一、前言
本文为大一学生为实现电赛视觉而自行探索的实现方法(主要是应用过程),过程简单粗暴而不求甚解,想要深入学习原理的同学请转本站其他详细的教程哦!笔者总结了自己踩过的坑,来为接下来入门电赛并使用树莓派(opencv+yolov5-lite)视觉方案的同学们提供一些粗略的见解,笔者才疏学浅,还望各位大佬不吝指教!
笔者是福州大学2023级电子类专业的学生,由于我校本专业在大一学的编程类相关知识少得可怜(仅学了c语言公共课),对于python仅停留在初高中知识(笑)因此可以说本文适用于零python基础的同学学习(但并不代表没有任何计算机基础!!qaq)

直接上成品 可以准确的识别到提供的数字 帧率能达到5帧上下
具体展示可以观看此视频,1p为部署在树莓派上的效果(由于是网络连接屏幕显示存在延迟),p2为在电脑上运行的效果 https://www.bilibili.com/video/bv17daxevejk/?vd_source=4de2623ca9107725cf5a7528afe9b454
https://www.bilibili.com/video/bv17daxevejk/?vd_source=4de2623ca9107725cf5a7528afe9b454
二、硬件部分
硬件是一切准备的关键!!排除了硬件方面的问题才能好好地搞软件!需要的东西并不多:
一、一台可用的电脑 (性能不重要 由于笔者使用的是cpu版本,并不吃显卡)
二、一只树莓派(笔者用的是树莓派4b 4gb版本 不推荐裸板使用,裸板极易损坏,小心静电)
要有合适且稳定的电源供给,低电情况下运行树莓派会出问题!
推荐全封闭式的外壳,尽量避免用手直接接触板卡!

默认已经安装好镜像并且会使用树莓派的基础功能(无论是连接屏幕还是vnc连接)
三、一只免驱usb摄像头

图片为亚博智能的摄像头,像素可选(我觉得30w足够了),不过线材质量差,可以另买备用
虽然说树莓派官方的csi摄像头也可以,但是我更推荐usb摄像头,理由有三:
1.usb免驱摄像头的数据线更长更灵活,适合部署在移动设备上
2.使用usb摄像头可以排除摄像头的问题(csi的容易坏,usb的直接插电脑上看看)
3.方便在电脑上测试摄像头,并避免损坏树莓派的板子
三、软件部分①
3.1 基本网络工具
1.ai应用:chatgpt4o,提供一个国内可访问的免费镜像:
国内chatgpt镜像https://origin.eqing.tech/
其实国产的许多ai平台也不错,比如月之暗面kimi
2.上网工具:watt toolkit,如果打不开github可以使用软件加速:
watt toolkit下载链接https://steampp.net/3.必备软件源:清华源:
清华大学开源软件镜像站https://mirror.tuna.tsinghua.edu.cn/
3.2 电脑环境配置
必备软件如下:
3.2.1 基本部分
一个版本合适的python
官网下载链接https://www.python.org/downloads/
上图中3.8~3.12版本都是可用的
一个版本合适的pycharm
官网下载链接https://www.jetbrains.com/pycharm/download/?section=windows
下载社区版(community edition)即可,专业版(professional)要收费
这里注意一下,笔者在这里踩了一个坑:笔者最初使用的是3.12版本的python、2019版本的pycharm,这里2019pycharm并不能很好的识别出3.1x版本的python,会将其识别为3.1版本并会提示python版本过于落后,所以建议都下载最新版本的软件哦(所以最简单的方法就是均安装最新且稳定的版本即可)
3.2.2 训练所需
安装anaconda3(虚拟环境)
根据自己的设备型号选择合适的版本https://www.anaconda.com/download/
安装labelme(标注标签)
1.打开anaconda的命令行:anaconda powershell prompt

如上图所示
之后会进入到这样的一个窗口,在开头出现(base)字样即进入了虚拟环境
2.进行labelme的安装
对其感兴趣的同学可以访问这个项目的网址哈:
labelme的github链接(该程序持续更新)https://github.com/wkentaro/labelme/
在anaconda的命令行中键入以下代码:
conda create --name=labelme python=3.6
conda activate labelme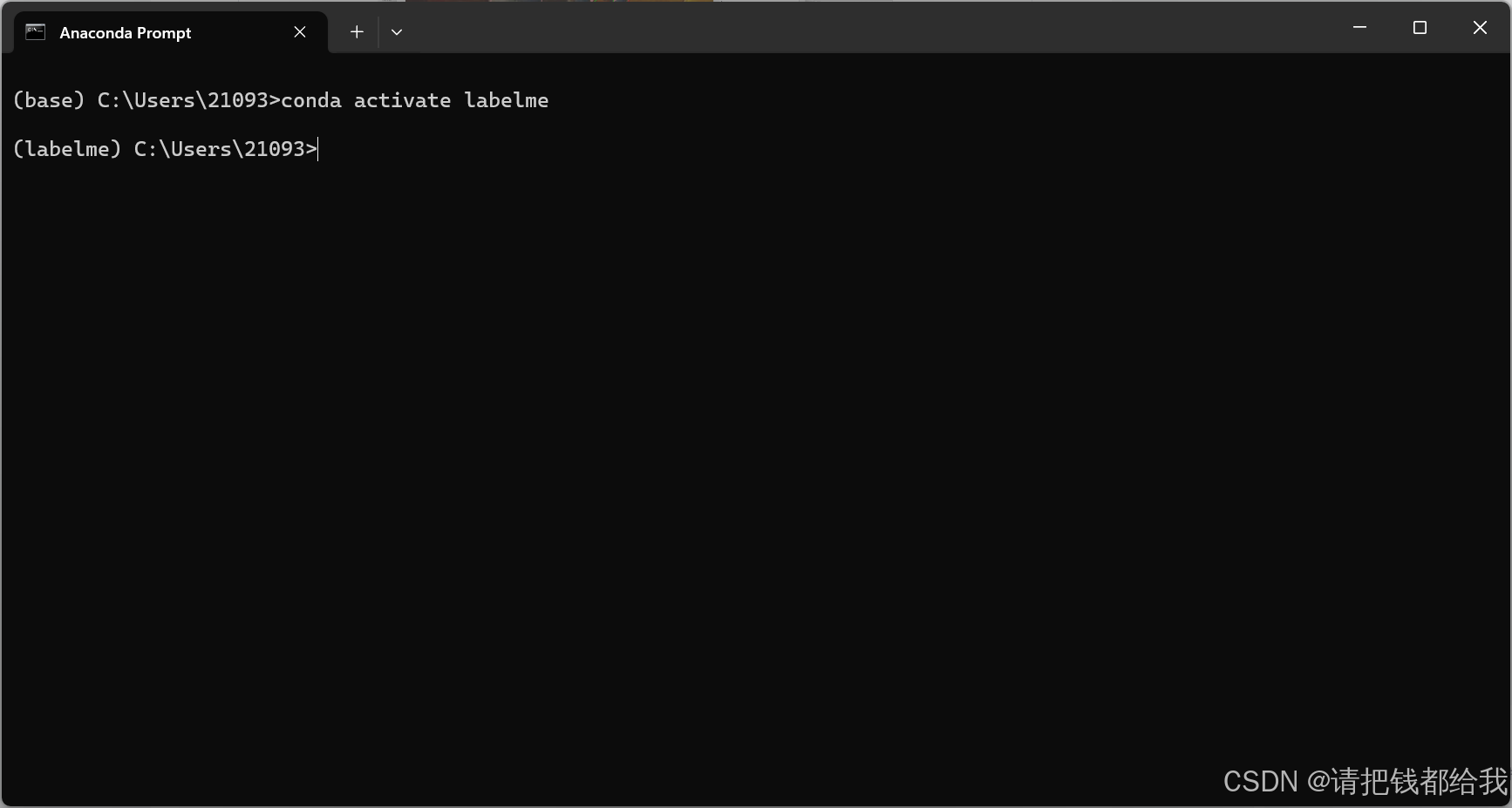
如图,在句首出现(labelme)字样则已经进入到了labelme虚拟环境
先安装pyqt5,键入命令:
pip install pyqt5 -i https://pypi.tuna.tsinghua.edu.cn/simple
接下来安装labelme,键入以下命令:
pip install labelme如果在这里出现报错报红的小伙伴们可以进行换源操作,使用之前提到的清华源(在原命令后方添加上 -i 清华源):
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple建议都采用清华源安装的方式,更快也更稳定哦
到此,电脑上的基本软件安装就告一段落了
四、yolov5-lite模型训练
终于来到了最为关键的一步,这一步我们将要进行模型的训练
首先要想大家介绍一下yolov5-lite是什么,为什么我们选择使用yolov5-lite?
