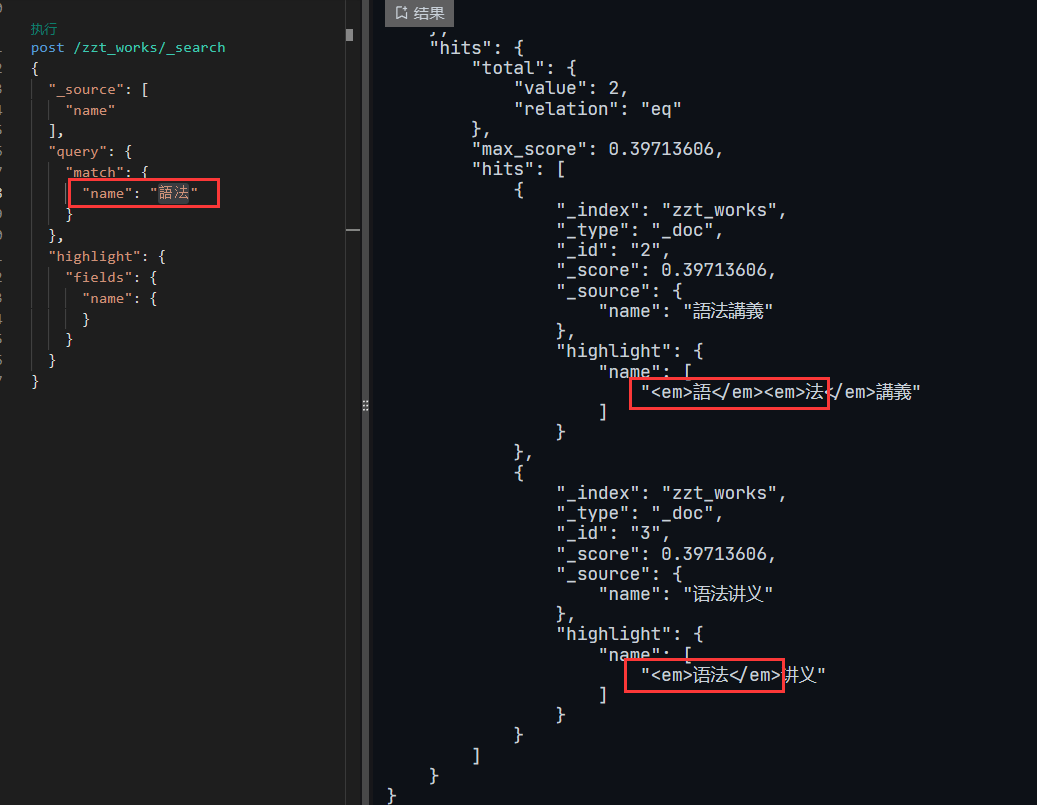
es检索时无论输入简体还是繁体都要能够被检索到,例如检索时输入“語法”或者“语法”,检索结果中无论是简体繁体都务必要被命中。
并且也要正确的高亮返回
2. 引入pinyin插件
拼音分词器(pinyin analyzer)通常需要自行引入,因为它不是 elasticsearch 的默认分词器。可以使用 elasticsearch 的插件来引入 pinyin 分词器,以便在索引中使用它。
2.1 编译 elasticsearch-analysis-pinyin 插件
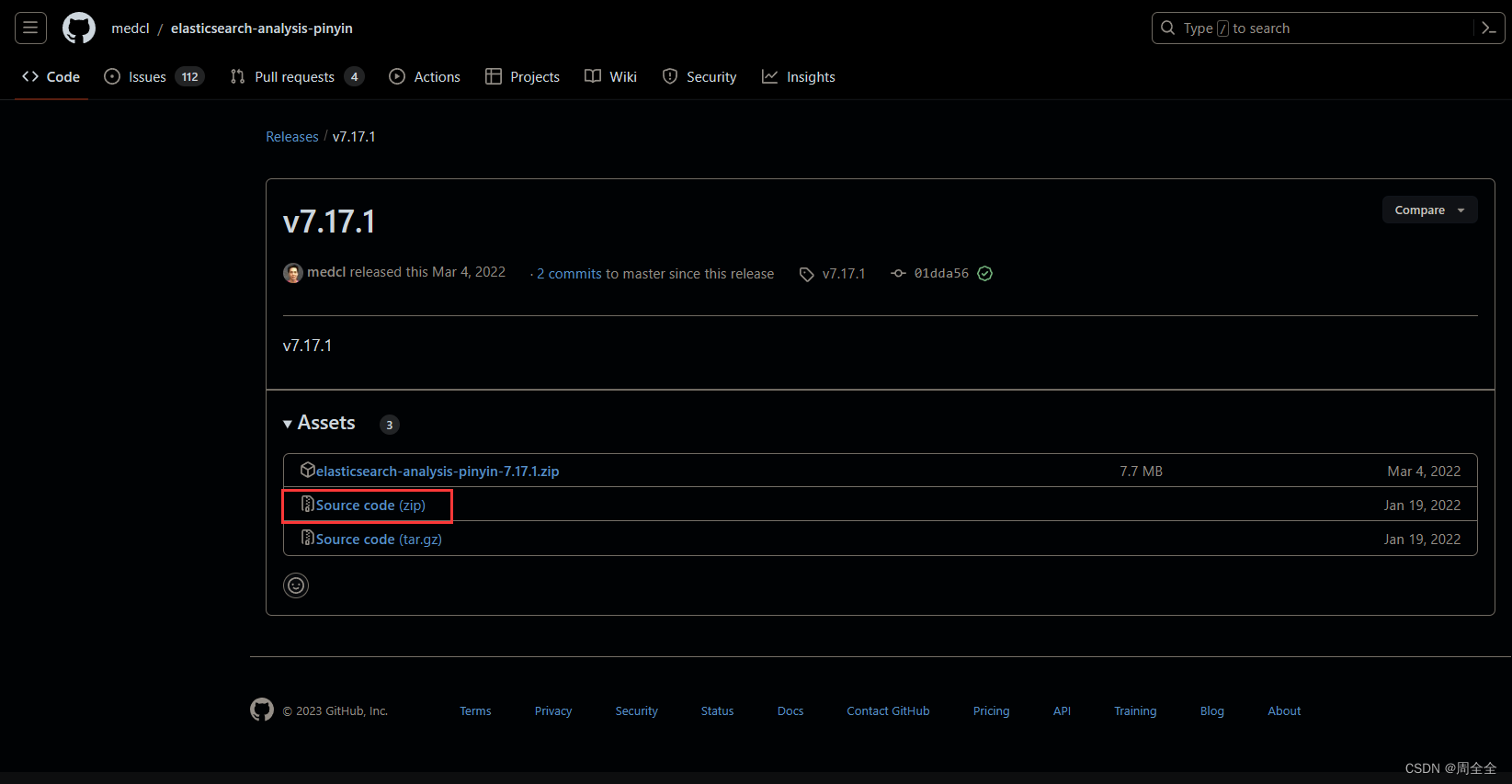
选择与自己版本一致的版本,插件地址:
https://github.com/medcl/elasticsearch-analysis-pinyin/releases
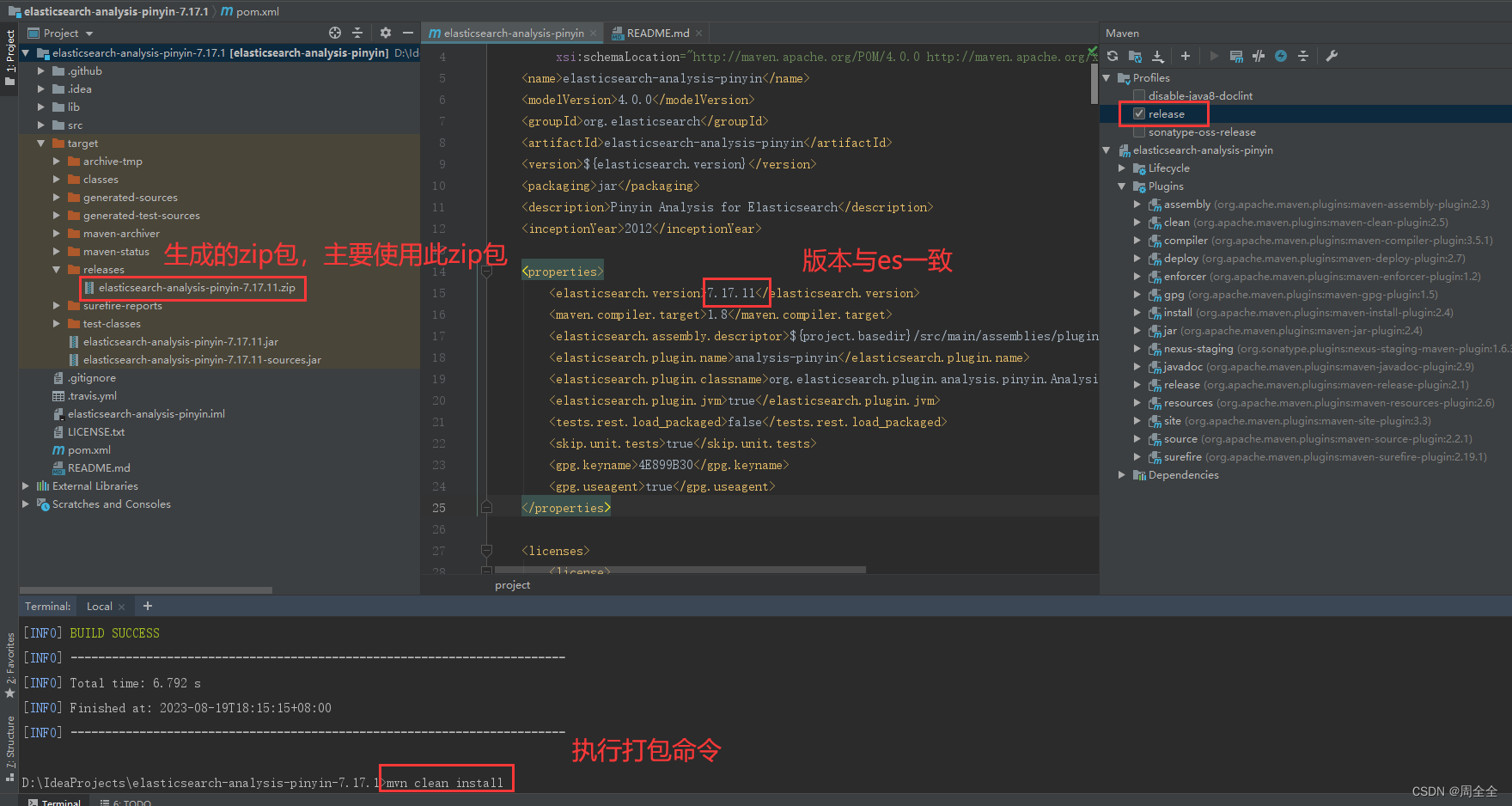
elasticsearch-analysis-pinyin分词器目前没有下载即可使用的安装包,需要自己下载源码进行编译。可以在项目目录elasticsearch-analysis-pinyin\target\releases看到编译后的结果elasticsearch-analysis-pinyin-7.17.11.zip
2.2 安装拼音插件
然后在es的安装目录下plugins目录下新建pinyin目录,并将解压后的文件复制到该目录下

