1 hdfs高可用架构原理
1.1 hdfs的基本架构
- namenode
- secondnamenode
- datanode
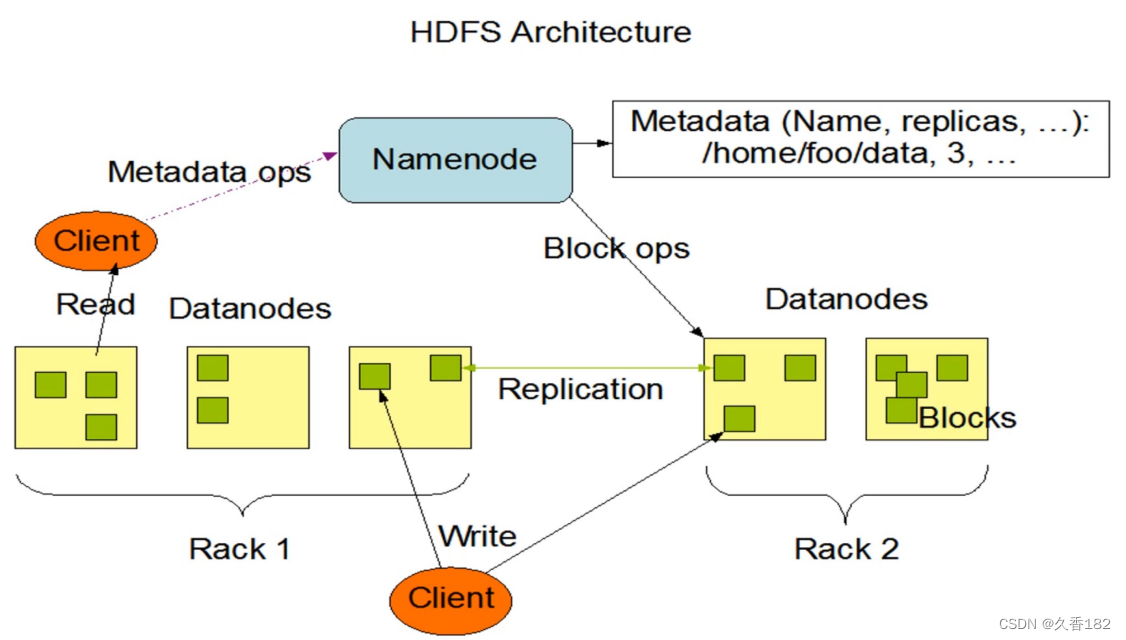
1.2 hdfs高可用架构
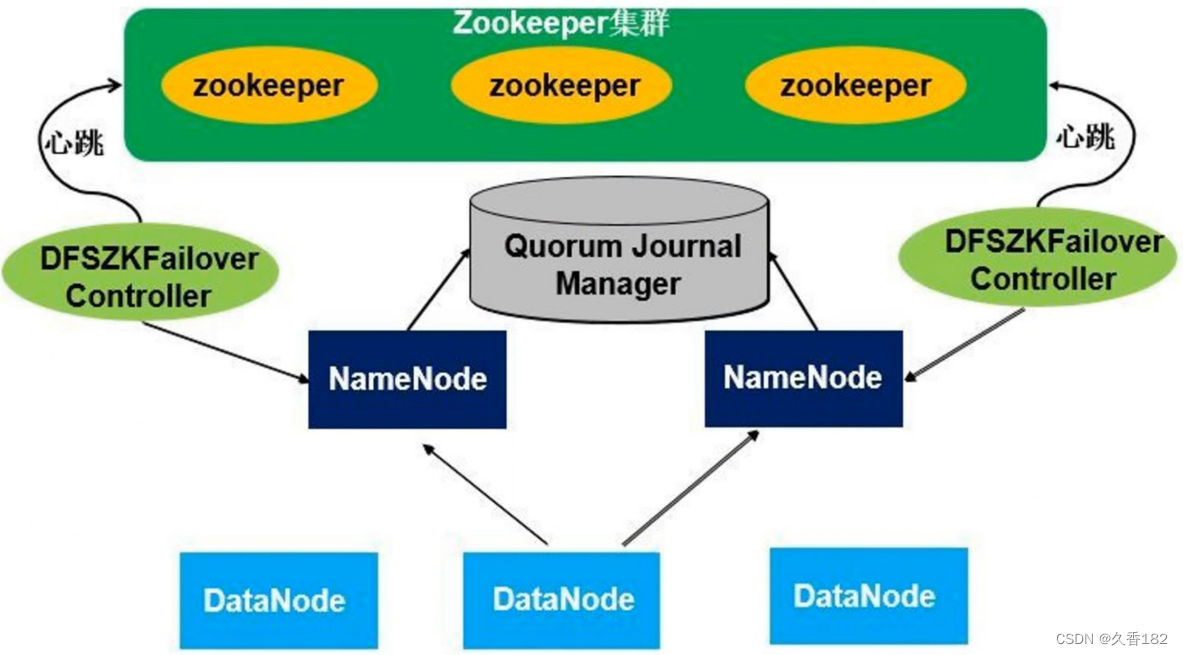
- 原本secondarynamenode功能是做检查点,把namenode上的fsimage和edit log文件定期进行合并,并且能有元数据信息合并的作用,但是没办法解决自动故障转移,在高可用架构里面就不需要配置secondarynamenode。
-
在高可用架构里面有两个 namenode ,这两个 namenode 地位平等,其中一个是主 namenode ,是active 状态,另外一个 namenode 是从, standby 状态。两个 namenode 同时启动,只有一个 namenode会进入工作状态。在任何时间点,其中之一 namenode 是处于 active 状态,另一种是在standby 状态。 active namenode 负责所有的客户端的操作,而 standby namenode 尽可能用来保存好足够多的状态,以提供快速的故障恢复能力。
-
所有的 datanode 节点会把自己的数据块信息同时向两个 namenode 汇报。
-
dfszkfailover controller(zkfc) :实时 namenode 的监控节点 ,zkfc 有两个,一个 zkfc 会监控一个特定的namenode 节点,把节点运行情况向 zookeeper 集群汇报。一旦 active namenode 发生故障,zkfc 可以监控到故障,并把情况报告给 zookeeper 集群,然后通过 zookeeper 的一些处理机制进行重新选举,把standby namenode 切换进入工作状态。