yolov5-lite是yolov5的优化版本,通过一系列精心设计的消融实验,实现了模型的轻量化。相较于原始的yolov5,yolov5-lite在保持高效目标检测能力的同时,显著降低了模型的计算复杂度、内存占用和参数数量。以下是对yolov5-lite特性的重新组织和阐述:
1. 轻量化设计:yolov5-lite通过减少参数和优化结构,实现了模型的轻量化。这不仅降低了模型的浮点运算次数(flops),还减少了内存占用,使得模型更加适合资源受限的环境。
2. 性能提升:yolov5-lite在保持320像素输入尺寸的情况下,通过引入shuffle channel技术和对yolov5头部进行通道裁剪,显著提高了推理速度。在树莓派4b这样的硬件上,推理速度至少可达10+fps,满足了实时处理的需求。
3. 部署友好:为了简化模型部署,yolov5-lite去除了focus层和多次slice操作,这些改变虽然对量化精度有一定影响,但精度下降在可接受范围内,确保了模型的实用性。
4. 实用性与效率的平衡:尽管yolov5-lite在精度上有所牺牲,但其推理速度的显著提升和部署的便捷性,使其成为实战部署的理想选择,特别是在需要快速响应和资源受限的应用场景中。
以上都是源自网络的理论,实际使用效果因物而异
总的来说,yolov5-lite通过一系列优化措施,实现了模型的轻量化和快速推理,同时保持了较高的实用性,非常适合在资源受限的设备上进行目标检测任务,笔者选择yolov5-lite是想要应用在树莓派上进行一些简单的目标识别。事实上,笔者训练的模型在树莓派4b上也能以5fps上下的帧率进行识别,置信度平均能够达到0.8,在识别简单数字和简单物体上的实用性还是非常强的,应用在大学生电子设计竞赛上应该是没问题的,这样轻量化的设计正好为我们提供了很好的方案。
至于这个深度学习的原理,笔者简单做了一个流程图,供读者们理解
4.1 图像获取与图像处理
这个部分是简单而又关键的部分,模型的质量最主要取决于这一步
笔者以简单的数字1-8识别作为例程给大家进行教学:
首先,要得到我们想要识别的物体:
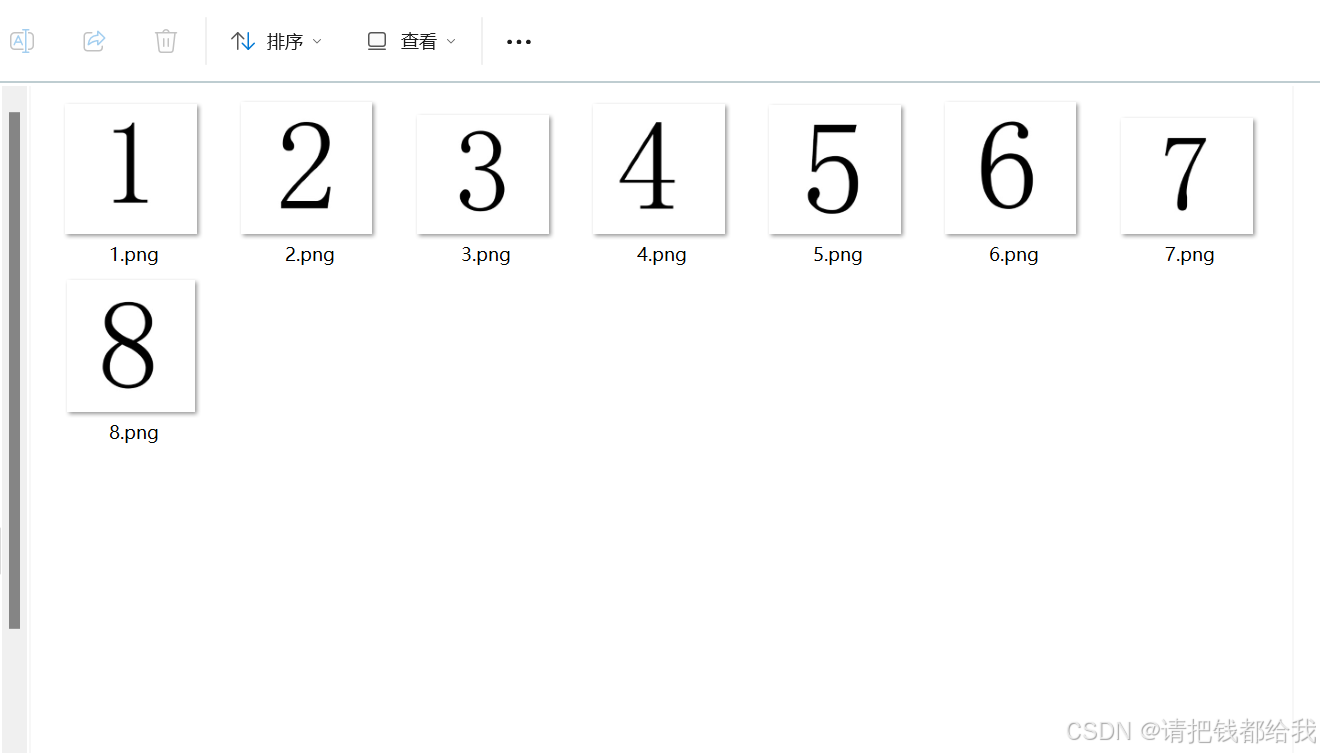
很显然,只有这样八张图片用来作为数据集训练是不可能的,那么,我们要怎样丰富我们的数据集呢?
由于笔者的例程是简单的数字识别,对于简单的数字,我们可以用计算机技术进行一些图像的变换来得到我们想要的数据集:旋转、放大缩小、仿射变换等等。
接下来笔者给出的这个程序大家可以直接采用,用于对原来的图像进行变换,得到大量的图像集。
如果使用该程序来进行图像处理,会对每一张图片生成256张变换后的图像
import cv2
import numpy as np
import os
# 设置图像路径和输出目录
image_path = "c:/users/xxx(举例,引号内填入你自己的路径)"
output_dir = "(填入你自己的路径)"
# 创建输出目录(如果不存在)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 读取图像
image = cv2.imread(image_path)
# 获取图像的高、宽和中心点
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
# 定义仿射变换矩阵,使图像形成鸟瞰图(俯视图)的效果
def get_affine_matrix():
pts1 = np.float32([[w // 4, h // 4], [3 * w // 4, h // 4], [w // 4, 3 * h // 4]])
pts2 = np.float32([[w // 4, h // 4], [3 * w // 4, h // 4 - 50], [w // 4, 3 * h // 4 + 50]])
m = cv2.getaffinetransform(pts1, pts2)
return m
# 将图像旋转并进行仿射变换
for angle in range(0, 360, 5):
# 生成旋转矩阵
m_rotate = cv2.getrotationmatrix2d(center, angle, 1.0)
# 计算旋转后图像的边界尺寸
cos = np.abs(m_rotate[0, 0])
sin = np.abs(m_rotate[0, 1])
new_w = int((h * sin) + (w * cos))
new_h = int((h * cos) + (w * sin))
# 调整旋转矩阵的平移部分
m_rotate[0, 2] += (new_w / 2) - center[0]
m_rotate[1, 2] += (new_h / 2) - center[1]
# 旋转图像,并填充背景为白色
rotated = cv2.warpaffine(image, m_rotate, (new_w, new_h), bordervalue=(255, 255, 255))
# 进行仿射变换,并填充背景为白色
m_affine = get_affine_matrix()
transformed = cv2.warpaffine(rotated, m_affine, (new_w, new_h), bordervalue=(255, 255, 255))
# 保存处理后的图像
output_path = os.path.join(output_dir, f"transformed_{angle}.jpg")
cv2.imwrite(output_path, transformed)
print("图像处理完成。")此处把背景填充为白色有大用处,接下来会解释
这里还需要提醒一下,生成的图片格式最好都是.jpg格式的比较好哦
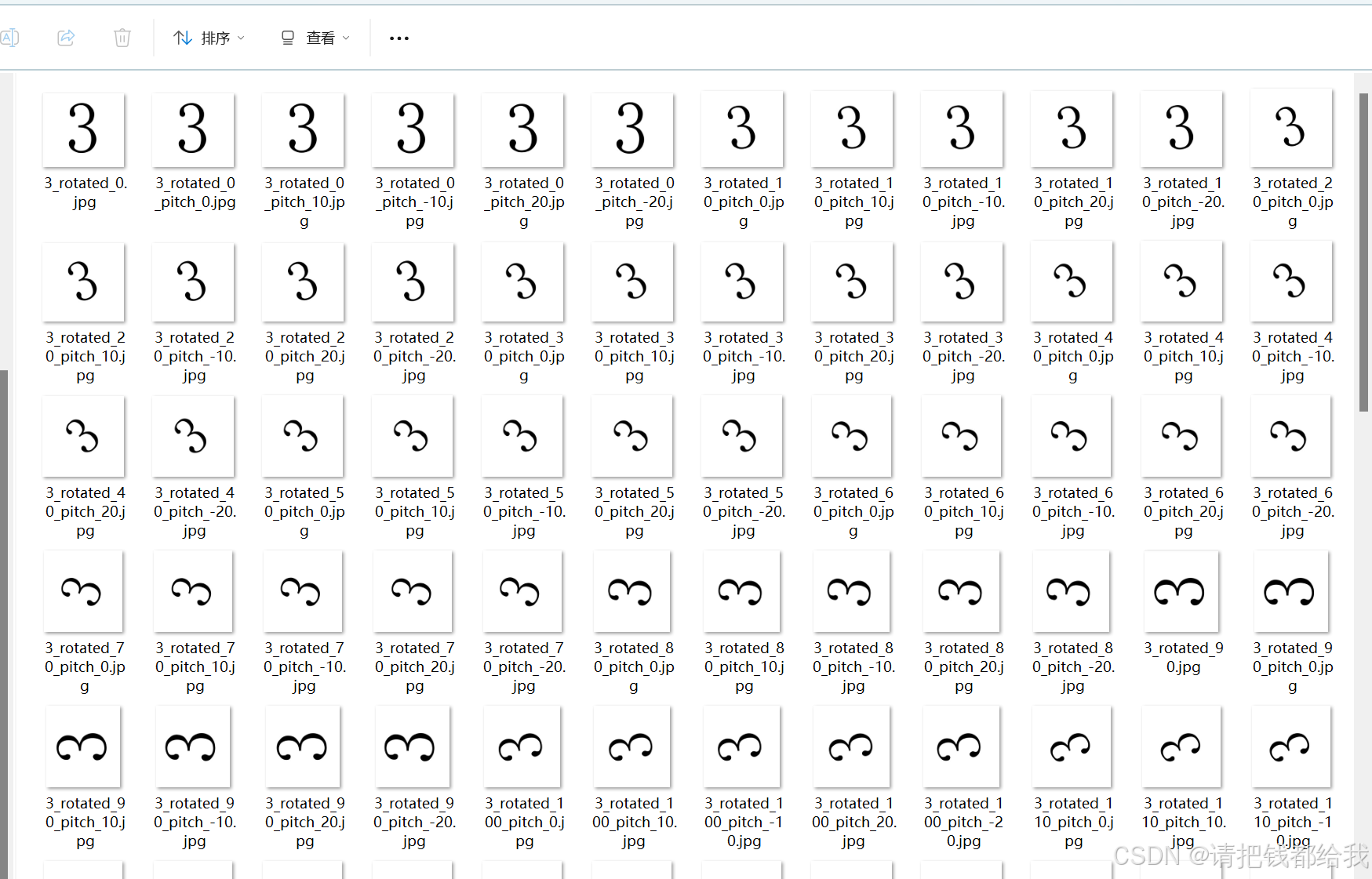
以数字3为例,这是经过程序变换生成的图像集
当然,如果不嫌累的话,可以通过相机进行拍摄,通过调整镜头角度,光线位置,环境亮度等等,可以获得更为精细的图像数据集,笔者的这个做法纯粹是取巧省事,想要更加精确的数据集还是通过相机捕捉更好
4.2 图像标注与格式转化
这一步是最为繁琐的一步,需要对每一张图片进行标签标注:
准备一个文件,命名为labels.txt
__ignore__
_background_
1
2
3
4
5
6
7
8最上方的两行是必要的,下面的1~8大家可以自行改成想要的标签,比如car、pen等等哦
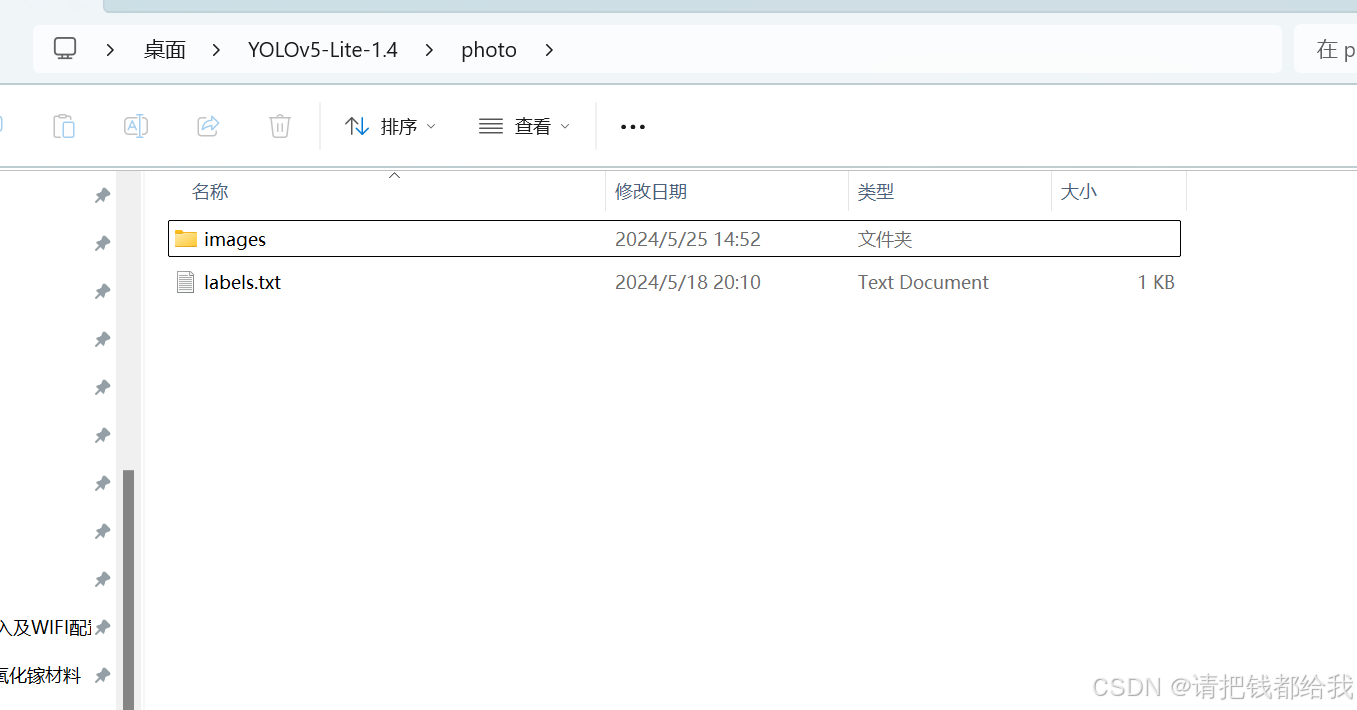
如图,接下来我们把图像文件夹和这个labels.txt文件放在同一目录下
使用labelme命令行进入labelme界面:
conda activate labelme
labelme
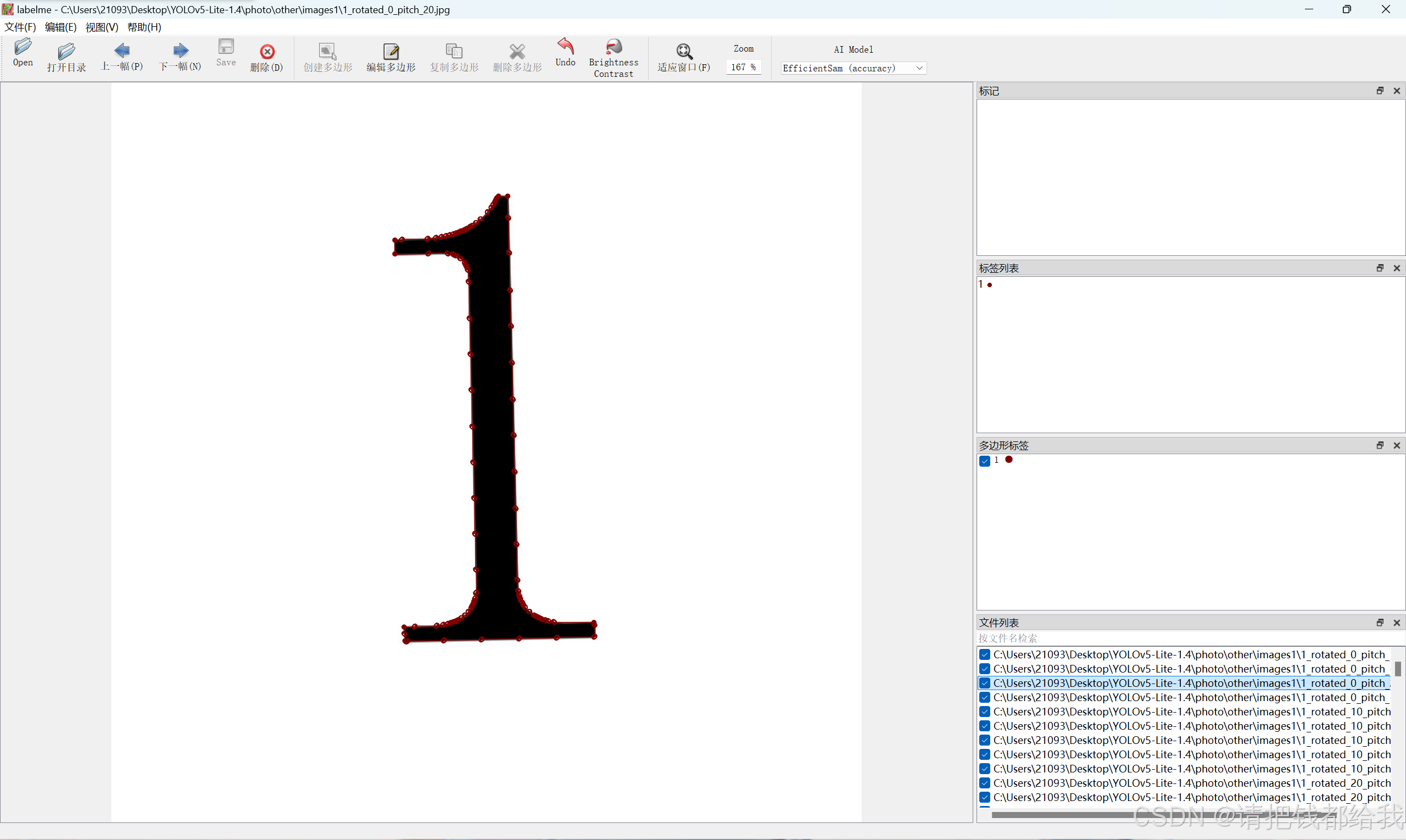
接下来打开图片目录,进行图片的标注
选择创建多边形,手动拉框框,框选住你要的目标并标注上它的标签
如此一张复一张......效率未免有些低下
笔者在这里写了一个程序来全自动完成这一过程,对原来文件夹中的图片进行遍历,再进行一次数据增强,并使用opencv通过检测黑色边缘的方式来对数据集进行标注!!
import cv2
import os
import glob
import json
import shutil
import numpy as np
def save_labelme_format(image_path, bbox, output_dir, label):
img = cv2.imread(image_path)
if img is none:
print(f"failed to read image: {image_path}")
return
h, w = img.shape[:2]
shapes = []
points = [[bbox[0], bbox[1]], [bbox[0] + bbox[2], bbox[1]], [bbox[0] + bbox[2], bbox[1] + bbox[3]],
[bbox[0], bbox[1] + bbox[3]]]
shape = {
"label": label,
