前言
最近国产大模型kimi爆了大部分人应该都知道了,从我个人的感受来看这次kimi爆了我不是从技术领域接触到的,而是从各种金融领域接触到的。目前国内大模型可以说是百模大战,前几年新能源大战,今年资本割完韭菜后留给我们的是一家家倒闭或者即将要倒闭的车企,今年有一句话听了让人非常的无奈:"如果前几年你买了房子,又买了车子,你不仅要担心你的房子什么时候会爆雷还要担心你的车子什么时候会爆雷"。过几年大模型爆雷注定是不可避免不的,想想当年火爆的ofo到现在200多块钱的押金还没退给我。每次风口过后资本割完韭菜留给我们的都是一地鸡毛,所以我们一定要有自己的判断力,真正国货之光我们要去支持,那些套壳只为玩资本游戏的产品我们千万不要跟风,不要理会它就好了。关于kimi在资本市场已经火了,甚至还产生了kimi概念股。那么kimi到底怎么样?听别人说1000遍不如自己实际用一下,而且国产是开箱即用,比国外的使用门槛低多了。这次我们也不和外国的对比,也不和收费的对比,我们就和免费的文心一言和通义千问对比。
在此申明:本文6道题目为本人原创,在本文发表前网上是没有的,测试结果只能代表这三家大模型在这六道题目上的好坏,不能全面代表这三家大模型整体的优劣程度。
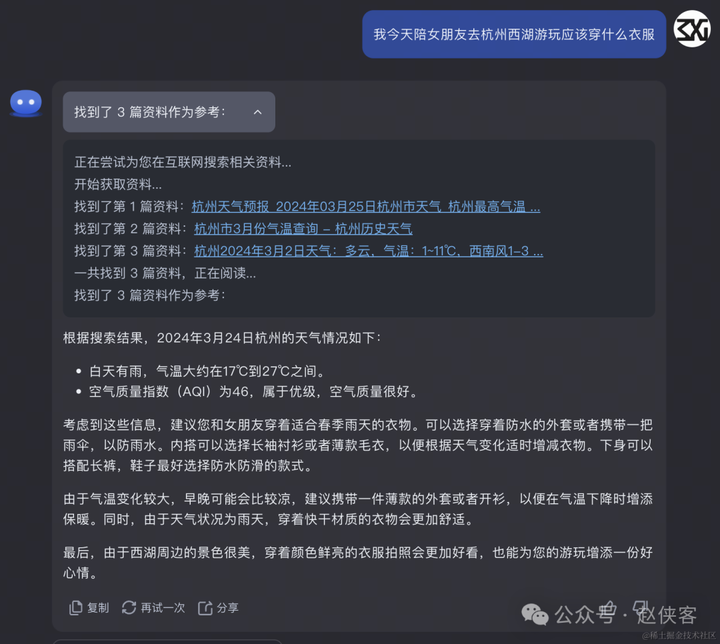
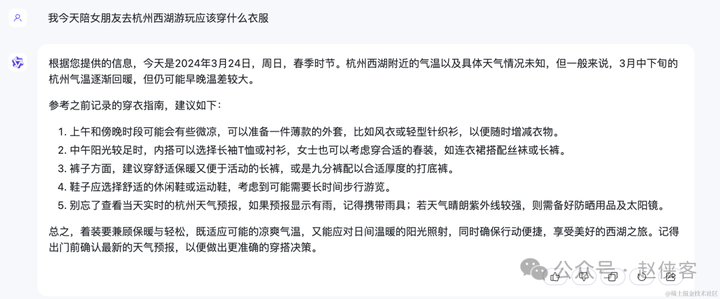
问题一:我今天陪女朋友去杭州西湖游玩应该穿什么衣服
kimi
添加图片注释,不超过 140 字(可选)
文心一言

添加图片注释,不超过 140 字(可选)
通义千问
添加图片注释,不超过 140 字(可选)
对比

添加图片注释,不超过 140 字(可选)
今天西湖边实际天气实拍
首先我们看一下杭州西湖今天的天气,温度是18-28度,多云,15点10%概率有雨,空气有点污染,接下来我们对比三家ai给出的答案:
-
通义千问:最拉垮,主要是没能获取今天杭州西湖的天气,给出的答案只是根据历史经验,所以没有什么参考价值;