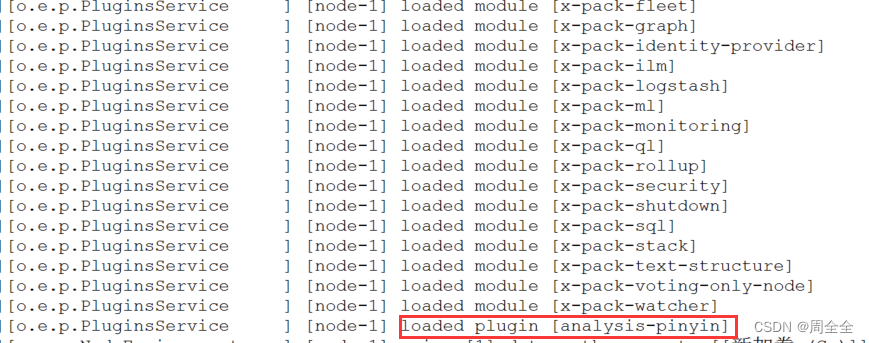
重启es,启动日志中已经加载了拼音插件
3. 引入ik分词器插件
github下载地址:releases · infinilabs/analysis-ik · github
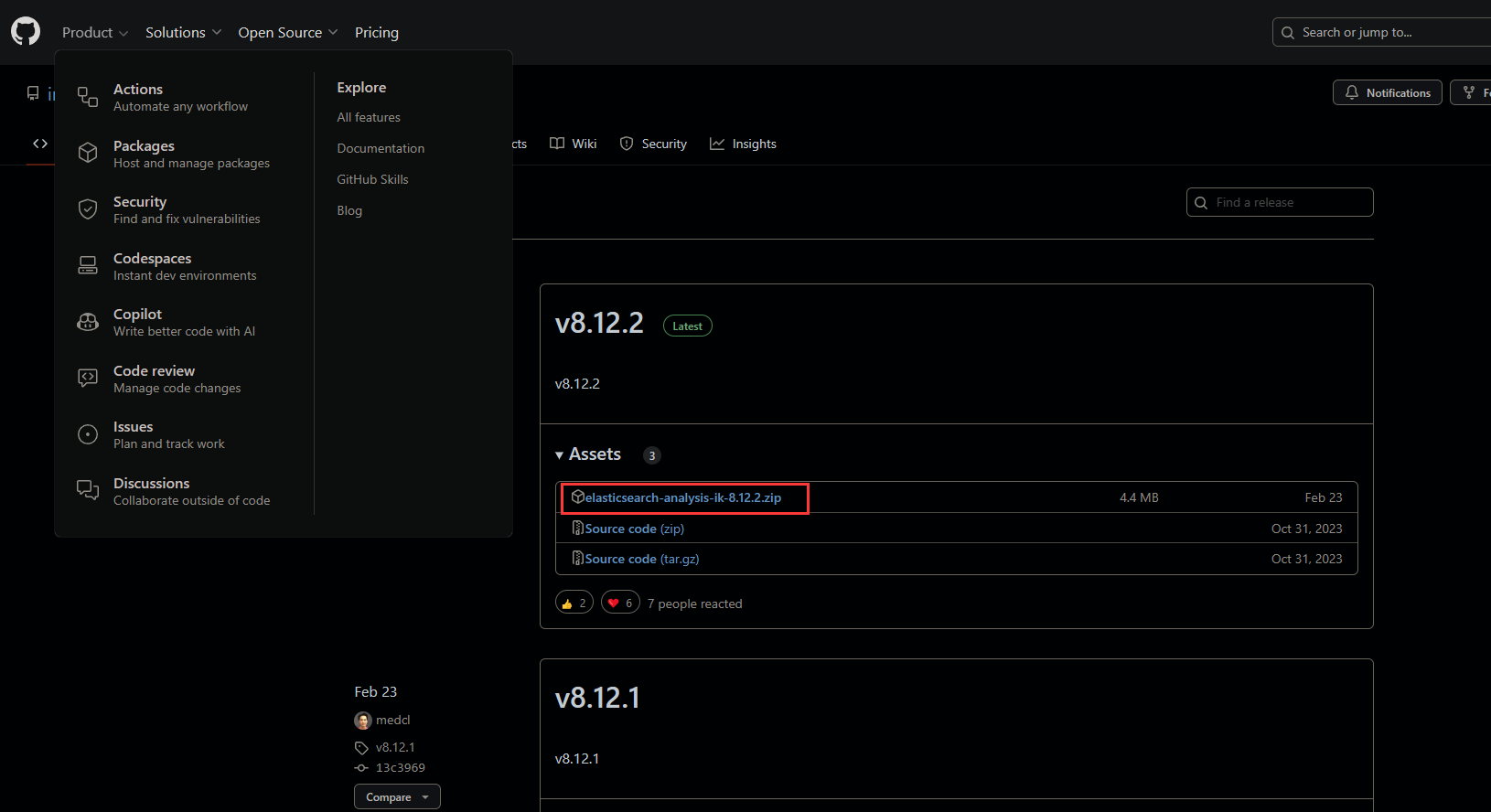
3.1 已有作者编译后的包文件
选择与所需es版本相同的ik分词器,下载已经打包后的.zip文件
3.2 只有源代码的版本
首先下载源码解压后使用idea打开,修改es版本与分词器版本相同

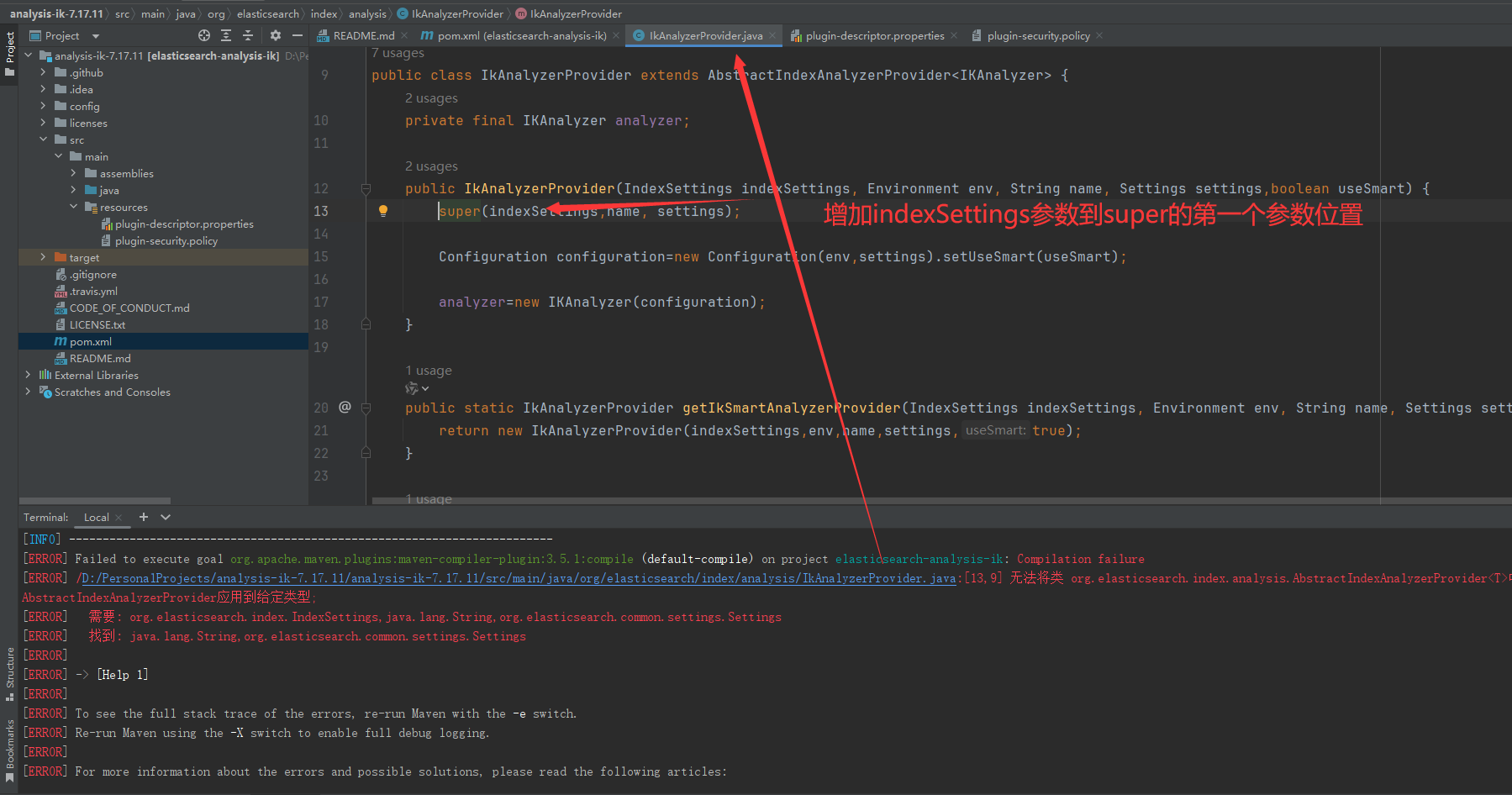
使用 mvn clean install 打包时报错:
[error] failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.5.1:compile (default-compile) on project elasticsearch-analysis-ik: compilation failure
[error] /d:/personalprojects/analysis-ik-7.17.11/analysis-ik-7.17.11/src/main/java/org/elasticsearch/index/analysis/ikanalyzerprovider.java:[13,9] 无法将类 org.elasticsearch.index.analysis.abstractindexanalyzerprovider<t>中的构造器
abstractindexanalyzerprovider应用到给定类型;
[error] 需要: org.elasticsearch.index.indexsettings,java.lang.string,org.elasticsearch.common.settings.settings
[error] 找到: java.lang.string,org.elasticsearch.common.settings.settings
修改代码报错部分:增加indexsetting参数到super入参的第一个位置
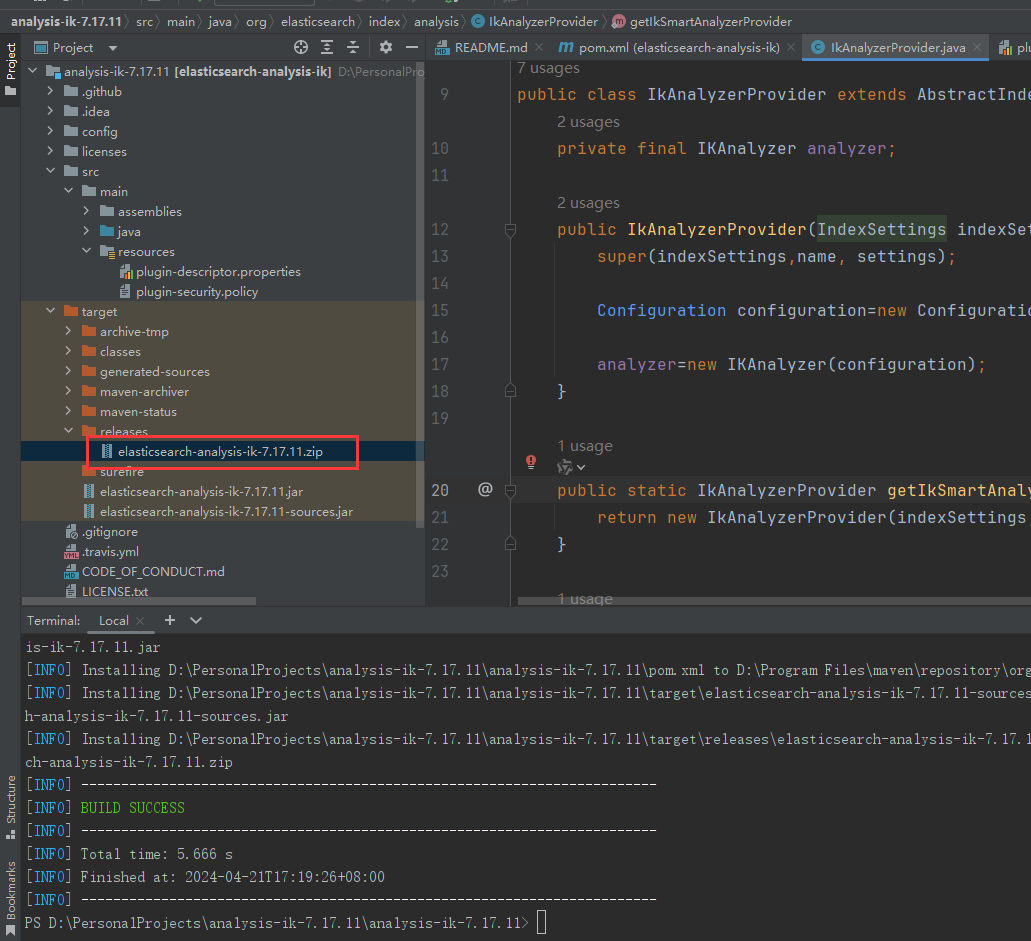
使用mvn clean install进行打包,注意我们所需的是/target/release目录下的.zip压缩包