"points": points,
"group_id": none,
"shape_type": "polygon",
"flags": {}
}
shapes.append(shape)
labelme_data = {
"version": "4.5.6",
"flags": {},
"shapes": shapes,
"imagepath": os.path.basename(image_path),
"imagedata": none,
"imageheight": h,
"imagewidth": w
}
json_name = os.path.splitext(os.path.basename(image_path))[0] + '.json'
with open(os.path.join(output_dir, json_name), 'w') as f:
json.dump(labelme_data, f, indent=4)
def augment_image(image):
rows, cols = image.shape[:2]
# 随机旋转
angle = np.random.uniform(-30, 30)
m = cv2.getrotationmatrix2d((cols / 2, rows / 2), angle, 1)
rotated_image = cv2.warpaffine(image, m, (cols, rows), bordervalue=(255, 255, 255))
# 随机仰角变化
pts1 = np.float32([[50, 50], [200, 50], [50, 200]])
pts2 = np.float32([[50, 50], [200, 50 + np.random.uniform(-50, 50)], [50, 200 + np.random.uniform(-50, 50)]])
m = cv2.getaffinetransform(pts1, pts2)
skewed_image = cv2.warpaffine(rotated_image, m, (cols, rows), bordervalue=(255, 255, 255))
return skewed_image
def find_black_bbox(image):
# 转换为灰度图像并进行二值化
gray = cv2.cvtcolor(image, cv2.color_bgr2gray)
_, binary = cv2.threshold(gray, 127, 255, cv2.thresh_binary_inv)
# 寻找轮廓
contours, _ = cv2.findcontours(binary, cv2.retr_external, cv2.chain_approx_simple)
if contours:
# 合并所有轮廓,计算最小外接矩形
all_contours = np.vstack(contours)
x, y, w, h = cv2.boundingrect(all_contours)
return x, y, w, h
else:
return none
def augment_images(folders, output_dir, target_count=350):
os.makedirs(output_dir, exist_ok=true)
for folder_index, folder in enumerate(folders, start=1):
image_paths = glob.glob(os.path.join(folder, '*.jpg'))
print(f"processing folder: {folder}, found {len(image_paths)} images.")
if len(image_paths) == 0:
continue
# 每个文件夹需要生成的增强图片数量
num_augmented_per_image = target_count // len(image_paths)
folder_output_dir = os.path.join(output_dir, f"folder_{folder_index}")
os.makedirs(folder_output_dir, exist_ok=true)
for image_path in image_paths:
print(f"processing image: {image_path}")
img = cv2.imread(image_path)
if img is none:
print(f"failed to read image: {image_path}")
continue
shutil.copy(image_path, folder_output_dir)
for i in range(num_augmented_per_image):
augmented_image = augment_image(img)
aug_image_name = f"{os.path.splitext(os.path.basename(image_path))[0]}_aug_{i}.jpg"
aug_image_path = os.path.join(folder_output_dir, aug_image_name)
cv2.imwrite(aug_image_path, augmented_image)
# 检查并处理不足的情况
current_augmented_images = glob.glob(os.path.join(folder_output_dir, '*.jpg'))
while len(current_augmented_images) < target_count:
for image_path in image_paths:
img = cv2.imread(image_path)
if img is none:
continue
augmented_image = augment_image(img)
aug_image_name = f"{os.path.splitext(os.path.basename(image_path))[0]}_aug_extra_{len(current_augmented_images)}.jpg"
aug_image_path = os.path.join(folder_output_dir, aug_image_name)
cv2.imwrite(aug_image_path, augmented_image)
current_augmented_images.append(aug_image_path)
if len(current_augmented_images) >= target_count:
break
# 标注生成的图像
annotate_images(folder_output_dir, folder_index)
def annotate_images(output_dir, label):
image_paths = glob.glob(os.path.join(output_dir, '*.jpg'))
print(f"annotating {len(image_paths)} images in folder: {output_dir}.")
for image_path in image_paths:
print(f"annotating image: {image_path}")
img = cv2.imread(image_path)
if img is none:
print(f"failed to read image: {image_path}")
continue
bbox = find_black_bbox(img)
if bbox:
save_labelme_format(image_path, bbox, output_dir, str(label))
else:
print(f"no valid bounding box found in image {image_path}.")