-
文心一言:给出了杭州西湖的天气,包括气温、风力、空气质量为轻度污染都完全符合实际情况,而且建议结果分为1、2、3比较有条理,还对衣服的颜色给出来具体的配色,可以说非常好;
-
kimi:先从网上找到了三份关于杭州天气的网页,然后根据网页内容给出建议,只不过它所查询的天气并不是今天3月24号的,所以给出的答案也就有问题了,最大错误就是空气质量,它给出的是空气质量很好,实际情况是有点污染的,其次结果也没有百度文心一言有条理,对衣服的颜色也没有给出具体的配色,可以看出在这个问题上kimi是比文心一言差不少了。
小结
文心一言>kimi>通义千问
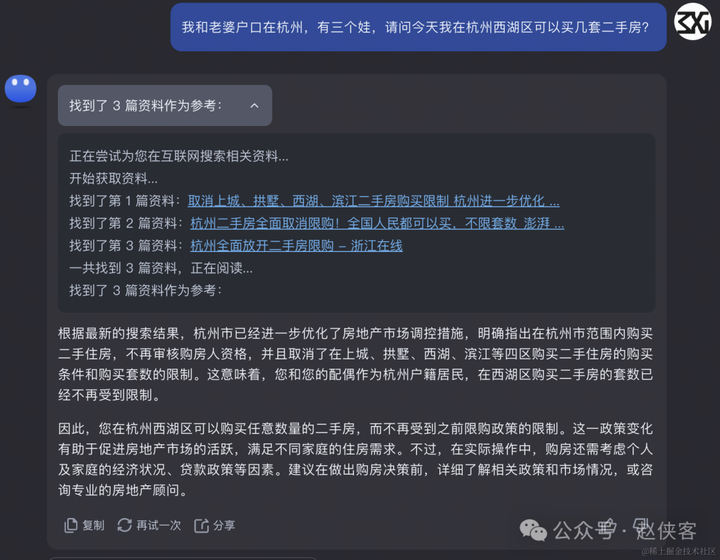
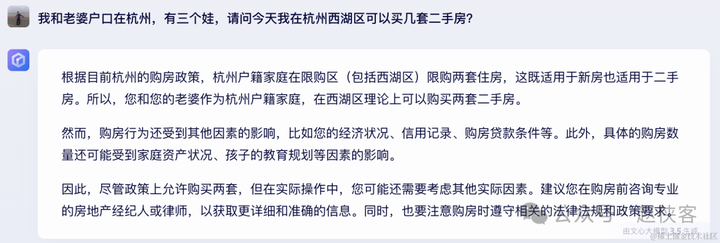
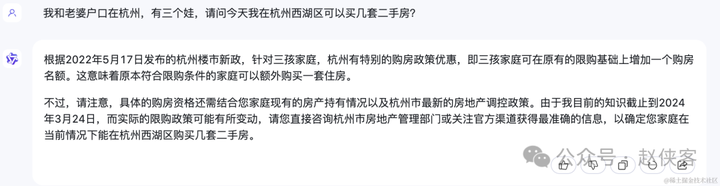
问题二:我和老婆户口在杭州,有三个娃,请问今天我在杭州西湖区可以买几套二手房?
kimi
添加图片注释,不超过 140 字(可选)
文心一言
添加图片注释,不超过 140 字(可选)
通义千问
添加图片注释,不超过 140 字(可选)
对比
杭州在3月14日取消了二手房限购。
-
通义千问:最拉垮的还是通义千问题,给出政策还是2022年5月17日的,也没给出具体可以购买几套房;
-
kimi:唯一给出正确答案。kimi这得益于他是实时从网上搜索的,而且正确搜索到了杭州取消二手房限购的网页,所以给出了正确的答案。
-
文心一言:应该没有更新杭州3月14取消二手房限购的内容,所以给出是的3月14日之前的答案,回答是错误的。
小结
kimi>文心一言>通义千问
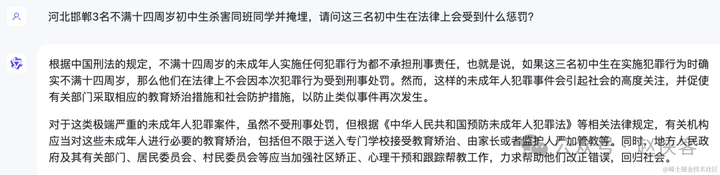
问题三、河北邯郸3名不满十四周岁初中生杀害同班同学并掩埋,请问这三名初中生在法律上会受到什么惩罚?
