最近aigc战场依然热闹,微软的new bing、google的bard、国内的讯飞星火认知大模型,都接连上阵,我们对比chatgpt一起来看看,我把实际使用测试结果发出,供大家参考。有些测试结果可能会出乎大家的预料哦…

今天我们暂时主要比拼4个能力:
-
字符计算能力
-
文学创意能力
-
实时新闻联网能力
-
数学运算能力
一、字符的计算比拼
字符计算一直是各大aigc应用的不擅长的,我们看看新秀们的表现
要结对这段字段进行数量计算,一共是多少个字符,正确答案是50。我们看一下各家的表现…
1.讯飞星火认知大模型:回答错误

2.google bard:回答错误
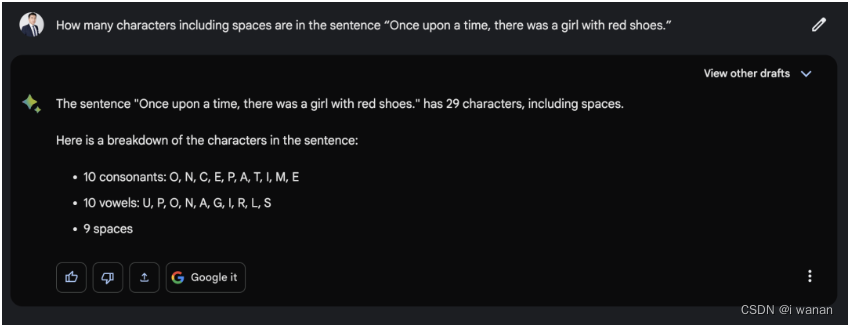
3. bing : 回答错误
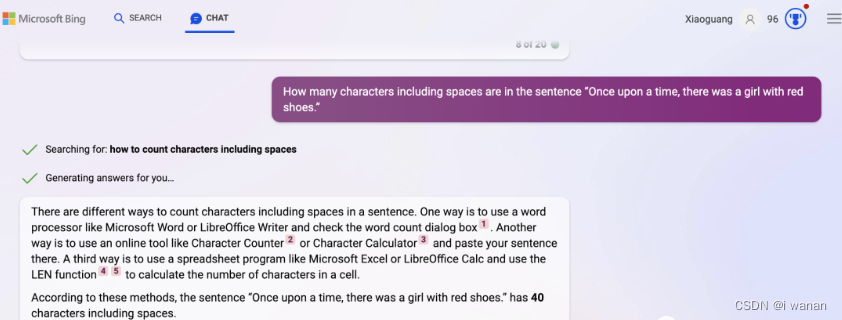
4.chatgpt:回答错误
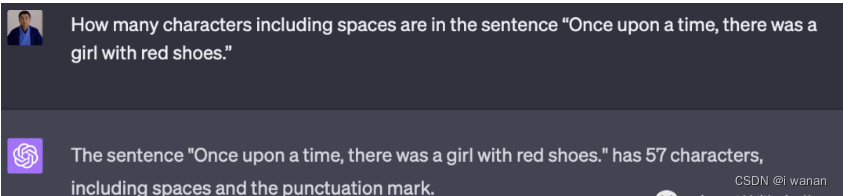
这个问题各家都给出了错误的答案。相信有不少朋友会觉得,这么简单的事情,对于它们来说根本不是事,但是事实是这么简单的事情,各家都失误啦,看来不要高估大模型的一些能力,这个有点出乎不少朋友的意料吧。
如果大家不信,那么我用这个再用另外一个小试题测试一下:
二、文学创意能力比拼
看看各家模型的创意创作都是什么水平。由于google bard不支持中文,暂时用英文将就一下google bard。
- bing : 优秀


4.chatgpt: 精彩


以上的故事创意,我更喜欢chatgpt和bing的,他们更加人性化。而星火和bard明显差了不少。
三、即时新闻:联网能力测验
1.讯飞星火认知大模型:不具备联网能力