if __name__ == '__main__':
folders = [
# 这里是需要遍历的文件夹目录
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/1",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/2",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/3",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/4",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/5",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/6",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/7",
"c:/users/21093/desktop/yolov5-lite-1.4/photo/images/8"
]
# 这里是输出目录
output_dir = "c:/users/21093/desktop/yolov5-lite-1.4/photo/other/images1"
# 数据增强
augment_images(folders, output_dir)
接下来笔者来解释一下这个程序,让大家可以进行程序的移植运用
这个程序的主要作用是从多个文件夹中读取图像,检测并提取图像中的黑色数字区域,然后对这些图像进行数据增强,生成相应的标注文件,并保存到指定的输出目录中。以下是程序的具体说明:
-
读取图像:从指定的多个文件夹中读取所有
.jpg格式的图像。 -
数据增强:对每张原始图像进行数据增强,包括随机旋转和仰角变化。
-
保存最小矩形框:
save_labelme_format函数将矩形框的四个顶点转换为点,并生成labelme所需的 json 文件。 -
寻找黑色区域的最小矩形框:
find_black_bbox函数合并所有轮廓,并计算最小外接矩形。 -
数据增强:
augment_images函数确保从每个文件夹内获取的图片进行处理后生成的图片统一为 350 张。如果不足,则继续进行增强直到达到目标数量。 -
标注图像:
annotate_images函数对增强后的图像进行标注。 -
保存原始图像及标注:
- 对于每个检测到的有效轮廓,生成 labelme 格式的 json 标注文件。
- 将原始图像生成的相应的 json 标注文件保存到输出目录中。
-
输出结果:所有处理后的图像与其标注文件(json格式)都会被保存到指定的输出目录中。
-
特别说明:
for folder_index, folder in enumerate(folders, start=1): # ... 省略其他处理 ... # 标注生成的图像 annotate_images(output_dir, folder_index) #在上述代码中,enumerate(folders, start=1) 会遍历 folders 列表,每个文件夹对应的索引从1开始递增,这个索引即作为标签传递给 annotate_images 函数。在上面的代码中,不同的文件夹被分配不同的标签是通过
annotate_images函数实现的。具体来说,在augment_images函数中的循环中,每次处理一个文件夹时,将文件夹的索引folder_index传递给annotate_images函数作为标签参数label。其中,folder_index是从1开始递增的,每个文件夹都有一个唯一的索引。这个索引被传递给annotate_images函数,并最终用于标注图片。这样,每个文件夹生成的图像都会被标注为对应的文件夹索引。所以可以做到对每个输入的文件夹都分配对应正确的图像标签! -
综上所述,大家只要修改一下输入输出目录即可,对每个输入文件夹的图片赋予什么样的标签可以通过ai工具来进行修改,简单又方便!
接下来大家还是可以采用笔者写的格式转换程序,把json格式文件转换为txt文件:
import os
import json
import glob
import shutil
import random
# 定义类别名称到索引的映射
class_to_id = {
'1': 0,
'2': 1,
'3': 2,
'4': 3,
'5': 4,
'6': 5,
'7': 6,
'8': 7
}
# 标注文件所在的文件夹路径
json_folder_path = r"c:\users\21093\desktop\yolov5-lite-1.4\photo\other\images3"
# 输出标签文件的文件夹路径
output_base_path = r"c:\users\21093\desktop\yolov5-lite-1.4\yolov5-lite\data"
# 创建输出子目录
os.makedirs(os.path.join(output_base_path, 'train', 'images'), exist_ok=true)
os.makedirs(os.path.join(output_base_path, 'train', 'labels'), exist_ok=true)
os.makedirs(os.path.join(output_base_path, 'valid', 'images'), exist_ok=true)
os.makedirs(os.path.join(output_base_path, 'valid', 'labels'), exist_ok=true)
# 读取并转换json文件
json_files = glob.glob(os.path.join(json_folder_path, "*.json"))
for json_file_path in json_files:
# 读取json文件
with open(json_file_path, 'r') as f:
data = json.load(f)
# 获取图像文件名(不含扩展名)
image_id = os.path.splitext(os.path.basename(json_file_path))[0]
image_path = os.path.join(json_folder_path, f"{image_id}.jpg")
# 判断是放入训练集还是验证集
subset = 'train' if random.random() < 0.9 else 'valid'
# 确定输出文件路径
output_image_path = os.path.join(output_base_path, subset, 'images', f"{image_id}.jpg")
output_label_path = os.path.join(output_base_path, subset, 'labels', f"{image_id}.txt")
# 复制图像文件到输出目录
shutil.copy(image_path, output_image_path)
# 写入txt标签文件
with open(output_label_path, 'w') as txt_file:
for shape in data['shapes']:
if shape['shape_type'] == 'polygon':
# 计算多边形标注的最小和最大点来确定边界框
min_x = min(shape['points'], key=lambda x: x[0])[0]
max_x = max(shape['points'], key=lambda x: x[0])[0]
min_y = min(shape['points'], key=lambda x: x[1])[1]
max_y = max(shape['points'], key=lambda x: x[1])[1]
# 计算边界框的中心点和宽度、高度
x_center = (min_x + max_x) / 2
y_center = (min_y + max_y) / 2
width = max_x - min_x
height = max_y - min_y
# 归一化坐标
x_center /= data['imagewidth']
y_center /= data['imageheight']
width /= data['imagewidth']
height /= data['imageheight']
# 获取类别索引
class_index = class_to_id[shape['label']]
# 写入txt文件
txt_file.write(f'{class_index} {x_center} {y_center} {width} {height}\n')
print("所有json文件的转换完成!")
同样的,大家只需要更改映射部分(带单引号部分为你的标签,只要改变单引号中的内容即可(即绿色部分!!),多余的标签可以删除)
# 定义类别名称到索引的映射
class_to_id = {
'1': 0,
'2': 1,
'3': 2,
'4': 3,
'5': 4,
'6': 5,
'7': 6,
'8': 7
}
还要修改一下输入输出目录(改成你自己的就好了):
# 标注文件所在的文件夹路径
json_folder_path = r"c:\users\21093\desktop\yolov5-lite-1.4\photo\other\images3"
# 输出标签文件的文件夹路径
output_base_path = r"c:\users\21093\desktop\yolov5-lite-1.4\yolov5-lite\data"
这里注意一下,最后我们要的txt文件会被程序分成“train”和“valid”两个文件夹 ,也就是训练集和验证集两个部分。训练集顾名思义即为用来训练模型的图像部分,验证集是未被放入训练的部分,训练完的模型最后会对验证集进行一次识别,通过验证集的结果来观察训练模型的准确度!
本程序把数据集拆分成训练集和验证集的比例为 9:1
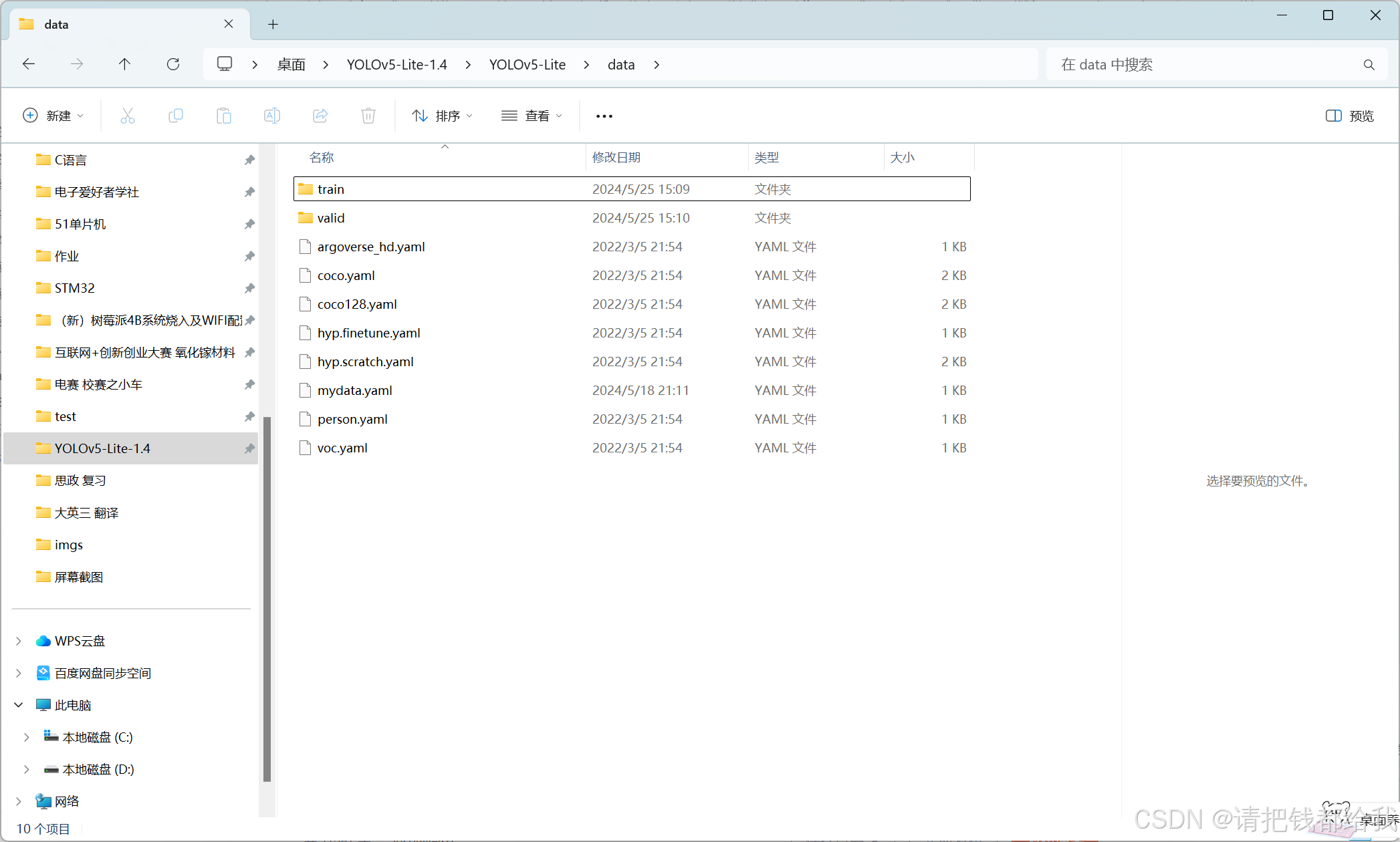
现在我们可以获得到这两个文件夹了!数据集制作的部分已经大功告成!接下来就是训练了!
温馨提示:大家一定要使用合格的数据集进行训练(即目标与背景语义丰富的数据集),这样训练出来的神经网络才具有良好的泛化性与鲁棒性,否则训练出来的网络很容易过拟合!
