文章目录
一、redis主从架构锁失效问题分析
我们都知道,一般的互联网公司redis部署都是主从结构的,那么复制基本都是异步执行的,那就存在一个问题,当我们设置分布式锁的时候,还没来得及将key复制到从节点,主节点挂了,那么从节点会成为主节点,但是主节点的分布式锁key就会丢失掉,如果新线程进来执行同步代码同样会导致超卖问题
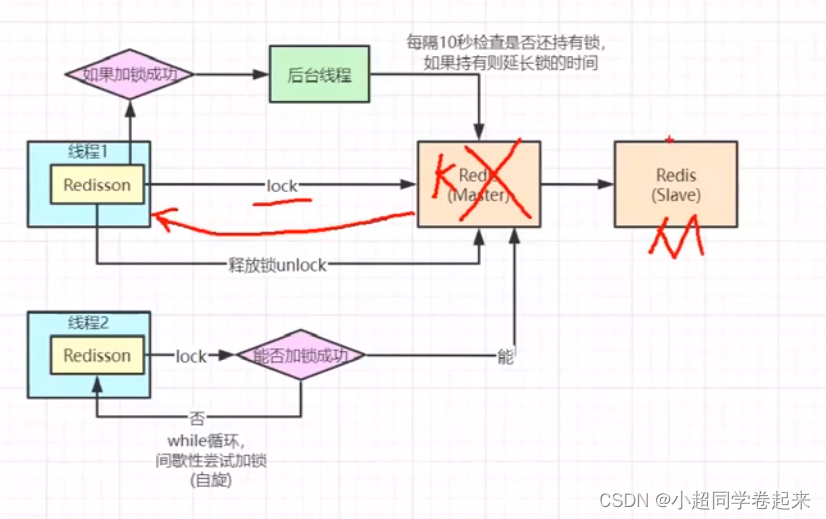
那么这个问题想解决,其实并没有那么容易
二、从cap角度剖析redis与zookeeper分布式锁区别
我们知道zk也能实现分布式锁,他是怎么实现的呢?
首先zk会有一个leader节点,还会有多个flow节点(类似于redis的master和slave),当我们在leader节点设置一把分布所锁的时候,leader节点不会立即将设置的结果返回客户端,leader会从其flow节点去复制key,当flow复制成功key返回信息给leader节点的时候,leadfer会统计一个同步的数量,当这个数量超过半数的时候,才会返回给客户端表示这把分布式锁设置成功了。
那么zk就不会存在因为主从节点切换导致的分布式锁生效的问题
从cap角度看,redis更多满足的是ap(可用性和容错性),zk是cp的(一致性和容错性)
但是redis的性能会比zk好,zk从语义角度更适合作为分布式锁的工具
三、redlock分布式锁原理与存在的问题分析
我相信很多同学都听过网上的很多人说利用红锁去解决redis的主从结构带来的分布式锁失效的问题,其实并没有完全解决!
红锁的实现原理是什么呢?
红锁是基于不是主从节点的redis实现,假设又奇数个redis节点,都是平等的,不存在主从,其实也是跟zk的底层实现机制是一样的,也是基于半数的加锁的原理。
红锁牺牲了一些可用性,因为需要往不同的节点去写key,需要半数以上的节点返回,那么客户端是需要等待一下的。但是在c可用性上更加友好一点
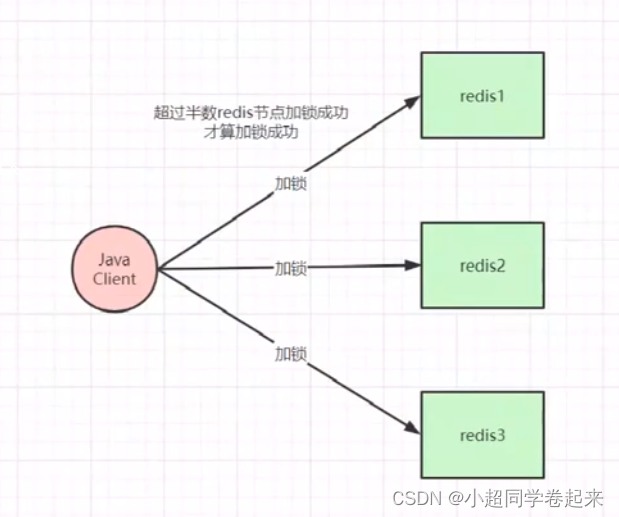
但是红锁并没有真正解决分布式锁失效问题
如果每个主节点都拖一个从节点(为了高可用),这样还是会有之前说的问题,redis1同步成功,redis2同步失败,从节点变为主节点;那么redis的从节点中依然没有key,其他线程进来依然可以超过半数去设置分布式锁
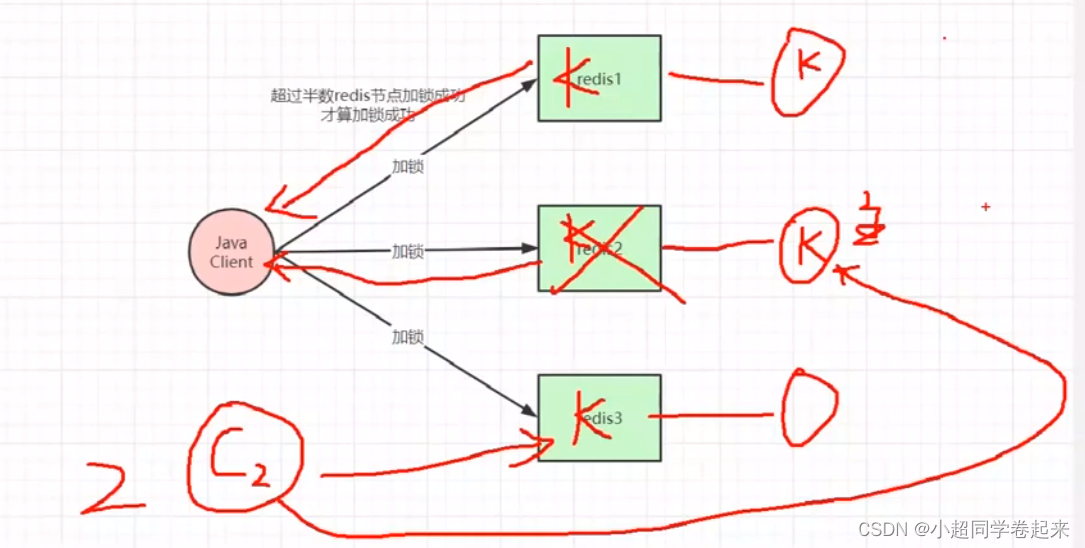
那如果不搞从节点,那就可能reids挂了超过一半的节点,那么分布式锁就没法使用了;
可能有人会说我们多搞几个节点,总不会那么多节点都挂掉吧,那我们想想,搞那么多节点,redis写key是不是也得消耗很多性能,我们使用redis的初衷就变了,那还不如用zk
然后会存在一个问题,redis持久化(aof)的时候,我们一般都会设置为1s去持久化,而不是每条写 命令都去持久化。但是这1s的数据有可能会丢失,所以如果加锁redis1,redis2都成功了的时候,刚好在持久化的这1s中,redis2宕机了,那么redis2 的key就会丢失,依然存在问题
所以说红锁并不能100%解决分布式锁问题
四、大促场景如何将分布式锁性能提升100倍
首选考虑锁的粒度,控制锁住的代码块越小越好。
然后可以设置分段锁,比如某个商品1000个,分布式锁会基于这1000的库存去实现;那么利用分段锁,可以将商品分为100一段的十段,利用10个锁去针对这一个商品实现分布式锁,这10把锁相互之间不会存在并发问题。但是每把锁都是基于100的库存,性能会显著提升。(类似于1.7版本的concruuenthashmap底层原理)
五、高并发redis架构代码实战
public class productservice {
@autowired
private productdao productdao;
@autowired
private redisutil redisutil;
@autowired
private redisson redisson;
public static final integer product_cache_timeout = 60 * 60 * 24;
public static final string empty_cache = "{}";