-
standby namenode 切换进入工作状态后,通过共享存储能立刻获取到当前集群的元数据信息, 并且它自身原本一直保存和 datanode 数据块信息,就可以立马接管整个集群的 namenode 工作。
-
quorum journal manager :共享存储,用于保存元数据信息,是多台机器组成的共享存储集群,集群中的每台机器称为journal node ( jn )。原本元数据信息是存储在 namenode硬盘,现在元数据信息存储在集群中的共享存储里面,这样可以保证元数据信息得到可靠的存储。
- 健康监控:一个namenode一个监控进程。周期性的向namenode发信息鉴定namenode是否在正常工作。如果机器宕机,心跳失败,那么zkfc就会标记它处于不健康的状态。
- 会话管理:如果namenode是健康的,zkfc机会保持在zookeeper中保持一个打开的会话,如果namenode是active状态的,那么zkfc还会在zookeeper中创建有一个类型为临时类型的 znode,当这个namenode挂掉时,这个znode将会被删除,然后备用的namenode得到这把锁,升级为主的namenode,同时标记状态为active,当宕机的namenode,重新启动,他会再次注zookeeper,发现已经有znode了,就自动变为standby状态。
- master选举:通过在zookeeper中维持一个临时类型的znode,使用独占锁机制,从而判断哪个namenode为active状态
2 hdfs高可用架构配置思路
- 完全分布式集群搭建
- zookeeper集群搭建
- 高可用相关节点配置
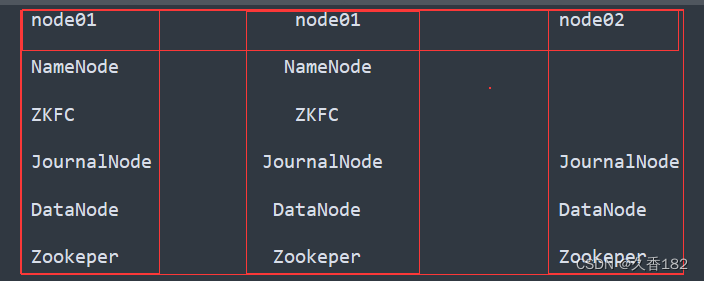
3 高可用配置工作