kimi

添加图片注释,不超过 140 字(可选)
文心一言

添加图片注释,不超过 140 字(可选)
通义千问
添加图片注释,不超过 140 字(可选)
对比
法律问题应该是送分题。
-
通义千问:还是最拉垮,没有给出答案;
-
文心一言:和kimi回答结果是一样的,但是在细节还是文心一言更强一点,给了具体的法律依据是《刑法》第十七条;
-
kimi:回答的和文心一言基本差不多。
小结
文心一言>kimi>通义千问
问题四、使用java代码合成部门树
[{
"id": 1,
"pid": 0,
"name": "产品研发中心"
},{
"id": 2,
"pid": 1,
"name": "后端"
},{
"id": 3,
"pid": 1,
"name": "前端"
},{
"id": 4,
"pid": 2,
"name": "java"
},{
"id": 5,
"pid": 3,
"name": "js"
}{
"id": 6,
"name": "测试数据"
}]
帮我通过id=pid合成部门树,请给出java代码
注意这里最后一条是故意造的错误数据。
kimi
import com.google.gson.gson;
import com.google.gson.reflect.typetoken;
import java.lang.reflect.type;
import java.util.arraylist;
import java.util.list;
import java.util.map;
import java.util.hashmap;
class department {
int id;
string name;
list<department> children = new arraylist<>();
public department(int id, string name) {
this.id = id;
this.name = name;
}
public void addchild(department child) {
children.add(child);
}
public static department fromjson(map<string, object> jsonmap) {
return new department((integer) jsonmap.get("id"), (string) jsonmap.get("name"));
}
}
public class departmenttreebuilder {
public static department buildtree(list<map<string, object>> departments) {
map<integer, department> departmentmap = new hashmap<>();
list<department> roots = new arraylist<>();
for (map<string, object> deptjson : departments) {
int id = (integer) deptjson.get("id");
string name = (string) deptjson.get("name");
department dept = department.fromjson(deptjson);
departmentmap.put(id, dept);
if (deptjson.get("pid").equals(0)) {
roots.add(dept);
}
}
for (map<string, object> deptjson : departments) {
int id = (integer) deptjson.get("id");
int pid = (integer) deptjson.get("pid");
if (pid != 0 && departmentmap.containskey(pid)) {
department dept = departmentmap.get(id);
department parent = departmentmap.get(pid);
if (parent != null) {
parent.addchild(dept);
}
}
}
return roots.isempty() ? null : roots.get(0); // assuming there is only one root
}
public static void main(string[] args) {
list<map<string, object>> departments = new arraylist<>();
departments.add(map.of("id", 1, "pid", 0, "name", "产品研发中心"));
departments.add(map.of("id", 2, "pid", 1, "name", "后端"));
departments.add(map.of("id", 3, "pid", 1, "name", "前端"));
departments.add(map.of("id", 4, "pid", 2, "name", "java"));
departments.add(map.of("id", 5, "pid", 3, "name", "js"));
department root = buildtree(departments);
string json = new gson().tojson(root);
system.out.println(json);
}
}
文心一言
public class departmenttreebuilder {
public static void main(string[] args) {
list<department> departments = new arraylist<>();
departments.add(new department(1, 0, "产品研发中心"));
departments.add(new department(2, 1, "后端"));
departments.add(new department(3, 1, "前端"));
departments.add(new department(4, 2, "java"));
departments.add(new department(5, 3, "js"));
departments.add(new department(6, 0, "测试数据")); // 注意这里pid应为0或其他实际父节点id,否则无法正确构建树形结构
list<department> tree = builddepartmenttree(departments);