4.3 准备训练模型
github访问yolov5-lite的训练程序下载https://github.com/ppogg/yolov5-lite
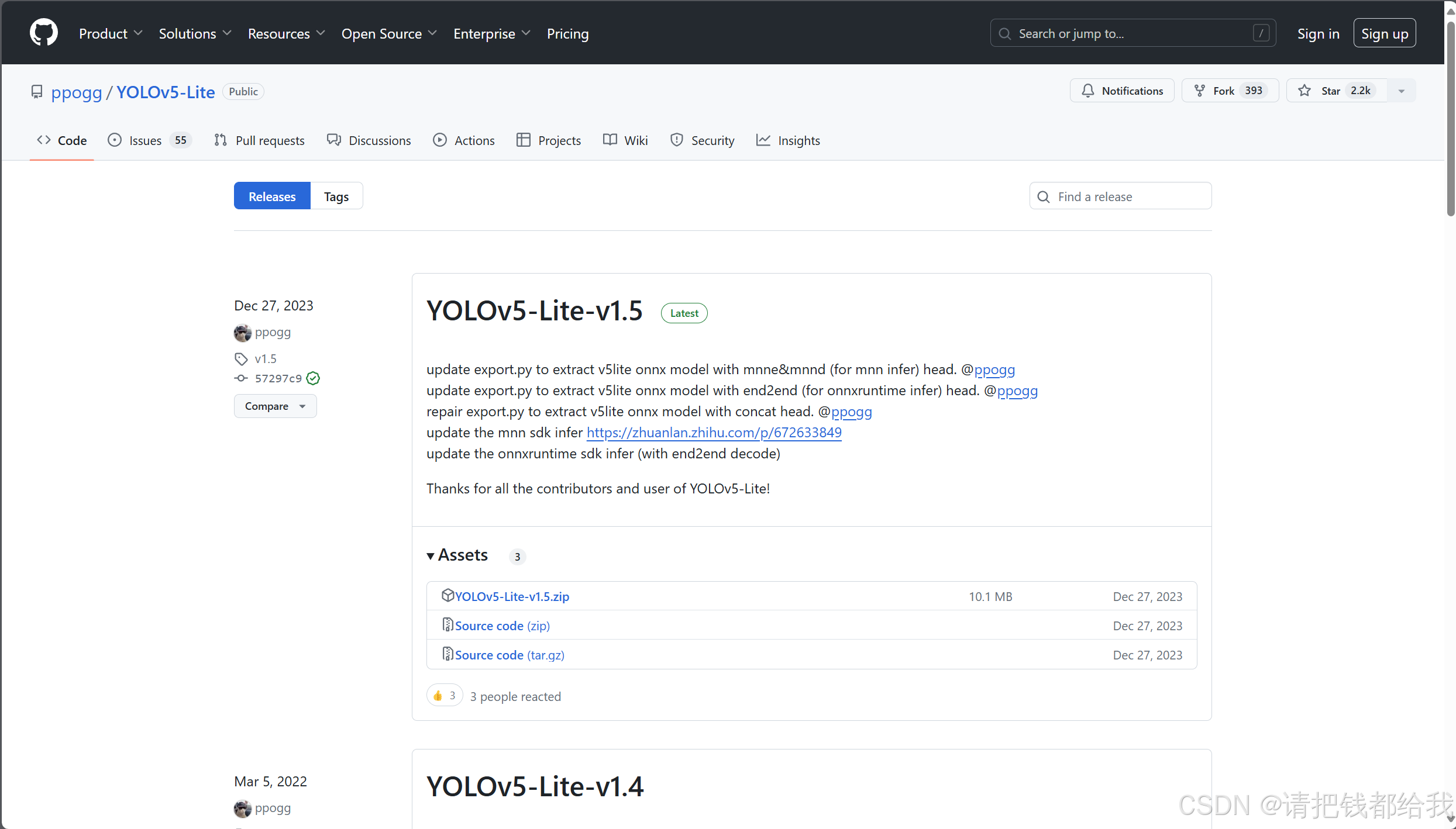
这里要千万注意!!!我们要下载的版本是v1.4!!!
不知道是什么原因,总之v1.5版本的训练会出错!!!之前笔者被这困扰了很久很久!
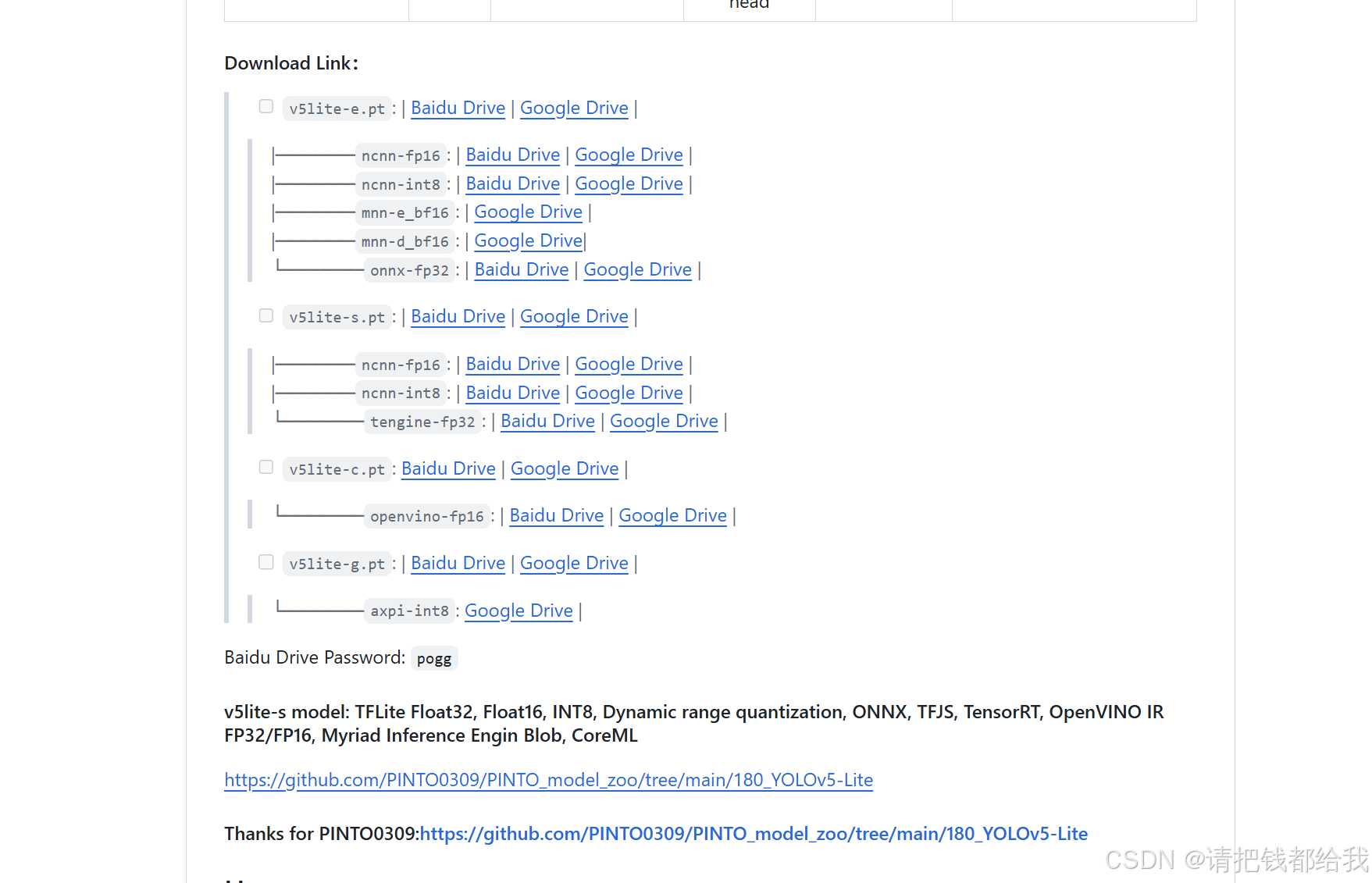
这一步记得要下载v5lite-s.pt哦!为什么选用这个呢?因为yolov5s 网络是 yolov5 系列中深度最小,特征图的宽度最小的网络,非常适合轻量化部署!
接下来我们把下载到的v5lite-s.pt放进解压好了的yolov5-lite文件夹里头
在 yolov5-lite 的目录下找到 train.py (训练文件)的 main 函数
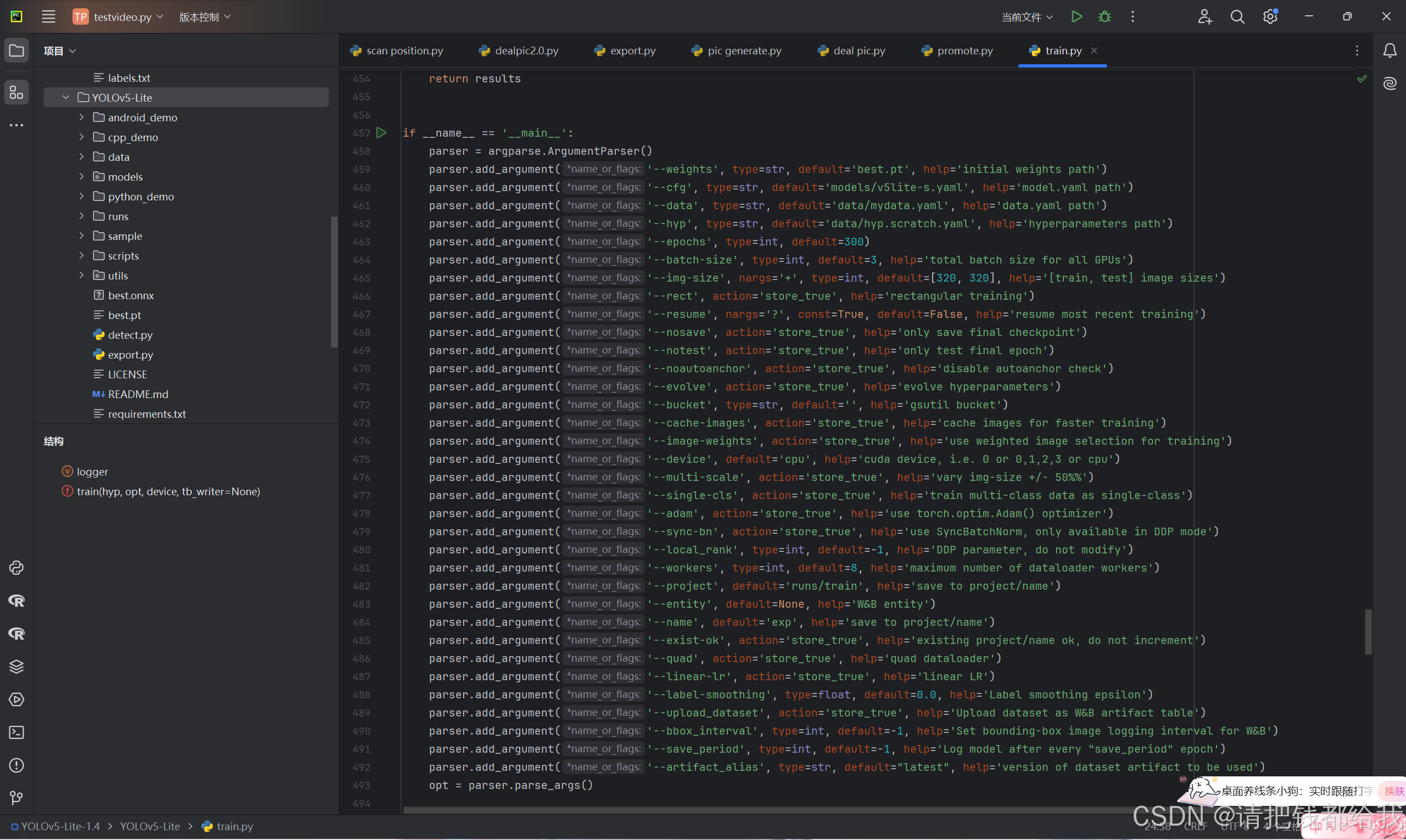
找到图片中的的代码按照以下参数进行修改(图片为修改过的):
'--weights', type=str, default='v5lite-s.pt', help='initial weights path'
'--cfg', type=str, default='models/v5lite-s.yaml', help='model.yaml path'
'--data', type=str, default='data/mydata.yaml', help='data.yaml path'
'--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path'
'--epochs', type=int, default=300
'--batch-size', type=int, default=3, help='total batch size for all gpus'
'--img-size', nargs='+', type=int, default=[320, 320], help='[train, test] image sizes'
'--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu'之后把数据集存放在data目录下:
对mydata.yaml文件进行以下修改(即按照注释填入相应的路径和标签即可):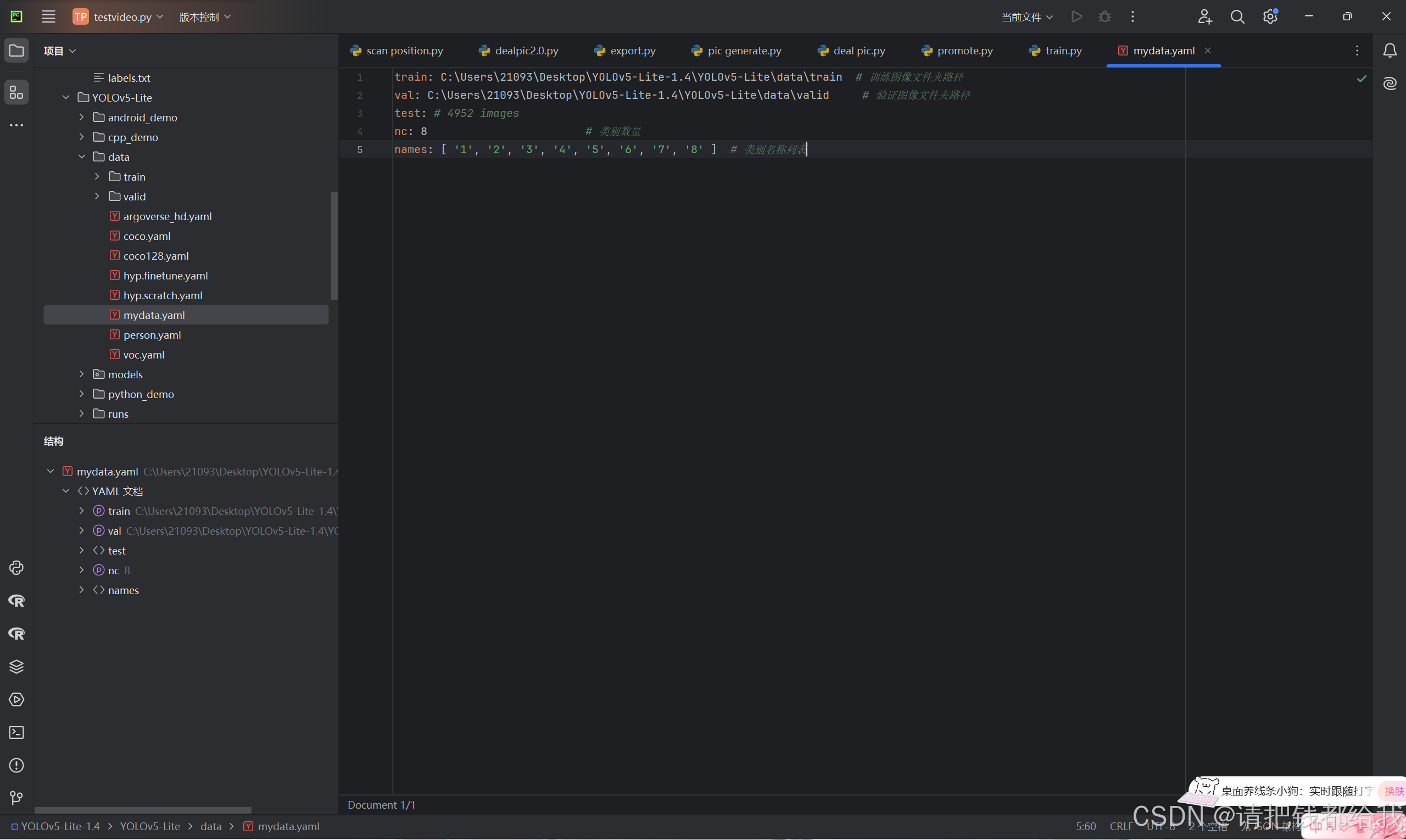
接下来要在pycharm里面安装必要的依赖,清单如下:
# pip install -r requirements.txt
# base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
pillow
pyyaml>=5.3.1
scipy>=1.4.1
torch>=1.8.0
torchvision>=0.9.0
tqdm>=4.41.0
# logging -------------------------------------
tensorboard>=2.4.1
# wandb
# plotting ------------------------------------
seaborn>=0.11.0
pandas
# export --------------------------------------
# coremltools>=4.1
# onnx>=1.9.1
# scikit-learn==0.19.2 # for coreml quantization
# extras --------------------------------------
thop # flops computation
pycocotools>=2.0 # coco map
这一切都就绪之后就可以愉快的点击train.py的运行按钮了,接下来就是漫长的训练等待!
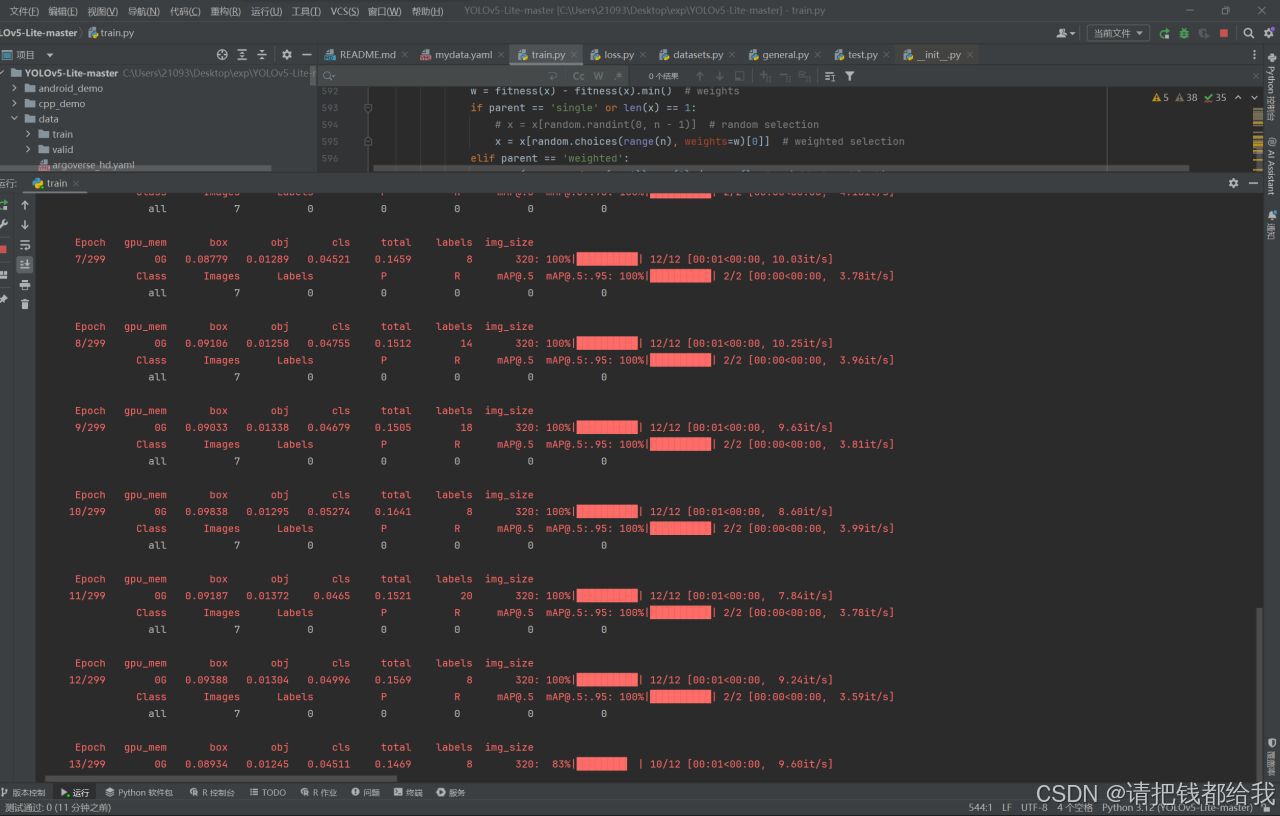
在训练完成之后,我们在yolov5-lite的目录下找到run这个文件夹并打开:
我们可以看到训练的数据图样和得到的权重文件weights
这个权重文件夹中有两个.pt文件,last.pt和best.pt,分别是最新权重和最佳权重
这个最佳权重是数次训练中得到效果最好的那一个
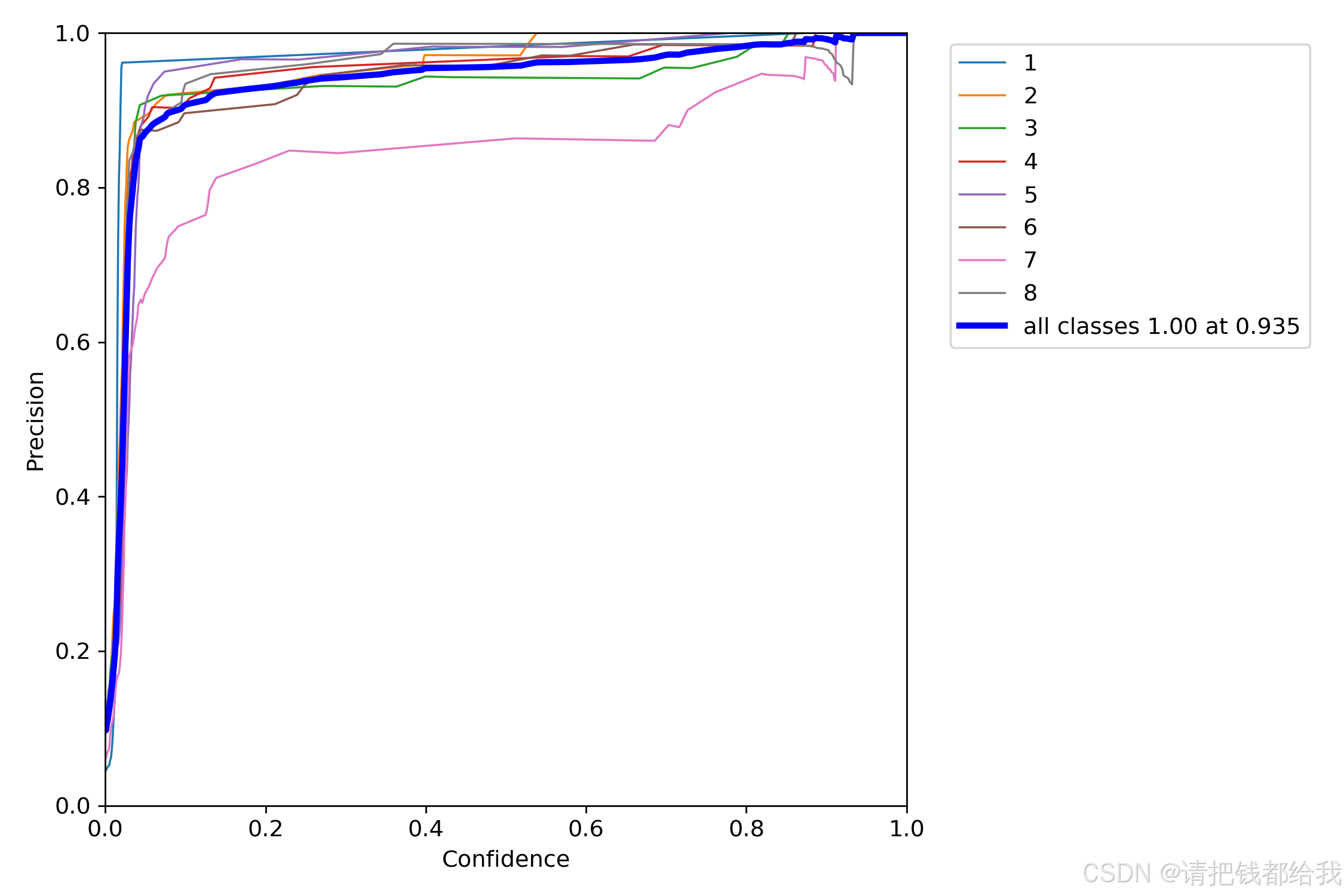
从这个图中可以看到每一条颜色的线代表一个数字的识别效果
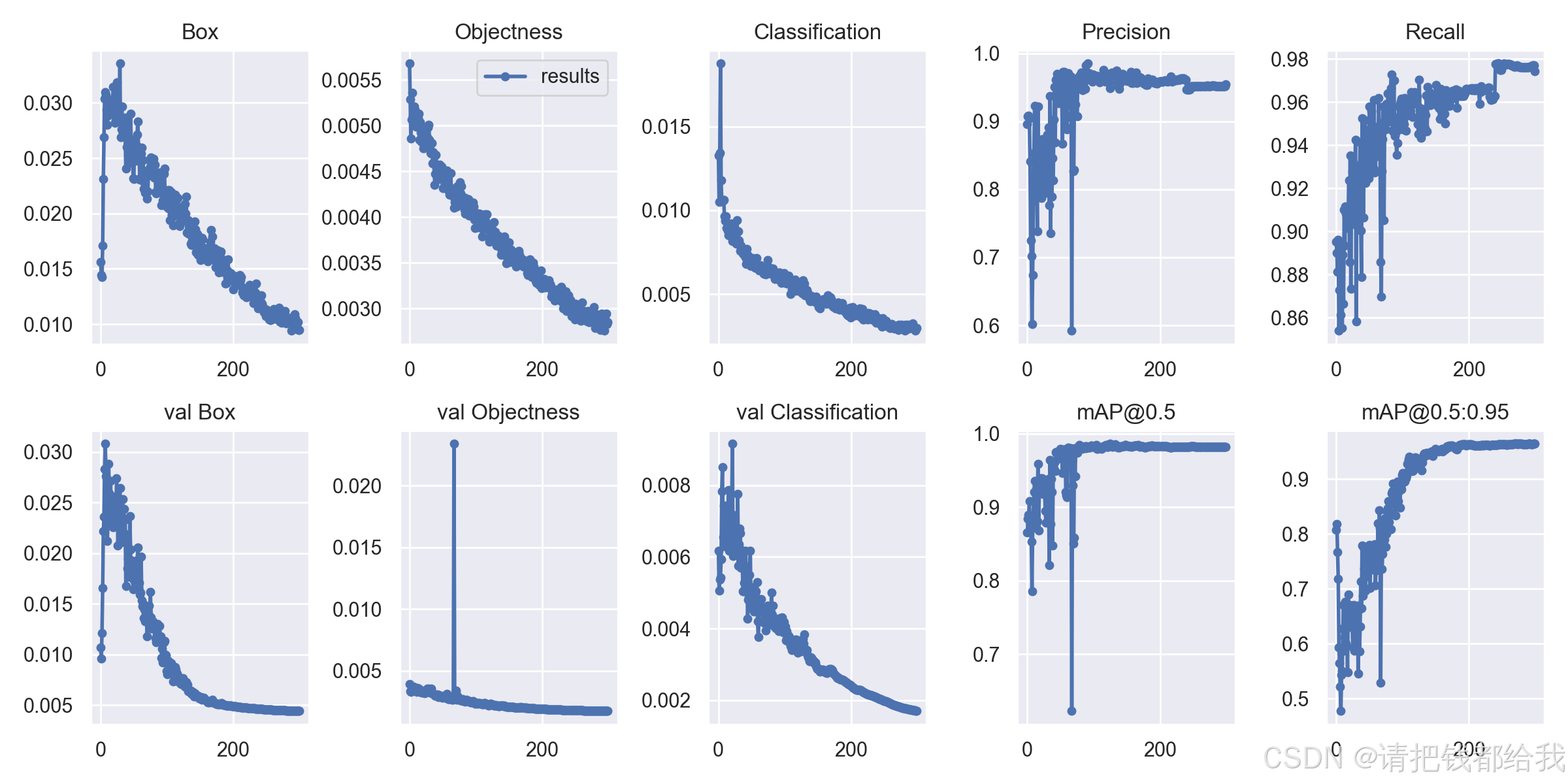
4.4 模型测试
以下是笔者写的一个运用训练好的模型进行实时的视频目标检测程序,启动该程序后按下s即开始检测,检测时会在左上角显示实时帧率,对检测到的数字会显示蓝色框并在框上显示识别到的数字以及识别的置信度,按下q则退出程序。大家可以将这个程序投喂给chatgpt4o来进行重生成,得到自己想要的目标检测程序:
import cv2
import numpy as np
import torch
import time
def plot_one_box(x, img, color=none, label=none, line_thickness=none):
"""
description: plots one bounding box on image img,
this function comes from yolov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, linetype=cv2.line_aa)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.gettextsize(label, 0, fontscale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.line_aa) # filled
cv2.puttext(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
linetype=cv2.line_aa,
)
def _make_grid(nx, ny):
xv, yv = np.meshgrid(np.arange(ny), np.arange(nx))
return np.stack((xv, yv), 2).reshape((-1, 2)).astype(np.float32)
def cal_outputs(outs, nl, na, model_w, model_h, anchor_grid, stride):