3.1 准备工作
3.1.1 环境准备工作
- 三台虚拟机
- hdfs完全分布式搭建
- zk集群搭建
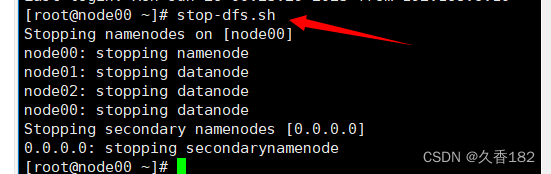
3.1.2 停止hadoop集群
3.1.3 停止zk集群
3.14 创建目录

3.1.5 删除之前系统产生的数据文件
- 删除/opt/software/hadoop/hdfs/name目录下的数据

- 删除/opt/software/hadoop/hdfs/tmp目录下的数据

- 删除/opt/software/hadoop/hdfs/data目录下的数据

3.1.6 安装psmisc
- 三台机器安装psmisc,程序切换需用到shell命令。
3.2 整体配置工作
- core-site.xml 实现一些与 hadoop 相关的核心配置
- hdfs-site.xml hdfs 相关的配置
3.3 core-site.xml
- fs.defaultfs配置需要修改为集群标识mycluster,集群标识在hdfs-site.xml内定义
- hadoop.tmp.dir配置不变化
- hadoop.http.staticuser.user配置新增
- ha.zookeeper.quorum配置新增,指向zk集群地址
<!-- 默认的文件系统hdfs,namenode主机通讯地址,配置集群标识定义在hdfs-site.xml里面 -->
<property>
<name>fs.defaultfs</name>
<value>hdfs://mycluster</value>
</property>
<!-- hadoop临时文件存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.9.2/tmp</value>
</property>