for (department dept : tree) {
printdepartmenttree(dept, 0);
}
}
public static list<department> builddepartmenttree(list<department> departments) {
map<integer, department> idmap = new hashmap<>();
list<department> tree = new arraylist<>();
// 首先,将所有部门按照id放入map中,方便后续查找
for (department dept : departments) {
idmap.put(dept.getid(), dept);
}
// 遍历所有部门,构建树形结构
for (department dept : departments) {
if (dept.getpid() == 0) {
// pid为0的作为树的根节点
tree.add(dept);
} else {
// 查找父节点,并添加到父节点的子节点列表中
department parent = idmap.get(dept.getpid());
if (parent != null) {
if (parent.getchildren() == null) {
parent.setchildren(new arraylist<>());
}
parent.getchildren().add(dept);
}
}
}
return tree;
}
public static void printdepartmenttree(department dept, int level) {
for (int i = 0; i < level; i++) {
system.out.print("--");
}
system.out.println(dept.getname());
if (dept.getchildren() != null) {
for (department child : dept.getchildren()) {
printdepartmenttree(child, level + 1);
}
}
}
static class department {
private int id;
private int pid;
private string name;
private list<department> children;
public department(int id, int pid, string name) {
this.id = id;
this.pid = pid;
this.name = name;
}
public int getid() {
return id;
}
public int getpid() {
return pid;
}
public string getname() {
return name;
}
public list<department> getchildren() {
return children;
}
public void setchildren(list<department> children) {
this.children = children;
}
}
}
通义千问
class department {
int id;
int pid;
string name;
list<department> children = new arraylist<>();
department(int id, int pid, string name) {
this.id = id;
this.pid = pid;
this.name = name;
}
@override
public string tostring() {
return "department{" +
"id=" + id +
", pid=" + pid +
", name='" + name + ''' +
", children=" + children +
'}';
}
static department builddepartmenttree(list<department> depts) {
map<integer, department> map = new hashmap<>();
for (department dept : depts) {
map.put(dept.id, dept);
}
for (department dept : depts) {
if (map.containskey(dept.pid)) {
map.get(dept.pid).children.add(dept);
}
}
// 返回根节点(pid为0的部门)
return map.values().stream()
.filter(d -> d.pid == 0)
.findfirst()
.orelse(null);
}
public static void main(string[] args) {
list<department> depts = new arraylist<>();
depts.add(new department(1, 0, "产品研发中心"));
depts.add(new department(2, 1, "后端"));
depts.add(new department(3, 1, "前端"));
depts.add(new department(4, 2, "java"));
depts.add(new department(5, 3, "js"));
depts.add(new department(6, -1, "测试数据")); // 设置无效的pid为-1,表示该节点无父节点
department root = builddepartmenttree(depts);
system.out.println(root);
}
}
对比
-
通义千问:代码能正确执行,从写法上面来看通义千问代码量最少,还用了lambda表达示,看起来更高级,在代码生成领域终于胜出了;
-
kimi:这一题只有kimi给出答案是错的,department少了pid;
-
文心一言:代码能正确执行,没有通义千问生成的好。
小结
通义千问>文心一言>kimi
问题五、使用java处理数据
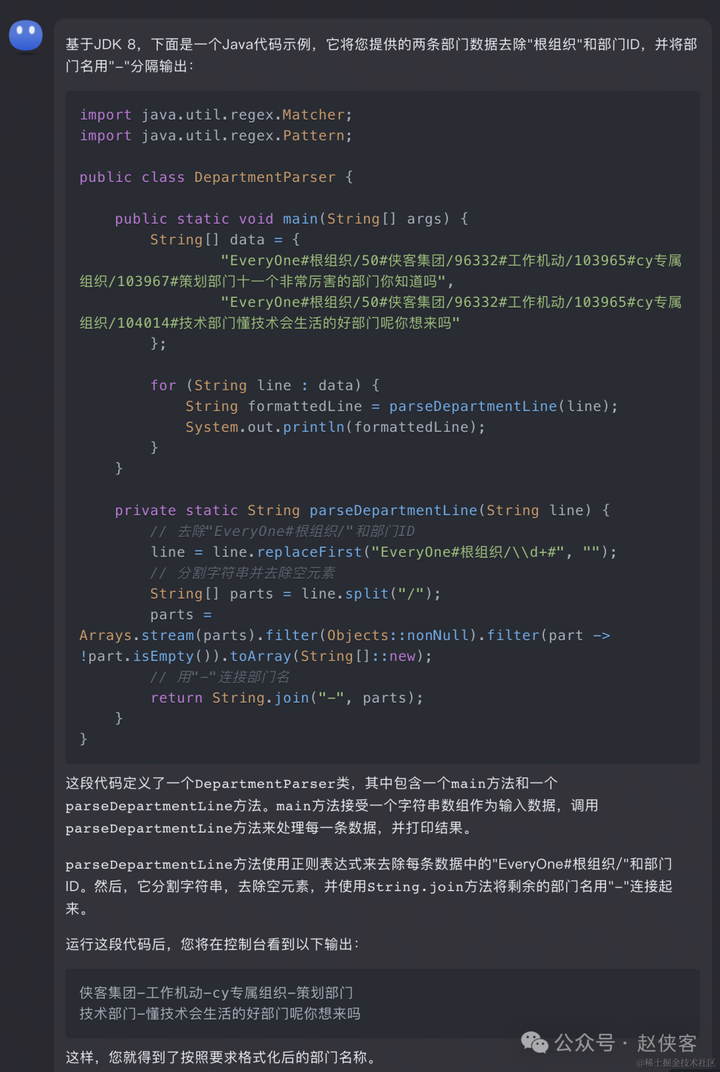
帮我把这两条部门数据去除根组织和部门id,将部门名用-分隔输出,请给出基于jdk8的java代码 everyone#根组织/50#侠客集团/96332#工作机动/103965#cy专属组织/103967#策划部门十一个非常厉害的部门你知道吗 everyone#根组织/50#侠客集团/96332#工作机动/103965#cy专属组织/104014#技术部门懂技术会生活的好部门呢你想来吗
