腾讯云多kubernetes集群高可用运维实践
引言
在现代云计算环境中,高可用性(ha)是确保服务连续性和可靠性的重要方面。特别是在多kubernetes集群的场景下,高可用运维实践更显得尤为关键。本文基于《腾讯云多kubernetes集群高可用运维实践》文档,结合最新的互联网技术知识,探讨腾讯云多kubernetes集群的高可用运维最佳实践,提供技术指标、具体需求、解决问题的路径和操作案例。
本文参考资料,收录于《运维资料合集》专栏,包含100+运维相关资料,专栏地址在文末获取
多kubernetes集群高可用性指标
在设计和实现多kubernetes集群的高可用性时,需要考虑以下关键指标:
- 故障切换时间(failover time):从一个节点或服务发生故障到系统切换到备份节点或服务的时间,建议目标为30秒以内。
- 恢复时间目标(rto):从系统故障到恢复正常运行的时间,建议目标为5分钟以内。
- 恢复点目标(rpo):在灾难发生时,允许的数据丢失量,建议目标为0,即不允许数据丢失。
- 可用性百分比:系统在给定时间段内的可用性,建议目标为99.99%(四个九),即每年约52.56分钟的停机时间。
- 系统容错能力:系统在硬件、软件或网络故障发生时,仍然能够正常运行的能力,建议每个集群至少有50%的冗余节点。
多kubernetes集群高可用性需求
- 冗余和容错设计:每个集群应至少有一个备份集群,以确保在主集群故障时,能够迅速切换到备份集群。
- 自动化运维工具:利用自动化工具(如ansible、terraform等)进行集群的部署和管理,提高效率和一致性。
- 持续监控和告警:使用prometheus、grafana等监控工具,对集群健康状况进行实时监控,并设置告警机制,及时发现并处理异常。
- 数据备份和恢复:定期对重要数据进行备份,并测试数据恢复机制,确保在发生数据丢失时能够快速恢复。
解决问题的路径
1. 集群架构设计
设计多kubernetes集群的架构时,需要考虑集群之间的网络连接、数据同步和服务切换等问题。可以采用跨地域的多可用区(az)部署,增强系统的容灾能力。具体操作如下:
- 跨地域部署:在不同地域创建多个kubernetes集群,通过vpn或专线实现跨地域网络连接,确保集群之间的通信畅通。
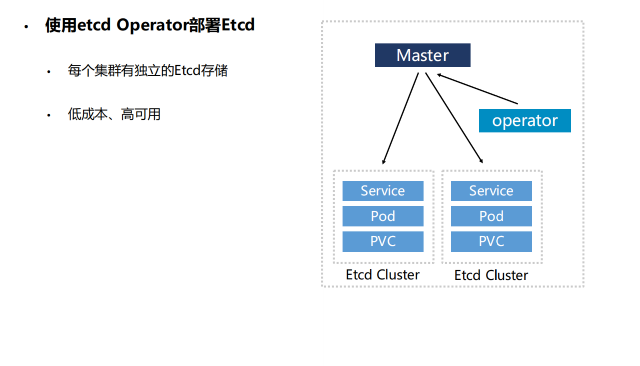
- 数据同步:使用etcd的集群同步机制,确保各个集群的状态一致。可以配置etcd集群跨地域同步,确保数据的实时性和一致性。
apiversion: v1
kind: pod
metadata:
name: etcd
spec:
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.3.12
ports:
- containerport: 2379
- containerport: 2380
volumemounts:
- mountpath: /etcd-data
name: etcd-data
volumes:
- name: etcd-data
emptydir: {}
2. 容器编排与调度
利用kubernetes的调度策略,合理分配资源,确保应用负载均衡,并实现故障隔离。可以配置pod的反亲和性策略,避免pod集中部署在同一个节点上。具体操作如下:
apiversion: v1
kind: pod
metadata:
name: myapp-pod
spec:
affinity:
podantiaffinity:
requiredduringschedulingignoredduringexecution:
- labelselector:
matchexpressions:
- key: app
operator: in
values:
- myapp
topologykey: "kubernetes.io/hostname"
containers:
- name: myapp-container
image: myapp:latest
ports:
- containerport: 80
3. 服务发现与负载均衡
使用kubernetes自带的服务发现机制和负载均衡器,如coredns和ingress controller,确保服务的高可用性。具体操作如下:
apiversion: v1
kind: service
metadata:
name: myapp-service
spec:
selector:
app: myapp
ports:
- protocol: tcp
port: 80
targetport: 9376
type: loadbalancer
4. 安全和权限管理
