网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
3.线程协调器 管理线程

tf.train.coordinator()
线程协调员,实现一个简单的机制来协调一组线程的终止
request\_stop()
should\_stop() 检查是否要求停止
join(threads=none, stop_grace_period_secs=120)
等待线程终止
return:线程协调员实例
案例:通过队列管理器来实现变量加1,入队,主线程出队列的操作,观察效果?(异步操作)
import tensorflow as tf
# 模拟异步 子线程:存入样本 ,主线程:读取样本
# 1、定义一个队列,1000
q = tf.fifoqueue(1000, tf.float32)
# 2、定义子线程要做的事情 循环 值 +1 ,放入队列中
var = tf.variable(0.0)
# 不能用data = var + 1
#实现一个自增, tf.assign_add
# data = tf.assign\_add(var, tf.constant(1.0))
data = tf.assign\_add(var , tf.constant(1.0))
en_q = q.enqueue(data)
# 3、定义队列管理器 op,指定多少个子线程 以及 子线程该干什么
qr = tf.train.queuerunner(q, enqueue_ops=[en_q] \* 2)
# 初始化变量 op
init_op = tf.global\_variables\_initializer()
with tf.session() as sess:
# 初始化变量
sess.run(init_op)
# 开启线程管理器
coord = tf.train.coordinator()
# 开启真正子线程
threads = qr.create\_threads(sess, coord=coord ,start=true) # 指定老大是coord
# 主线程,不断读取数据训练
for i in range(300):
print(sess.run(q.dequeue()))
# 回收你
coord.request\_stop()
coord.join(threads) # 听老大的话
4.文件读取流程
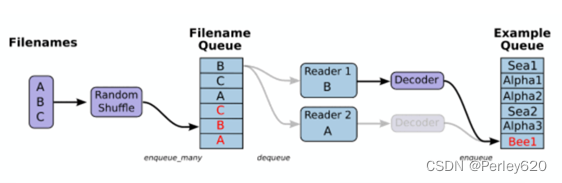
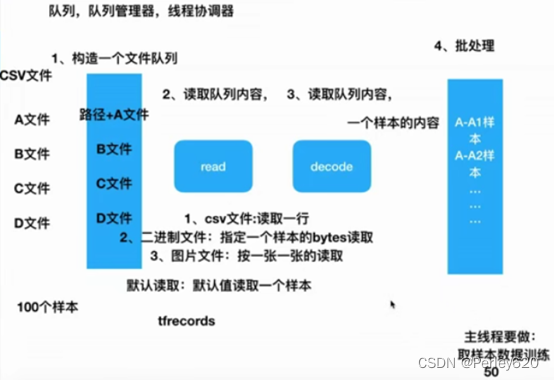
1.文件读取api-文件队列构造

tf.train.string\_input\_producer(string_tensor , shuffle=true)
将输出字符串(例如文件名)输入到管道队列
string_tensor 含有文件名的1阶张量
num_epochs : 过几遍数据,默认无限过数据
return : 具有输出字符串的队列
2.文件读取api-文件阅读器

根据文件格式,选择对应的文件阅读器
class tf.textlinereader
阅读文本文件逗号分隔值(csv)格式 , 默认按行读取
return:读取器实例
tf.fixedlengthrecordreader(record_bytes)
要读取每个记录是固定数量字节的二进制文件
record_bytes:整型,指定每次读取的字节数
return:读取器实例
tf.tfrecordreader
读取tfrecords文件
有一个共同的读取方法:read(file_queue):从队列中指定数量内容
返回一个tensors元组(key文件名字,value默认的内容(行,字节))
3.文件读取api-文件内容解码器

4.开启线程操作

5.管道读端批处理

案例:csv文件读取

import tensorflow as tf
import os
def csvread(filelist):
'''
读取csv文件
:param filelist: 文件路径+名字的列表
:return: 读取的内容
'''
# 2\构造文件队列
file_queue = tf.train.string\_input\_producer(filelist)
# 3\构造csv阅读器读取队列数据(按照一行)
reader = tf.textlinereader()
key , value = reader.read(file_queue)
# 4\对每行数据进行解码
# record_defaults: 指定每一个样本的每一列的类型,指定默认值
records = [["none"],[4.0]] #指定两列的默认值为字符串和float
example, label = tf.decode\_csv(value, record_defaults=records) #有两列,两个参数接受
# 5\想要读取多个数据,就需要批量处理
# 批处理大小,跟队列,数据的数量没有影响,只决定这批次读取多少数据
example_batch ,label_batch= tf.train.batch([example, label],batch_size=9,num_threads = 1,capacity = 9)
return example_batch ,label_batch
if __name__ == '__main__':
# 1\找到文件,放入列表 路径+名字 放入列表当中
file_name = os.listdir("./data/csvdata/")
filelist = [os.path.join("./data/csvdata/" , file) for file in file_name]
example_batch,label_batch = csvread(filelist)
# 开启会话运行结果
with tf.session() as sess:
# 定义一个线程协调器
coord = tf.train.coordinator()
# 开启读取文件的线程
threads = tf.train.start\_queue\_runners(sess, coord=coord)
# 打印读取的内容
print(sess.run([example_batch,label_batch]))
#回收子线程
coord.request\_stop()
coord.join(threads) # 听老大的话
5.图片文件

import tensorflow as tf
import os
def picread(filelist):
"""
读取狗图片并转换成张量
:param filelist: 文件路径+ 名字的列表
:return: 每张图片的张量
"""
# 1、构造文件队列
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化的资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
1715284906267)]
[外链图片转存中...(img-p68xzi5q-1715284906267)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化的资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**


发表评论