kimi
添加图片注释,不超过 140 字(可选)
运行结果:
侠客集团-96332#工作机动-103965#cy专属组织-103967#策划部门十一个非常厉害的部门你知道吗 侠客集团-96332#工作机动-103965#cy专属组织-104014#技术部门懂技术会生活的好部门呢你想来吗
文心一言

添加图片注释,不超过 140 字(可选)
运行结果:
根组织-侠客集团-工作机动-cy专属组织-策划部门十一个非常厉害的部门你知道吗 根组织-侠客集团-工作机动-cy专属组织-技术部门懂技术会生活的好部门呢你想来吗
通义千问

添加图片注释,不超过 140 字(可选)
运行结果:
cy专属组织-策划部门十一个非常厉害的部门你知道吗 cy专属组织-技术部门懂技术会生活的好部门呢你想来吗
对比
-
通义千问:多去除了“侠客集团”和工作动机部门;
-
文心一言:只是没有去除根组织,其它都是正确了,表现最好;
-
kimi:输出错误,没有去除部门id,表现最差。
小结
文心一言>通义千问>kimi
问题六、多线程图片下载
输入: http://pic.people.com.cn/nmediafile/2024/0324/main17112471760803bc3vht0eb.jpg http://pic.people.com.cn/nmediafile/2024/0324/main1711247176118uwi7fvr0op.jpg 要求:请基本jdk8编写代码将输入的url使用下载到 c://img下,文件名从url中获取,要考虑url中获取文件名重复问题,要求使用多线程下载
kimi
import java.io.*;
import java.net.url;
import java.nio.file.*;
import java.util.*;
import java.util.concurrent.*;
public class imagedownloader {
private static final string download_dir = "c://img"; // 下载目录
public static void main(string[] args) {
list<string> imageurls = arrays.aslist(
"http://pic.people.com.cn/nmediafile/2024/0324/main17112471760803bc3vht0eb.jpg",
"http://pic.people.com.cn/nmediafile/2024/0324/main1711247176118uwi7fvr0op.jpg"
);
executorservice executorservice = executors.newfixedthreadpool(runtime.getruntime().availableprocessors());
try {
list<future<path>> futures = new arraylist<>();
for (string imageurl : imageurls) {
path path = paths.get(download_dir, getfilenamefromurl(imageurl));
futures.add(executorservice.submit(() -> downloadimage(imageurl, path)));
}
for (future<path> future : futures) {
future.get(); // 等待所有下载任务完成
}
} catch (interruptedexception | executionexception e) {
e.printstacktrace();
} finally {
executorservice.shutdown();
}
}
private static string getfilenamefromurl(string url) {
string filename = url.substring(url.lastindexof('/') + 1);
return filename;
}
private static path downloadimage(string imageurl, path path) throws ioexception, interruptedexception {
url url = new url(imageurl);
try (inputstream in = url.openstream();
outputstream out = new fileoutputstream(path.tofile())) {
byte[] buffer = new byte[1024];
int bytesread;
while ((bytesread = in.read(buffer)) != -1) {
out.write(buffer, 0, bytesread);
}
files.createdirectories(path.getparent()); // 确保父目录存在
files.move(path, path.resolvesibling(getuniquefilename(path.getfilename().tostring()))); // 重命名文件以避免重复
}
return path;
}
private static string getuniquefilename(string filename) {
path path = paths.get(download_dir, filename);
int counter = 1;
while (files.exists(path)) {
path = paths.get(download_dir, filename.replace(".jpg", "(" + counter + ").jpg"));
counter++;
}
return path.getfilename().tostring();
}
}
文心一言
import java.io.bufferedinputstream;
import java.io.fileoutputstream;
import java.io.ioexception;
import java.io.inputstream;
import java.net.httpurlconnection;
import java.net.url;
import java.nio.file.files;
import java.nio.file.path;
import java.nio.file.paths;
import java.security.messagedigest;