row_ind = 0
grid = [np.zeros(1)] * nl
for i in range(nl):
h, w = int(model_w / stride[i]), int(model_h / stride[i])
length = int(na * h * w)
if grid[i].shape[2:4] != (h, w):
grid[i] = _make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
grid[i], (na, 1))) * int(stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
anchor_grid[i], h * w, axis=0)
row_ind += length
return outs
def post_process_opencv(outputs, model_h, model_w, img_h, img_w, thred_nms, thred_cond):
conf = outputs[:, 4].tolist()
c_x = outputs[:, 0] / model_w * img_w
c_y = outputs[:, 1] / model_h * img_h
w = outputs[:, 2] / model_w * img_w
h = outputs[:, 3] / model_h * img_h
p_cls = outputs[:, 5:]
if len(p_cls.shape) == 1:
p_cls = np.expand_dims(p_cls, 1)
cls_id = np.argmax(p_cls, axis=1)
p_x1 = np.expand_dims(c_x - w / 2, -1)
p_y1 = np.expand_dims(c_y - h / 2, -1)
p_x2 = np.expand_dims(c_x + w / 2, -1)
p_y2 = np.expand_dims(c_y + h / 2, -1)
areas = np.concatenate((p_x1, p_y1, p_x2, p_y2), axis=-1)
areas = areas.tolist()
ids = cv2.dnn.nmsboxes(areas, conf, thred_cond, thred_nms)
if len(ids) > 0:
return np.array(areas)[ids], np.array(conf)[ids], cls_id[ids]
else:
return [], [], []
def infer_img(img0, model, model_h, model_w, nl, na, stride, anchor_grid, thred_nms=0.4, thred_cond=0.5):
# 图像预处理
img = cv2.resize(img0, [model_w, model_h], interpolation=cv2.inter_area)
img = cv2.cvtcolor(img, cv2.color_bgr2rgb)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
# 转换为torch tensor
blob = torch.from_numpy(blob).to(device)
# 模型推理
with torch.no_grad():
outs = model(blob)[0].cpu().numpy().squeeze(axis=0)
# 输出坐标矫正
outs = cal_outputs(outs, nl, na, model_w, model_h, anchor_grid, stride)
# 检测框计算
img_h, img_w, _ = np.shape(img0)
boxes, confs, ids = post_process_opencv(outs, model_h, model_w, img_h, img_w, thred_nms, thred_cond)
return boxes, confs, ids
if __name__ == "__main__":
# 模型加载
weights_path = "best.pt"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load(weights_path, map_location=device)['model'].float().fuse().eval().to(device)
# 标签字典
dic_labels = {
0: '1',
1: '2',
2: '3',
3: '4',
4: '5',
5: '6',
6: '7',
7: '8'
}
# 模型参数
model_h = 320
model_w = 320
nl = 3
na = 3
stride = [8., 16., 32.]
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
anchor_grid = np.asarray(anchors, dtype=np.float32).reshape(nl, -1, 2)
video = 0
cap = cv2.videocapture(video)
flag_det = false
while true:
success, img0 = cap.read()
if success:
if flag_det:
t1 = time.time()
det_boxes, scores, ids = infer_img(img0, model, model_h, model_w, nl, na, stride, anchor_grid, thred_nms=0.4, thred_cond=0.5)
t2 = time.time()
for box, score, id in zip(det_boxes, scores, ids):
label = '%s:%.2f' % (dic_labels[id], score)
plot_one_box(box.astype(np.int16), img0, color=(255, 0, 0), label=label, line_thickness=none)
str_fps = "fps: %.2f" % (1. / (t2 - t1))
cv2.puttext(img0, str_fps, (50, 50), cv2.font_hershey_complex, 1, (0, 255, 0), 3)
