第一篇llama 3 8b大模型部署和 python 版对话机器人博文:玩转 ai,笔记本电脑安装属于自己的 llama 3 8b 大模型和对话客户端
第二篇基于ollama部署llama 3 8b大模型 web 版本对话机器人博文:一文彻底整明白,基于 ollama 工具的 llm 大语言模型 web 可视化对话机器人部署指南
注意: 因为本博文介绍的是llama 3 中文版(llama3-chinese-chat)对话机器人,涉及到前面两篇博文内容,特别是第二篇 web 版本对话机器人部署,因此建议按照前文博文部署好llama 3 8b大语言模型。
hf 上选择排名最高的模型
模型列表官网地址:https://huggingface.co/models
模型列表国内镜像(推荐):https://hf-mirror.com/models
在模型列表页面按照关键字llama chinese搜索,并按照趋势排序,可以看到中文版模型:
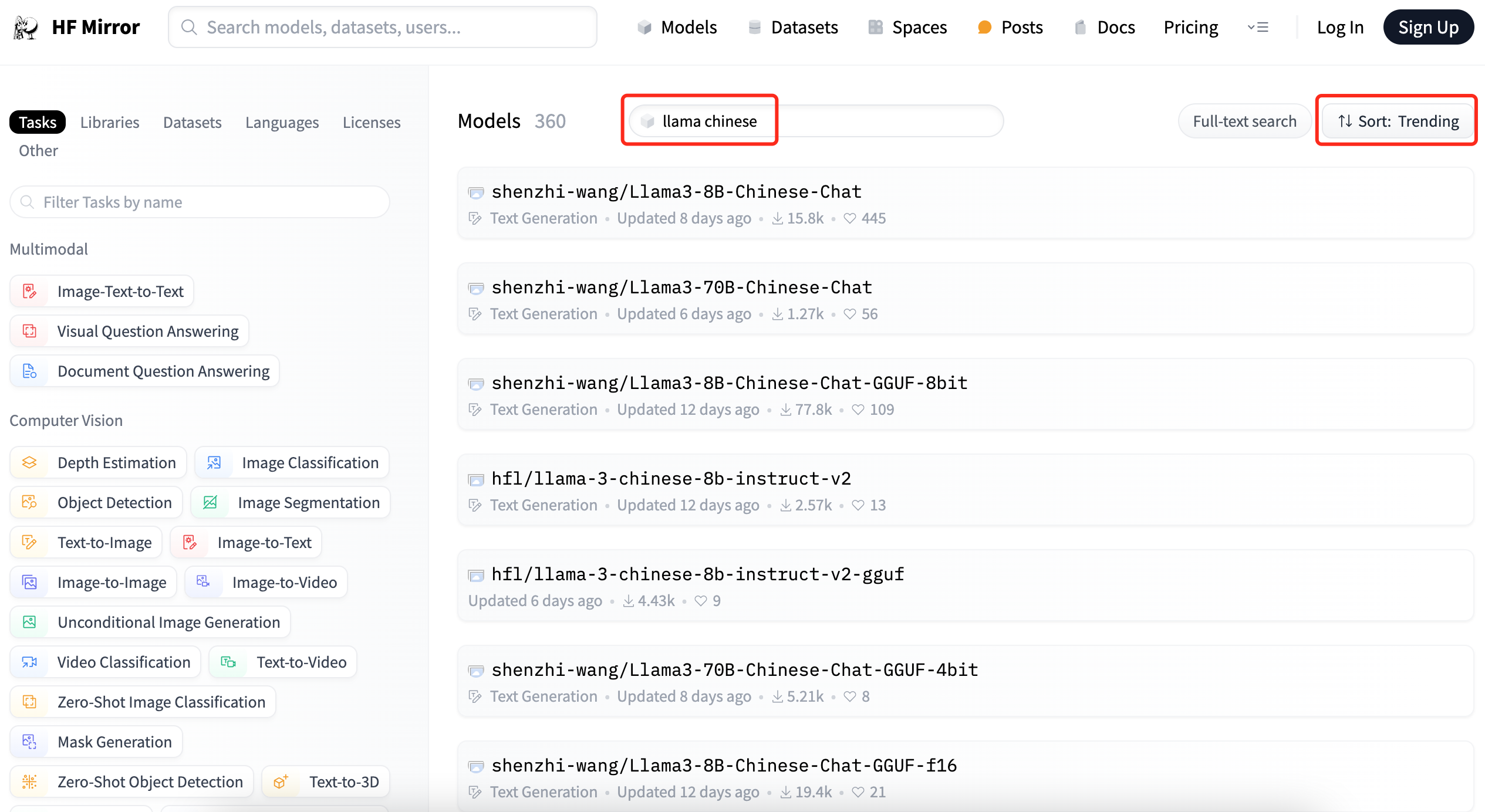
可以看出,第一名模型的下载数量和点赞数量,比第二名要多好多,我们就选择shenzhi-wang这位作者发布的模型。
方式一:通过 gguf 量化模型安装(推荐)
gguf 安装比较简单,下载单个文件即可:

下载到本地之后,按照我的第一篇博文,即可进行控制台聊天了:
启动大模型shell 脚本:
source ./venv/bin/activate
python -m llama_cpp.server --host 0.0.0.0 --model \
./llama3-8b-chinese-chat-q4_0-v2_1.gguf \
--n_ctx 20480
python 对话客户端代码:
from openai import openai
# 注意服务端端口,因为是本地,所以不需要api_key
ip = '127.0.0.1'
#ip = '192.168.1.37'
client = openai(base_url="http://{}:8000/v1".format(ip),
api_key="not-needed")
# 对话历史:设定系统角色是一个只能助理,同时提交“自我介绍”问题
history = [
{"role": "system", "content": "你是一个智能助理,你的回答总是容易理解的、正确的、有用的和内容非常精简."},
]
# 首次自我介绍完毕,接下来是等代码我们的提示
while true:
completion = client.chat.completions.create(
model="local-model",
messages=history,
temperature=0.7,
stream=true,
)
new_message = {"role": "assistant", "content": ""}
for chunk in completion:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=true)
new_message["content"] += chunk.choices[0].delta.content
history.append(new_message)
print("\033[91;1m")
userinput = input("> ")
if userinput.lower() in ["bye", "quit", "exit"]: # 我们输入bye/quit/exit等均退出客户端
print("\033[0mbye bye!")
break
history.append({"role": "user", "content": userinput})
print("\033[92;1m")
运行 python 客户端即可:

按照第二篇博文,部署基于 web 版对话机器人:一文彻底整明白,基于 ollama 工具的 llm 大语言模型 web 可视化对话机器人部署指南
基于 gguf 量化模型生成 ollama模型文件,假设文件名为modelfile-chinese,内容如下:
from ./llama3-8b-chinese-chat-q4_0-v2_1.gguf
执行 ollama 模型转换,llama-3-8b-chinese为 ollama 模型名:
$ ollama create llama-3-8b-chinese -f ./modelfile-chinese
transferring model data
using existing layer sha256:242ac8dd3eabcb1e5fcd3d78912eaf904f08bb6ecfed8bac9ac9a0b7a837fcb8
creating new layer sha256:9f3bfa6cfc3061e49f8d5ab5fba0f93426be5f8207d8d8a9eebf638bd12b627a
writing manifest
success
可以通过 ollama 查看目前的大模型列表:
$ ollama list
name id size modified
llama-3-8b-chinese:latest 37143cf1f51f 4.7 gb 42 seconds ago
llama-3-8b:latest 74abc0712fc1 4.9 gb 3 days ago
可以看到我们刚安装的大模型:llama-3-8b-chinese
启动ollama-webui-lite项目,可以选择llama-3-8b-chinese模型和对话聊天了:
$ npm run dev
> ollama-webui-lite@0.0.1 dev
> vite dev --host --port 3000
vite v4.5.3 ready in 1797 ms
➜ local: http://localhost:3000/
➜ network: http://192.168.101.30:3000/
➜ press h to show help

方式二:通过 ollama 拉取模型文件
这种方式比较简单,无需下载 gguf 模型文件,可以让 ollama 直接拉取模型文件并完成安装:
# llama3-8b-chinese-chat的4位量化版本(对机器性能要求最低)
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q4
# llama3-8b-chinese-chat的8位量化版本(对机器性能要求中等)
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8
# llama3-8b-chinese-chat的f16未量化版本(对机器性能要求最高)
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-fp16
ollama 自动下载并完成安装,之后启动ollama-webui-lite项目,就可以使用了~
我的本博客原地址:https://mp.weixin.qq.com/s/idcdir8mmwdq_izu5r_ueq


发表评论