<!-- 网页方式进入管理页面,页面显示此用户相关数据 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 高可用集群指定的zk服务器信息 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node00:2181,node01:2181,node02:2181</value>
</property>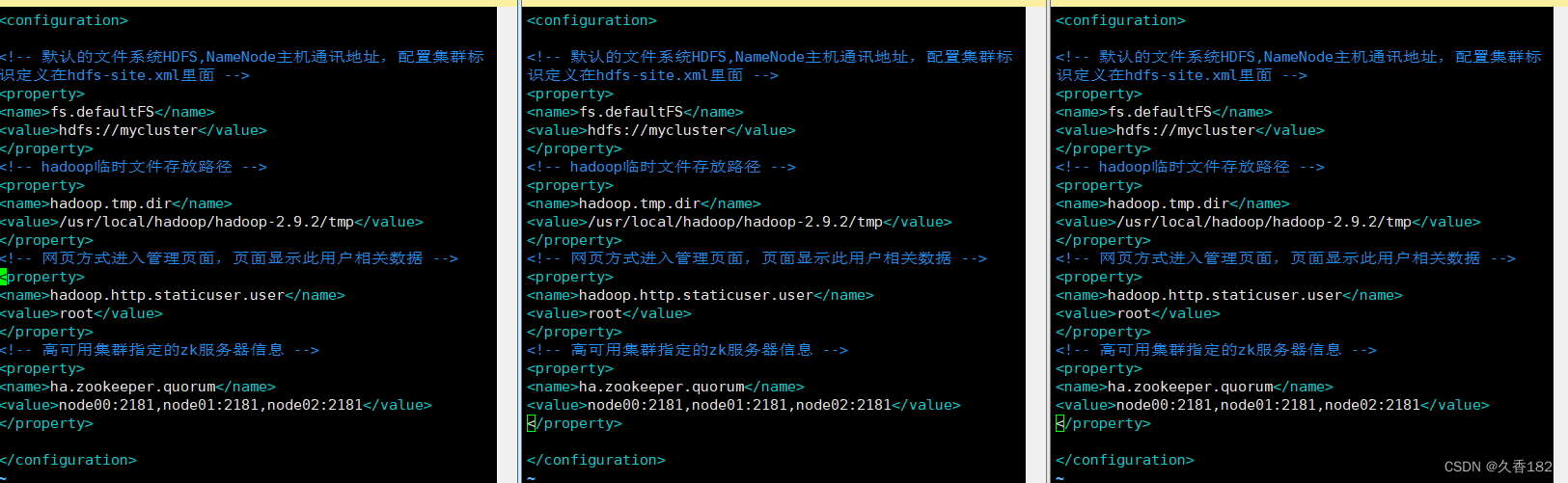
- fs.defaultfs原本是指向node00,高可用架构里面namenode会发生变化,所以此配置需修改成一 个标识
3.4 hdfs-site.xml
在原本的配置后面添加以下配置
<!-- 高可用架构下集群使用namenode,配置集群标识, mycluster -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- namenode节点标识 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- namenode1的rpc通讯端口号 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node00:8020</value>
</property>
<!-- namenode2的rpc通讯端口号 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node01:8020</value>
</property>
<!-- namenode1的http通讯端口号 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node00:50070</value>