public static final string lock_product_hot_cache_prefix = "lock:product:hot_cache:";
public static final string lock_product_update_prefix = "lock:product:update:";
public static map<string, product> productmap = new concurrenthashmap<>();
@transactional
public product create(product product) {
product productresult = productdao.create(product);
redisutil.set(rediskeyprefixconst.product_cache + productresult.getid(), json.tojsonstring(productresult),
genproductcachetimeout(), timeunit.seconds);//写入数据库之后,redis写缓存,并设置超时时间
// (超时时间设置为1天+随机5h以内的时间,目的是为了了防止那些批量上架的商品同时过期,避免缓存失效(击穿)导致同时有大量请求打到数据库)
return productresult;
}
@transactional
public product update(product product) {
product productresult = null;
//rlock updateproductlock = redisson.getlock(lock_product_update_prefix + product.getid());
rreadwritelock readwritelock = redisson.getreadwritelock(lock_product_update_prefix + product.getid());//针对更新方法设置分布式锁(分布式写锁)
rlock writelock = readwritelock.writelock();
writelock.lock();//保证了在更新数据库和更新缓存之间不会有其他线程过来更新操作,保证双写一致
try {
productresult = productdao.update(product);
redisutil.set(rediskeyprefixconst.product_cache + productresult.getid(), json.tojsonstring(productresult),
genproductcachetimeout(), timeunit.seconds);
productmap.put(rediskeyprefixconst.product_cache + productresult.getid(), product);//往jvm本地缓或者ehcache存放一份数据(为了应对百万并发场景,redis最多支持10w并发
//如果redis挂了,会导致雪崩 )
} finally {
writelock.unlock();
}
return productresult;
}
public product get(long productid) throws interruptedexception {
product product = null;
string productcachekey = rediskeyprefixconst.product_cache + productid;
product = getproductfromcache(productcachekey);//先从缓存拿数据
if (product != null) {
return product;//拿到了就直接返回,需要跟前端沟通,如果是空的商品就 友好提示
}
//dcl 针对冷门数据突然变热的场景
rlock hotcachelock = redisson.getlock(lock_product_hot_cache_prefix + productid);//为了针对热点商品设置的分布式锁锁