2.google bard:优秀
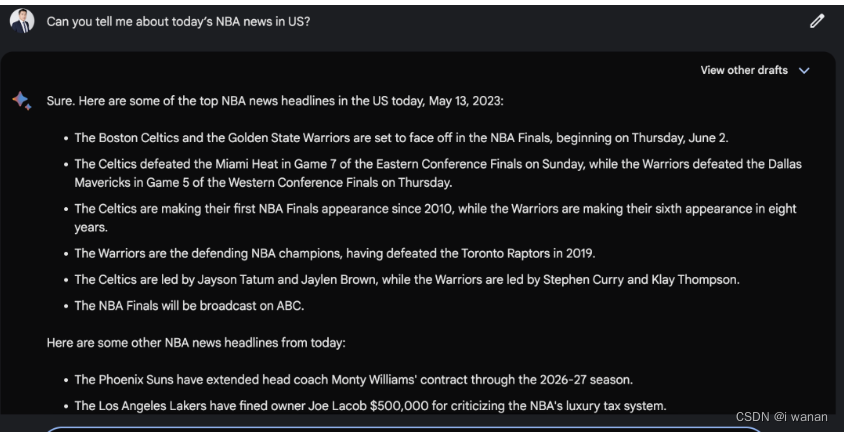
3. bing : 优秀

4.chatgpt: 不具备联网能力

结果果然不出我所料,google bard 和 微软的bing不负所望。
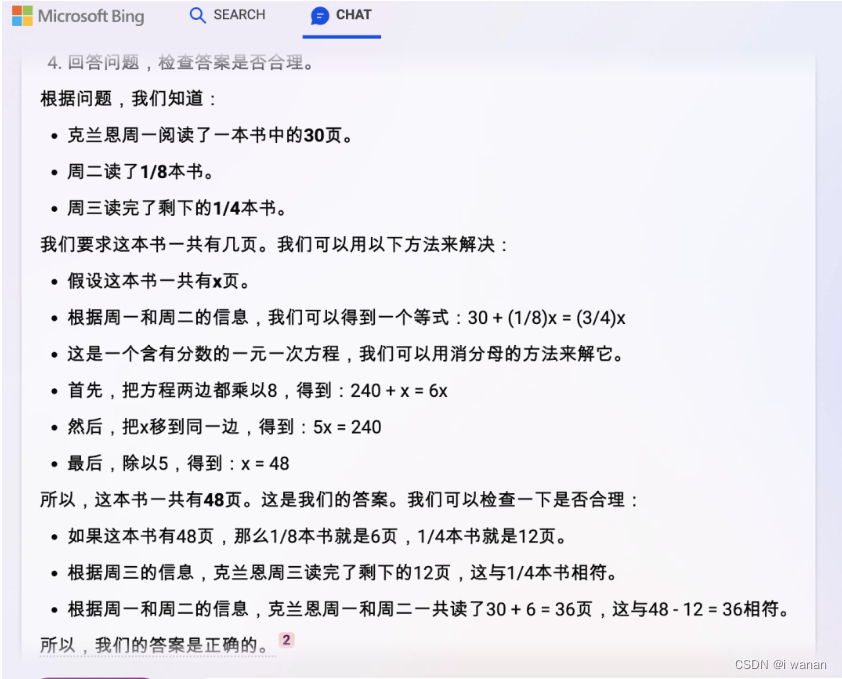
四、数学运算
考察一下各家数学运算推理能力,出个题考考大家吧。
- bing : 回答正确


4.chatgpt: 回答正确
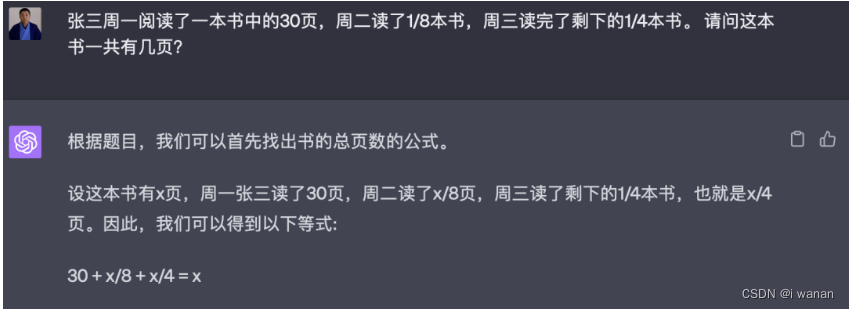

以上问题,除了讯飞星火大模型出现错误以外,其他的都回答正确,而且思路清晰。
今天仅做了4个方面的测试,后面我们将在编程、角色扮演,对话能力等方面进行更多测试。



发表评论