</property>
<!-- namenode2的http通讯端口号 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node01:50070</value>
</property>
<!-- 配置共享存储 jn -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node00:8485;node01:8485;node02:8485/mycluster</value>
</property>
<!-- 配置失败转移执行类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider
</value>
</property>
<!-- 当进行切换时,通过何种机制杀死原先 active 的 namenode -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- ssh 私钥,上面杀掉原先进程使用sshfence方式需使用私钥 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- jn 存放元数据的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/software/hadoop/hdfs/journalnode/data</value>
</property>
<!-- 当namenode宕机,切换方式设置为自动 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>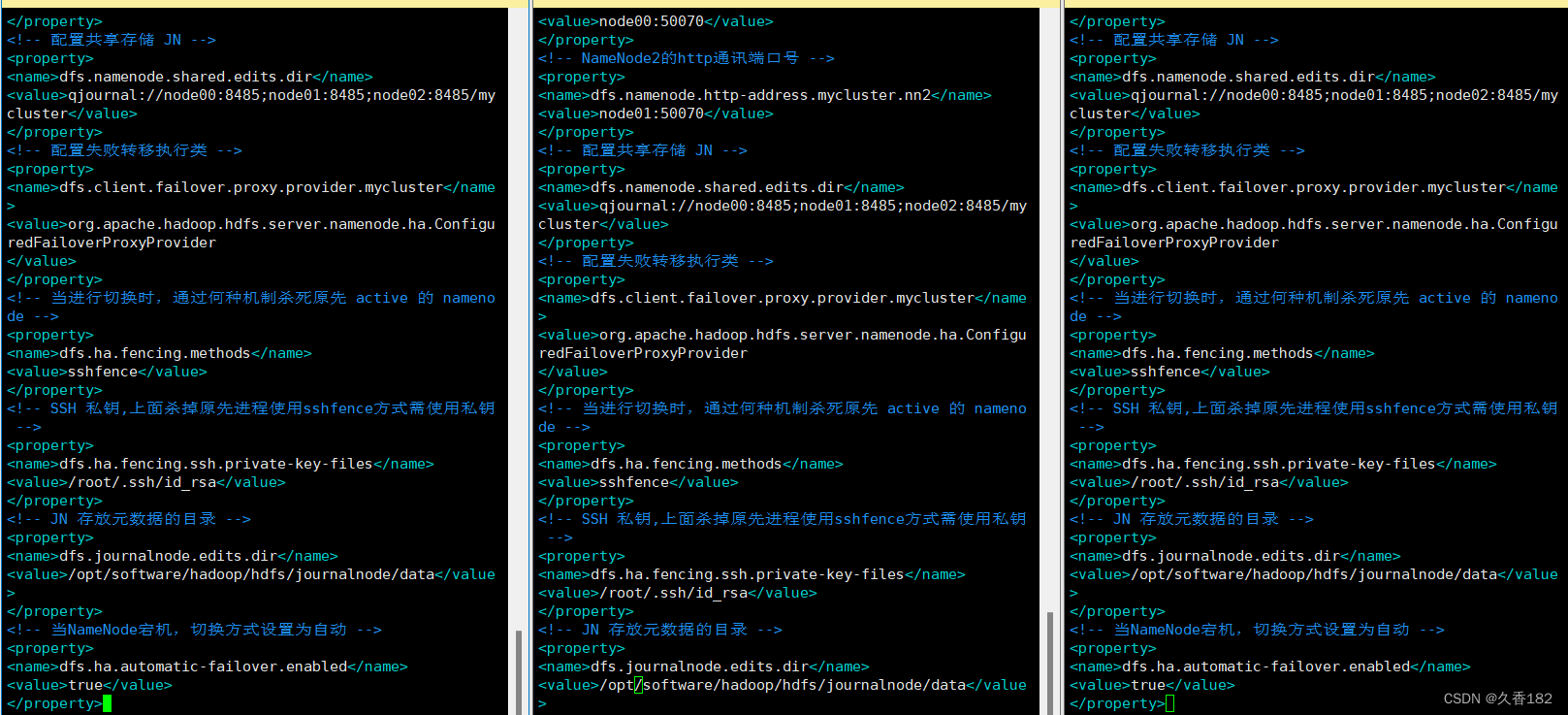