3.3 安装ik分词插件
将下载或者编译后的.zip文件解压到es的安装目录下的plugins目录下,并重命名为ik
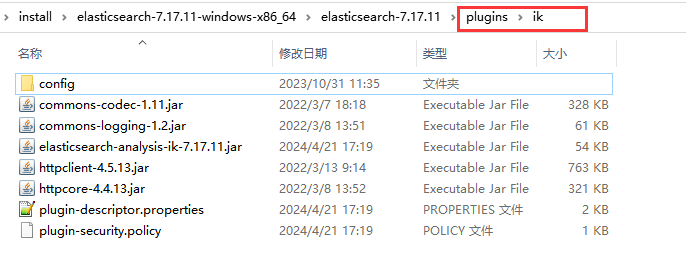
然后启动es,查看日志可发现已经加载的ik分词器
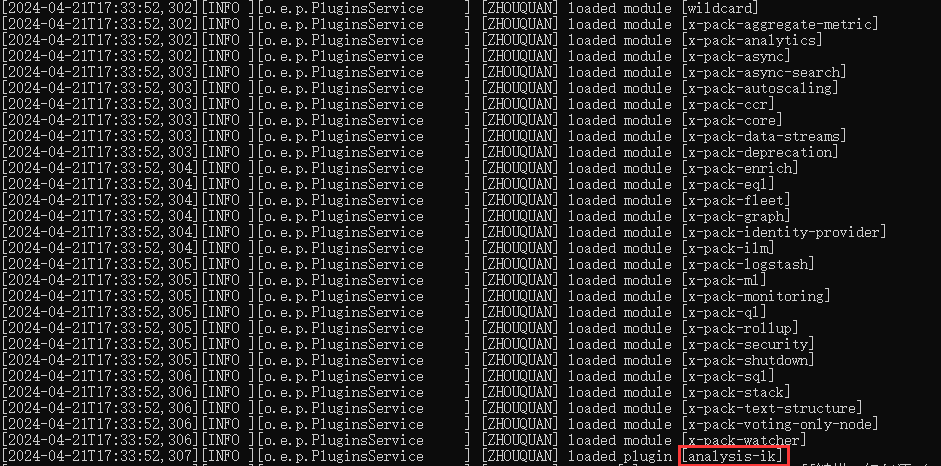
常规的最常用的使用方式就是,数据插入存储时用 ik_max_word模式分词,而检索时,用ik_smart模式分词,即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
建立映射示例如下:在数据被索引时我们设置"analyzer": “ik_max_word”,在检索时指定"search_analyzer": “ik_smart”
4. 建立es索引
setting.json
{
"aliases": {
},
"settings": {
"index": {
"refresh_interval": "3s",
"number_of_shards": "3",
"number_of_replicas": "1",
"max_inner_result_window": "10000",
"max_result_window": "20000",
"analysis": {
"filter": {
"pinyin_full_filter": {
"keep_joined_full_pinyin"



发表评论