cv2.imshow("video", img0)
key = cv2.waitkey(1) & 0xff
if key == ord('q'):
break
elif key & 0xff == ord('s'):
flag_det = not flag_det
print(flag_det)
cap.release()
该程序的演示效果可以观看文章开头展示的视频哦
训练好的模型可以根据其实际使用效果(置信度、识别准确率、识别速度等)进行调整,可以通过改变训练的次数、多次训练,改变基础权重、换用更高质量的数据集等方式来提高模型的实战效果
4.5 模型转换
先来介绍一下要用的onnx:open neural network exchange(onnx)是一个开放的生态系统,具体是什么不需要过深的了解,只需要知道onnx支持许多框架(tensorflow, pytorch, keras, mxnet, matlab等等),这些框架中的模型都可以导出或者转换为标准onnx格式。模型采用onnx格式后,就可在各种平台和设备上运行。
接下来我们要做的就是把.pt文件转换为.onnx文件,作者在项目中已经预留了 export.py 文件将该神经网络模型进行转换到 onnx 模型,方便大家实际情况下部署使用。
4.5.1 转换方式①
在这里笔者写了一个程序,可以直接把主目录下的best.pt文件转换为best.onnx,不用作者留下的export.py文件(程序中的路径可以自由更改):
import sys
import time
import torch
import torch.nn as nn
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import models
from models.experimental import attempt_load
from utils.activations import hardswish, silu
from utils.general import set_logging, check_img_size
from utils.torch_utils import select_device
def export_model(weights_path, img_size=(320, 320), batch_size=1, device='cpu', dynamic=false, grid=false, concat=true):
set_logging()
t = time.time()
# load pytorch model
device = select_device(device)
model = attempt_load(weights_path, map_location=device) # load fp32 model
# checks
gs = int(max(model.stride)) # grid size (max stride)
img_size = [check_img_size(x, gs) for x in img_size] # verify img_size are gs-multiples
# input
img = torch.zeros(batch_size, 3, *img_size).to(device) # image size(1,3,320,320) idetection
# update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.conv): # assign export-friendly activations
if isinstance(m.act, nn.hardswish):
m.act = hardswish()
elif isinstance(m.act, nn.silu):
m.act = silu()
elif isinstance(m, models.yolo.detect):
m.forward = m.cat_forward if concat else m.forward # assign forward (optional)
model.model[-1].export = not grid # set detect() layer grid export
print(model.model[-1])
y = model(img) # dry run
# onnx export
try:
import onnx
print('\nstarting onnx export with onnx %s...' % onnx.__version__)
f = weights_path.replace('.pt', '.onnx') # filename
torch.onnx.export(model, img, f, verbose=false, opset_version=12, input_names=['images'],
output_names=['classes', 'boxes'] if y is none else ['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # size(1,3,640,640)
'output': {0: 'batch', 2: 'y', 3: 'x'}} if dynamic else none)
# checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
print('onnx export success, saved as %s' % f)
except exception as e:
print('onnx export failure: %s' % e)
# finish
print('\nexport complete (%.2fs). visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))
if __name__ == '__main__':
weights_path = r'c:\users\21093\desktop\yolov5-lite-1.4\best.pt' # 直接指定权重路径
export_model(weights_path)
4.5.2 转换方式②
使用作者留下的转换程序的方法:
将你想要转换的best.pt文件放在主目录下,打开命令提示符,键入以下代码:
python export.py --weights best.pt即会在主目录下生成一个best.onnx文件!