如果上面的步骤你只是在一台虚拟机上配置,可以看下面的第四章同步到node01,node02
4 同步配置
4.1 删除node01、node02的配置
4.2 同步配置
从
node00
把
hadoop
目录同步到
node01
和
node02
5 高可用集群启动
5.1 启动zk集群
- 三台机器执行以下命令启动zk集群
- 三台机器分别启动完成后再确认三台机器zk集群的启动情况。zkserver.sh status 和jps

5.2
启动
jn
节点
三台机器分别启动
jn
节点
第一次启动的时候需要在格式化之前分别启动三台,后面重启时则不需要

5.3
格式化
在
node00
上进行格式化注意注意
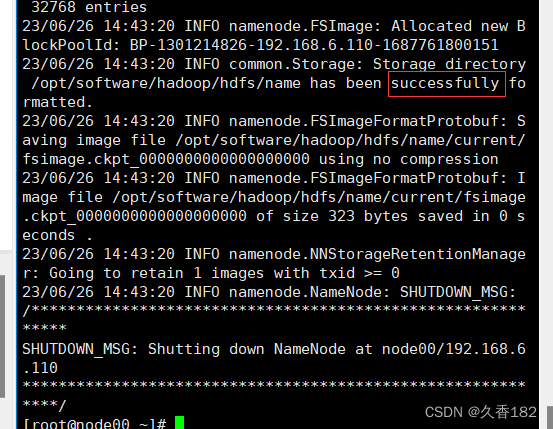
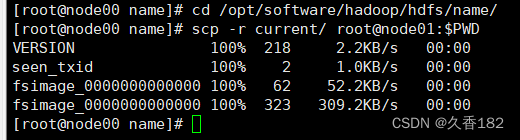
5.4
复制元数据
从
node01
的
hdfs/name/
目录下复制元数据到
node02
的对应目录
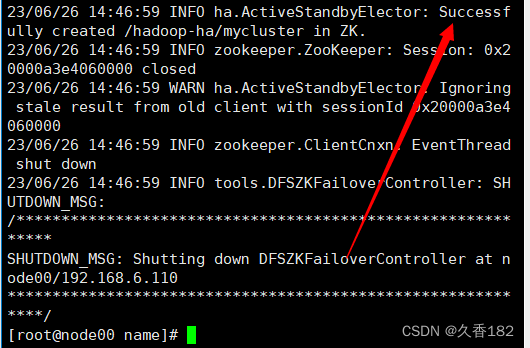
5.5 zkfc
格式化
在
node01
上进行
zkfc
格式化
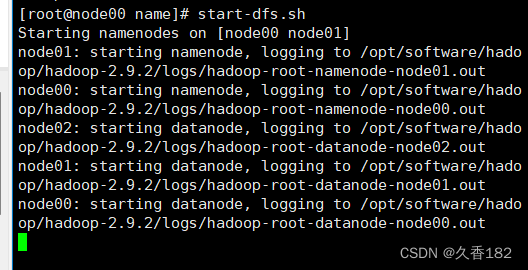
5.6
启动集群
在
node00
上启动注意注意
6
测试高可用集群
6.1 jps
查看启动情况
查看
3
台机器的进程

6.2 管理台查看


6.3
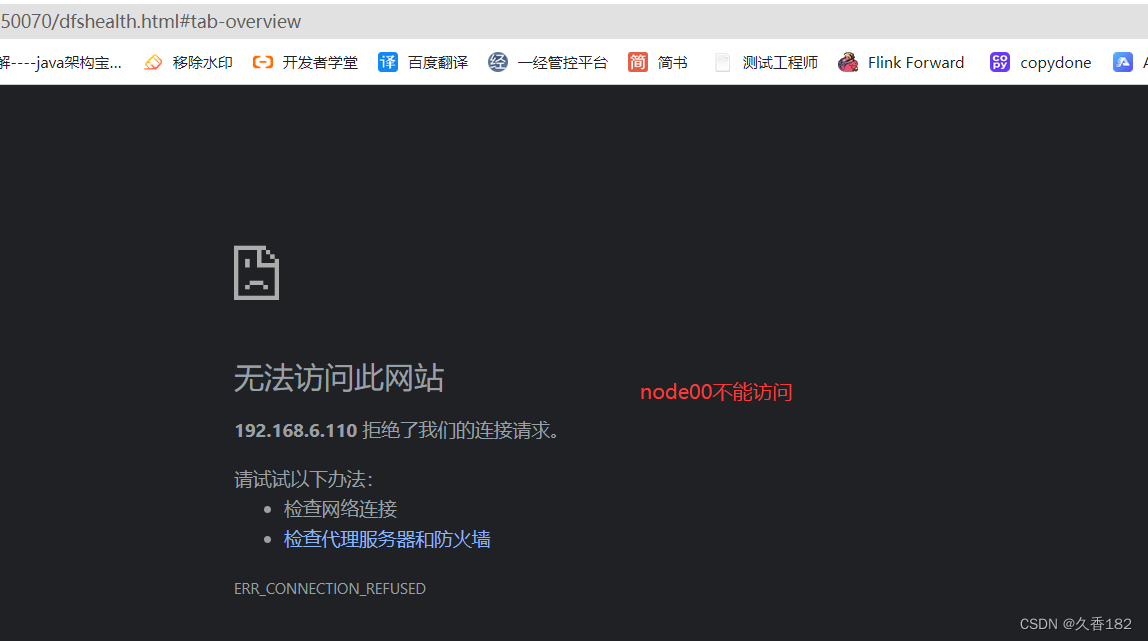
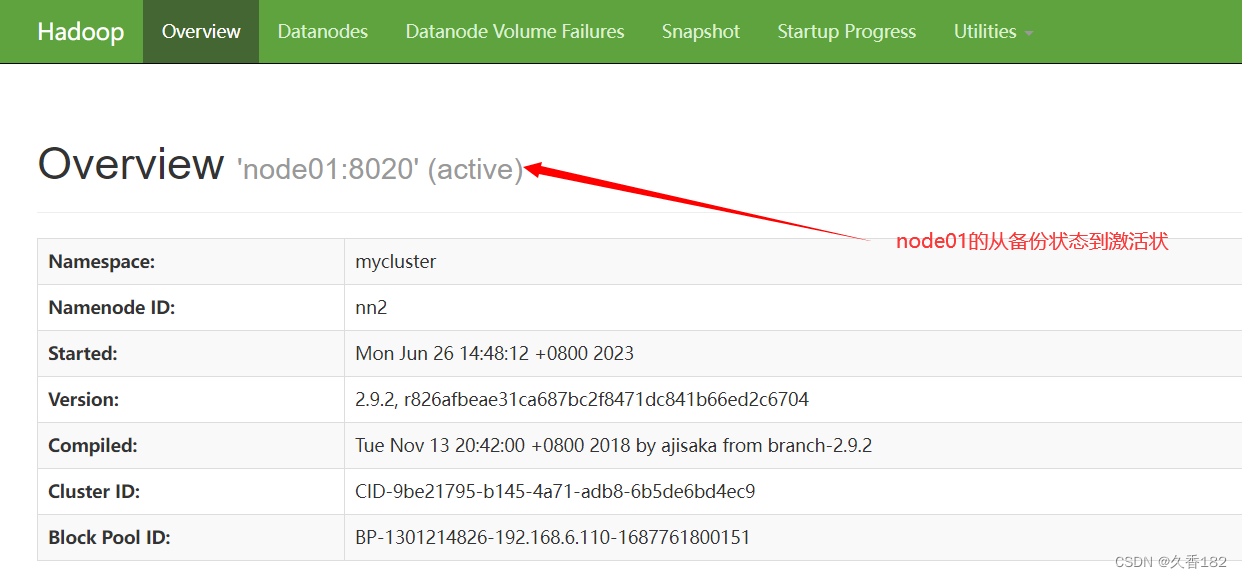
杀掉
active
节点
当前我的
node00
上的
namenode
节点是
active
状态,使用
kill
命令将其进行杀死,测试集群是否可
用


发表评论