//因为大量请求过来,第一次缓存肯定没数据,都会去请求db,那就不合理;加锁只让一个线程去访问数据库,将数据写入缓存,其他线程在锁释放之后会直接去访问缓存
hotcachelock.lock();
//boolean result = hotcachelock.trylock(3, timeunit.seconds);
try {
product = getproductfromcache(productcachekey);//其余线程进来从缓存拿到数据
if (product != null) {
return product;
}
//rlock updateproductlock = redisson.getlock(lock_product_update_prefix + productid);
rreadwritelock readwritelock = redisson.getreadwritelock(lock_product_update_prefix + productid);//读写锁是为了 如果都是读请求的话能保证并行执行,只有写操作才会阻塞
rlock rlock = readwritelock.readlock();//同样是为了查询数据库和更新缓存保证不被其他线程影响
rlock.lock();//读锁的原理是 利用的锁重入的方法,每次都+1
try {
product = productdao.get(productid);
if (product != null) {
redisutil.set(productcachekey, json.tojsonstring(product),
genproductcachetimeout(), timeunit.seconds);
productmap.put(productcachekey, product);
} else {
redisutil.set(productcachekey, empty_cache, genemptycachetimeout(), timeunit.seconds);//设置空缓存,防止黑客
}
} finally {
rlock.unlock();
}
} finally {
hotcachelock.unlock();
}
return product;
}
private integer genproductcachetimeout() {
return product_cache_timeout + new random().nextint(5) * 60 * 60;
}
private integer genemptycachetimeout() {
return 60 + new random().nextint(30);
}
private product getproductfromcache(string productcachekey) {
product product = productmap.get(productcachekey);//从缓存拿数据之前 先从jvm内存呢拿数据,针对百万并发场景
if (product != null) {
return product;
}
string productstr = redisutil.get(productcachekey);
if (!stringutils.isempty(productstr)) {
if (empty_cache.equals(productstr)) {//如果拿到的是空的数据,说明是为了防止恶意请求导致缓存穿透而设置的
redisutil.expire(productcachekey, genemptycachetimeout(), timeunit.seconds);//那就刷新过期时间
return new product();//返回空的商品信息
}
product = json.parseobject(productstr, product.class);
redisutil.expire(productcachekey, genproductcachetimeout(), timeunit.seconds); //读延期,热门的数据会一直在缓存中,冷门的数据到时间就过期了,实现了简单了数据冷热分离
}
return product;
}
}


发表评论