五、树莓派移植与部署
5.1 软件部分②
笔者在这篇文章上附带了树莓派上所需要的依赖包,大家只需要解压到树莓派上并进行逐个安装即可!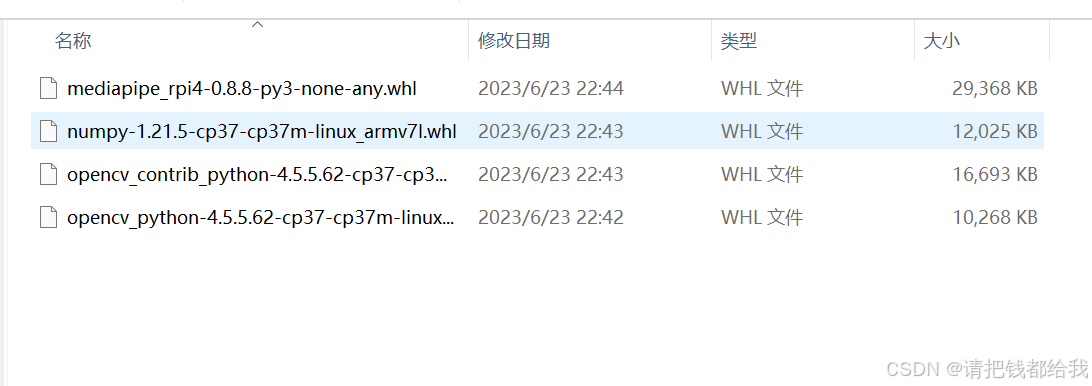
上图中四个whl文件大家使用pip安装即可,安装方法给出代码如下:
cd home/pi/projects/myproject(先用cd按照路径进入储存文件的文件夹)
pip install xxxxx(打出部分文件名后按下tab来补全,回车安装即可)5.2 验证与调整
接下来把yolov5-lite的源码导入进树莓派,把训练好的权重文件(.onnx)放在主目录中,把目标检测程序(代码如下)也放进去,并运行:
import cv2
import numpy as np
import onnxruntime as ort
import time
def plot_one_box(x, img, color=none, label=none, line_thickness=none):
"""
description: plots one bounding box on image img,
this function comes from yolov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, linetype=cv2.line_aa)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.gettextsize(label, 0, fontscale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.line_aa) # filled
cv2.puttext(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
linetype=cv2.line_aa,
)
def _make_grid( nx, ny):
xv, yv = np.meshgrid(np.arange(ny), np.arange(nx))
return np.stack((xv, yv), 2).reshape((-1, 2)).astype(np.float32)
def cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride):
row_ind = 0
grid = [np.zeros(1)] * nl
for i in range(nl):
h, w = int(model_w/ stride[i]), int(model_h / stride[i])
length = int(na * h * w)
if grid[i].shape[2:4] != (h, w):
grid[i] = _make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
grid[i], (na, 1))) * int(stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
anchor_grid[i], h * w, axis=0)
row_ind += length
return outs
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
areas = areas.tolist()
ids = cv2.dnn.nmsboxes(areas,conf,thred_cond,thred_nms)
if len(ids)>0:
return np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]
else:
return [],[],[]
def infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5):
# 图像预处理
img = cv2.resize(img0, [model_w,model_h], interpolation=cv2.inter_area)
img = cv2.cvtcolor(img, cv2.color_bgr2rgb)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
# 模型推理
outs = net.run(none, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
# 输出坐标矫正
outs = cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride)
# 检测框计算
img_h,img_w,_ = np.shape(img0)
boxes,confs,ids = post_process_opencv(outs,model_h,model_w,img_h,img_w,thred_nms,thred_cond)
return boxes,confs,ids
if __name__ == "__main__":
# 模型加载
model_pb_path = "best.onnx"
so = ort.sessionoptions()
net = ort.inferencesession(model_pb_path, so)
# 标签字典
dic_labels = {
0: '1',
1: '2',
2: '3',
3: '4',
4: '5',
5: '6',
6: '7',
7: '8'
}
# 模型参数
model_h = 320
model_w = 320
nl = 3
na = 3
stride=[8.,16.,32.]
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
anchor_grid = np.asarray(anchors, dtype=np.float32).reshape(nl, -1, 2)
video = 0
cap = cv2.videocapture(video)
flag_det = false
while true:
success, img0 = cap.read()
if success:
if flag_det:
t1 = time.time()
det_boxes,scores,ids = infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5)
t2 = time.time()
for box,score,id in zip(det_boxes,scores,ids):
label = '%s:%.2f'%(dic_labels[id],score)
plot_one_box(box.astype(np.int16), img0, color=(255,0,0), label=label, line_thickness=none)
str_fps = "fps: %.2f"%(1./(t2-t1))
cv2.puttext(img0,str_fps,(50,50),cv2.font_hershey_complex,1,(0,255,0),3)
cv2.imshow("video",img0)
key=cv2.waitkey(1) & 0xff
if key == ord('q'):
break
elif key & 0xff == ord('s'):
flag_det = not flag_det
print(flag_det)
cap.release() 大家可以借鉴此代码,或通过ai工具生成符合自己需要的代码
需要更改的地方最主要的就是模型名称和标签字典的对应
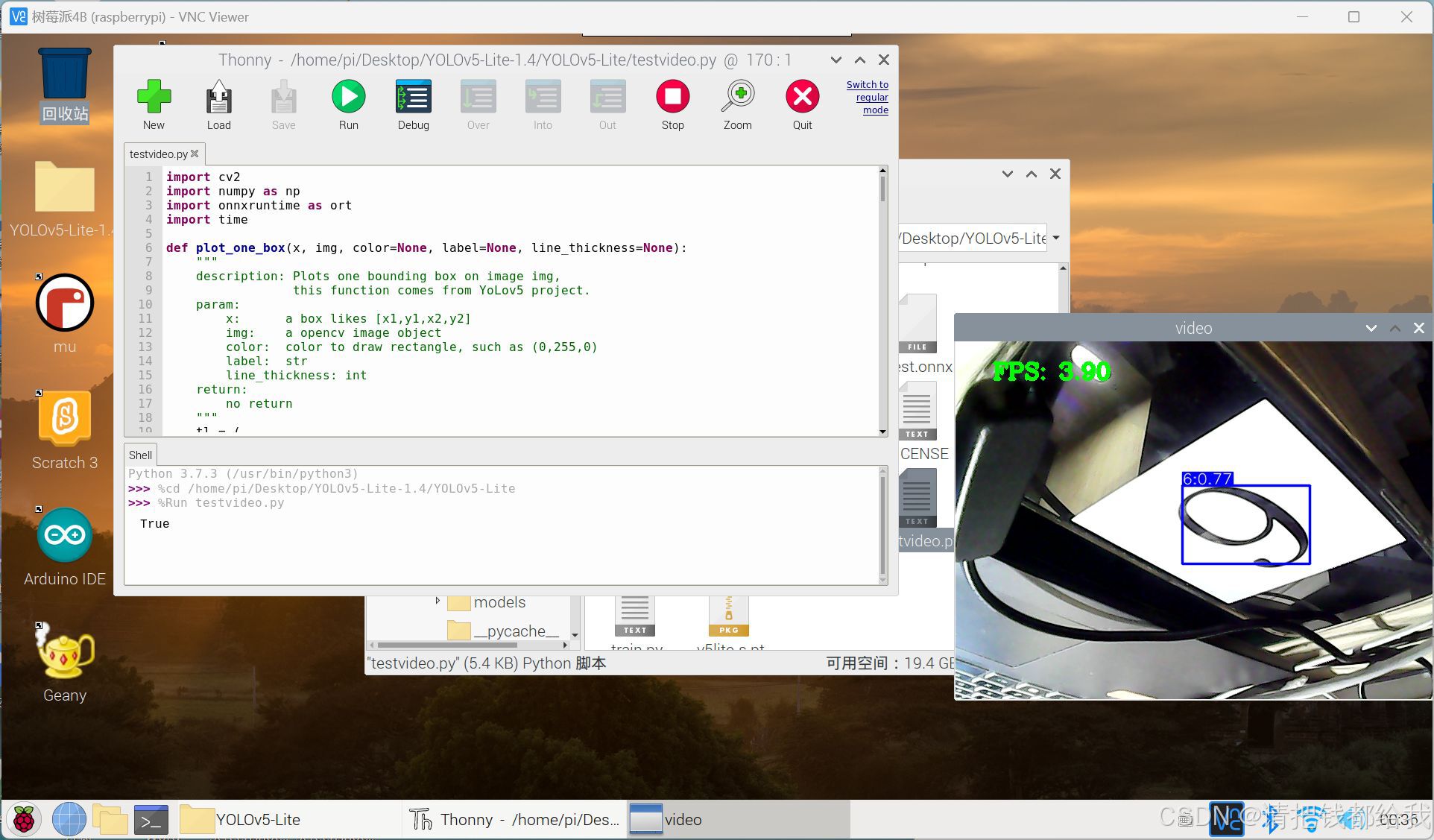
在树莓派上运行成功的效果展示
相信做到这里的大家都如愿在树莓派上跑起自己的模型了,笔者在树莓派上运行程序的帧率在5帧上下,大家可以对程序进行修改来达到更高的帧率,或者通过ncnn模型来加速
5.3 笔者总结(疑难解惑)
在整个训练的过程中,最麻烦的地方就是依赖的配置:因为随着各个依赖版本的更新,有些语法在新版本中被抛弃了,有些依赖的语法发生了改变(比如numpy的数组溢出问题)。笔者在配置环境的时候也遇到了很多问题,不过好在能够寻求csdn的帮助和运用ai工具,很多问题都迎刃而解了。相信大家只要肯钻研,花时间,总能做好的!
六、资源分享
笔者在这里把自己训练好的树莓派数字识别程序分享在百度网盘上,后续还有其他资源需要以及疑问的可以发送邮件至邮箱2109323427@qq.com
百度网盘:yolo-树莓派-数字识别检测程序,提取码fzdxhttps://pan.baidu.com/s/1bkszsftwi--alp7km0-ohg
最后,各位都看到这里了,希望大家不吝给我点个关注哦,谢谢大家~
七、更新与改动情况
2024.7.25——改变了图片数据增强和自动标注程序,修改了错误
发表评论