采用rbac(基于角色的访问控制)和网络策略,确保集群的安全性,防止未授权的访问和攻击。具体操作如下:
apiversion: rbac.authorization.k8s.io/v1
kind: role
metadata:
namespace: default
name: pod-reader
rules:
- apigroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
---
apiversion: rbac.authorization.k8s.io/v1
kind: rolebinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: user
name: jane
apigroup: rbac.authorization.k8s.io
roleref:
kind: role
name: pod-reader
apigroup: rbac.authorization.k8s.io
具体操作案例
案例1:跨地域多集群部署
- 部署多集群:在不同地域创建多个kubernetes集群,确保各个集群之间的网络连通性。
- 配置联邦集群:利用kubernetes federation,将多个集群纳入统一管理,确保应用可以跨集群部署和调度。
- 设置备份与恢复策略:定期备份各个集群的etcd数据,并在灾难发生时,能够快速恢复。
案例2:实现自动化运维
- 使用terraform:编写terraform脚本,自动化创建和配置kubernetes集群,包括vpc、子网、安全组等资源。示例如下:
provider "tencentcloud" {
secret_id = "your_secret_id"
secret_key = "your_secret_key"
region = "ap-guangzhou"
}
resource "tencentcloud_vpc" "my_vpc" {
name = "my_vpc"
cidr_block = "10.0.0.0/16"
}
resource "tencentcloud_kubernetes_cluster" "my_cluster" {
cluster_name = "my_cluster"
vpc_id = tencentcloud_vpc.my_vpc.id
subnet_ids = [tencentcloud_subnet.my_subnet.id]
cluster_basic_settings {
cluster_os = "ubuntu16.04.1 ltsx86_64"
}
cluster_network_settings {
cluster_cidr = "172.16.0.0/16"
}
cluster_instance_settings {
instance_type = "s2.small1"
image_id = "img-8toqc6s3"
}
}
- 利用ansible:编写ansible playbook,实现集群的日常运维操作,如升级、扩容和备份等。示例如下:
- name: update kubernetes nodes
hosts: k8s_nodes
tasks:
- name: upgrade all packages
apt:
upgrade: dist
- name: restart kubelet
systemd:
name: kubelet
state: restarted
- 监控和告警配置:部署prometheus和grafana,配置集群的监控和告警规则,确保及时发现和处理故障。示例如下:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
结论
多kubernetes集群的高可用运维实践需要从架构设计、自动化运维、监控告警和数据备份等多个方面入手,结合实际需求,制定合理的策略和实施方案。通过本文提供的最佳实践和具体操作案例,希望能为企业在实际运维过程中提供有价值的参考和指导。
参考资料预览(部分)
腾讯云多kubernetes集群高可用运维实践

参考资料&资料下载
| 文件名 | 地址(复制到浏览器访问) | 二维码(扫码下载) |
|---|---|---|
| 腾讯云多kubernetes集群高可用运维实践 | https://pduola.com/file/8,2a57115a7b43 |  |

最后
公众号 内回复【专栏】即可获取专栏地址
- 我已整理成多个专栏,包含
100+运维服务管理资料专栏、30+互联网安全资料专栏、30+技术方案专栏、40+数据资产&大数据合集专栏



发表评论