import java.security.nosuchalgorithmexception;
import java.util.arraylist;
import java.util.list;
import java.util.concurrent.executorservice;
import java.util.concurrent.executors;
public class imagedownloader {
private static final string target_directory = "c://img";
private static final int thread_pool_size = 5; // 可以根据需要调整线程池大小
public static void main(string[] args) {
// 输入的url列表
list<string> urls = new arraylist<>();
urls.add("http://pic.people.com.cn/nmediafile/2024/0324/main17112471760803bc3vht0eb.jpg");
urls.add("http://pic.people.com.cn/nmediafile/2024/0324/main1711247176118uwi7fvr0op.jpg");
executorservice executor = executors.newfixedthreadpool(thread_pool_size);
for (string url : urls) {
executor.submit(() -> downloadimage(url));
}
executor.shutdown();
try {
while (!executor.isterminated()) {
// 等待所有任务完成
thread.sleep(100);
}
system.out.println("all images downloaded.");
} catch (interruptedexception e) {
e.printstacktrace();
}
}
private static void downloadimage(string urlstring) {
try {
url url = new url(urlstring);
httpurlconnection connection = (httpurlconnection) url.openconnection();
connection.setrequestmethod("get");
try (inputstream in = new bufferedinputstream(connection.getinputstream());
fileoutputstream fos = getuniquefileoutputstream(urlstring)) {
byte[] buffer = new byte[1024];
int bytesread;
while ((bytesread = in.read(buffer)) != -1) {
fos.write(buffer, 0, bytesread);
}
} finally {
connection.disconnect();
}
} catch (ioexception e) {
e.printstacktrace();
}
}
private static fileoutputstream getuniquefileoutputstream(string urlstring) throws ioexception {
string filename = getfilenamefromurl(urlstring);
string filepath = paths.get(target_directory, filename).tostring();
// 确保文件名的唯一性
path path = paths.get(filepath);
if (files.exists(path)) {
filename = getuniquefilename(filename);
filepath = paths.get(target_directory, filename).tostring();
}
path targetpath = paths.get(filepath);
files.createdirectories(targetpath.getparent());
return new fileoutputstream(targetpath.tofile());
}
private static string getfilenamefromurl(string url) {
string[] parts = url.split("/");
return parts[parts.length - 1];
}
private static string getuniquefilename(string filename) throws nosuchalgorithmexception {
messagedigest md = messagedigest.getinstance("md5");
byte[] hashbytes = md.digest(filename.getbytes());
stringbuilder hexstring = new stringbuilder();
for (byte b : hashbytes) {
string hex = integer.tohexstring(0xff & b);
if (hex.length() == 1) hexstring.append('0');
hexstring.append(hex);
}
return filename + "_" + hexstring.tostring();
}
}
通义千问
import java.io.*;
import java.net.httpurlconnection;
import java.net.url;
import java.nio.channels.channels;
import java.nio.channels.readablebytechannel;
import java.nio.file.files;
import java.nio.file.path;
import java.nio.file.paths;
import java.time.localdatetime;
import java.time.format.datetimeformatter;
import java.util.concurrent.executorservice;
import java.util.concurrent.executors;
public class imagedownloader {
private static final string download_dir = "c://img";
public static void main(string[] args) throws ioexception {
string[] imageurls = {
"http://pic.people.com.cn/nmediafile/2024/0324/main17112471760803bc3vht0eb.jpg",
"http://pic.people.com.cn/nmediafile/2024/0324/main1711247176118uwi7fvr0op.jpg"
};
executorservice executor = executors.newfixedthreadpool(2); // 创建固定大小的线程池
for (string imageurl : imageurls) {
runnable worker = () -> downloadimage(imageurl);
executor.execute(worker);
}
executor.shutdown(); // 关闭线程池,等待所有任务完成
while (!executor.isterminated()) {
// 等待所有线程执行完毕
}
system.out.println("所有图片下载完成!");
}
private static void downloadimage(string imageurl) {
try {
url url = new url(imageurl);
httpurlconnection connection = (httpurlconnection) url.openconnection();
connection.setrequestmethod("get");
connection.setconnecttimeout(5000);
connection.connect();
if (connection.getresponsecode() == httpurlconnection.http_ok) {
string filename = extractfilenamefromurl(url);
path targetpath = paths.get(download_dir, ensureuniquefilename(filename));
files.createdirectories(targetpath.getparent()); // 如果目录不存在则创建
try (readablebytechannel rbc = channels.newchannel(connection.getinputstream());
fileoutputstream fos = new fileoutputstream(targetpath.tofile())) {
fos.getchannel().transferfrom(rbc, 0, long.max_value);
}
system.out.println("成功下载图片: " + targetpath.tostring());
} else {
system.out.println("无法下载图片,响应码: " + connection.getresponsecode());
}
} catch (ioexception e) {
system.err.println("图片下载失败: " + imageurl);
e.printstacktrace();
}
}
// 从url中提取文件名
private static string extractfilenamefromurl(url url) {
string path = url.getpath();
return path.substring(path.lastindexof('/') + 1);
}
// 确保文件名唯一,比如通过添加时间戳后缀
private static string ensureuniquefilename(string filename) {
path path = paths.get(download_dir, filename);
if (!files.exists(path)) {
return filename;
}
datetimeformatter formatter = datetimeformatter.ofpattern("yyyymmdd_hhmmss_sss");
localdatetime now = localdatetime.now();
string timestamp = now.format(formatter);
string extension = filename.substring(filename.lastindexof('.'));
return filename.replace(extension, "_" + timestamp + extension);
}
}
对比
-
结果来看kimi代码有错误,无法运行,文心一言少了一个异常抛出,修改可以运行下载,通义千问能正常运行下载,处理的逻辑也非常好;
-
目录不存在处理:kimi没有考虑下载目录c://img不存在报错问题,文心一言和通义千问都考虑了;
-
文件名重复问题:kimi使用后缀加(n),文心一言是使用文件名md5,通义千问使用时间戳。kimi思路最正确可是写法错了,文心一言使用文件名md5思路就错了,通义千问使用时间虽然不完美,但是是可以解决大部分url文件名相同问题。
小结
通义千问>文心一言>kimi
总结
从这六道题目来看kimi并没有多么的让人惊艳,大体上我们可以得出以下结论:
-
依赖数据源;可能是kimi自己没有能力收集大量数据和花大价钱买显卡去训练,所以回答结果非常依赖它得到的数据;
-
通用问题依赖搜索引擎;想做通用大模型肯定要有大量数据,kimi使用实时搜索去获取数据源,再给出结果。目前不知道它使用的是哪家搜索引擎,如果非常依赖搜索引擎那在通用大模型领域可能是硬伤,因为国内搜索引擎老大是谁大家都知道;
-
在代码生成领域不是很成熟;这一点应该不用太担心,国为程序员是第一波接触大模型的人,谁手上还没有几个墙外的产品,根本看不上国内的这些产品;
-
“百模大战”中的一员;给我的感觉它只是“百模大战”中的一员,并没有鹤立鸡群,能从“百模大战“中脱颖而出的惊艳。
最后关于它为什么会火起来这个就不得而知了,不过大家可以思考一下去年火起来的淄博烧烤、过年期间火起来的哈尔滨、最近正在火的天水麻辣烫,表明上看谁能火起来是门玄学,不过如果真的去深挖这些现象级火起来网红城市,你会发现玄学后面都是人(资本)在操控。


发表评论