网关日志接入elasticsearch调研和使用
背景
elasticsearch简介
elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
elasticsearch 在 apache lucene 的基础上开发而成,由 elasticsearch n.v.(即现在的 elastic)于 2010 年首次发布。elasticsearch 以其简单的 rest 风格 api、分布式特性、速度和可扩展性而闻名。
elasticsearch可以做什么
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
为什么选择elasticsearch
elasticsearch 很快。由于 elasticsearch 是在 lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
elasticsearch 具有分布式的本质特征。elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 pb 量级的数据。
elasticsearch 包含一系列广泛的功能。除了速度、可扩展性和弹性等优势以外,elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
elasticsearch与mysql的比较
elasticsearch与mysql的类比关系
| elasticsearch | mysql |
|---|---|
| index(索引库) | database(数据库) |
| type(类型)注:高版本已舍弃 | table(表) |
| docment(文档) | row(行) |
| field(字段) | column(列) |
| mapping(映射) | schmea(约束) |
elasticsearch与mysql的优劣势
- elasticsearch是分布式的这个可以很容易的横向扩容,而mysql不行。
- 在数据存储量及性能上,mysql由于其索引实现(innodb为例)导致在数据量大到一定级别后会出现性能衰减,一般认为mysql单表最大不超好500万可以获得最佳性能,
而elasticsearch 只要内存够大,就可以存储pb级数据。 - 在查询方面,elasticsearch使用索引倒排序在数据量大的情况下,查询更快,但是在关联查询上,mysql当仁不让。
- 事务方面,elasticsearch不支持事务,mysql支持事务,在处理多表业务逻辑上有巨大优势。
- 易用性上mysql传统简单好上手,elasticsearch在资源配置,环境搭建上更需要专业的运维人员。
如何接入数据到elasticsearch
-
使用elasticsearch rest风格api
适合并发不高,直接调用的方式,接入简单。 -
接收mq消息直接写入
异步解耦,依赖各mq自身提供的插件。此类方式使用人少,文档不全,不建议使用。 -
使用logstash对数据进行聚合和处理,并将数据发送到elasticsearch
logstash可以针对多种数据源进行处理,之后在写入elasticsearch,该方式成熟,文档健全,社区活跃,是elasticsearch官方推荐的使用方式。基于业务自身情况,我们这里使用第三种方式接入elasticsearch,那么对于logstash的数据源我们又该如何选择。由于日志对于主业务流程不是必须的, 所以采用异步解藕的方式进行记录,这里有2个方案可以选择rabbitmq 和kafka。这2种接入方式都是通过logstash自身已经集成的插件实现,只不过在社区活跃度、实际案例使用(kafka接入logstash更多)、和公司现有架构(公司大数据消息中间件基本选择kafka)的考虑选择kafka接入logstash发送到elasticsearch。
elasticsearch java api选择
elasticsearch 官方提供了java语言的api,不过在现有springboot 框架下已经实现了对elasticsearch的相关封装,因此在实际开发中建议使用spring-boot-starter
maven坐标如下:
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-data-elasticsearch</artifactid>
</dependency>
需要注意的是在高版本elasticsearch7.x以上要求springboot 版本为2.3.x 以上版本,如果springboot 版本低于此版本请降低elasticsearch版本或者手动引入elasticsearch maven坐标,并自行配置配置文件。
spring-boot-starter-data-elasticsearch 的实现方式如何选择
| 方式 | 优缺点 | 是否推荐 |
|---|---|---|
| resthighlevelclient | 原始高基级别api能完成各自查询,语法复杂,学习成本高 | 如果对elasticsearch比较熟悉并且项目没有使用springboot建议使用 |
| elasticsearchrepository | springdata-jpa 通用api使用简单,容易上手,不过在高级别elasticsearch中很多方法已经过时 | 如果是简单插入,简单查询推荐使用,复杂查询不推荐 |
| elasticsearchtemplate | spring封装的模版方法,简单易用,不过在高版本已经过时 | 不推荐使用 |
| elasticsearchresttemplate | spring基于高版本api最新的模板方法,使用简单支持各种复杂查询,看文档后很容易上手 | 在高版本推荐使用 |
elasticsearch 索引生命周期使用
索引生命周期分为4个阶段:hot、warm、cold、delete,其中hot主要负责对索引进行rollover操作,hot阶段是必须的其他3个阶段为非必须。
rollover:滚动更新创建的新索引将添加到索引别名,并被指定为写索引。
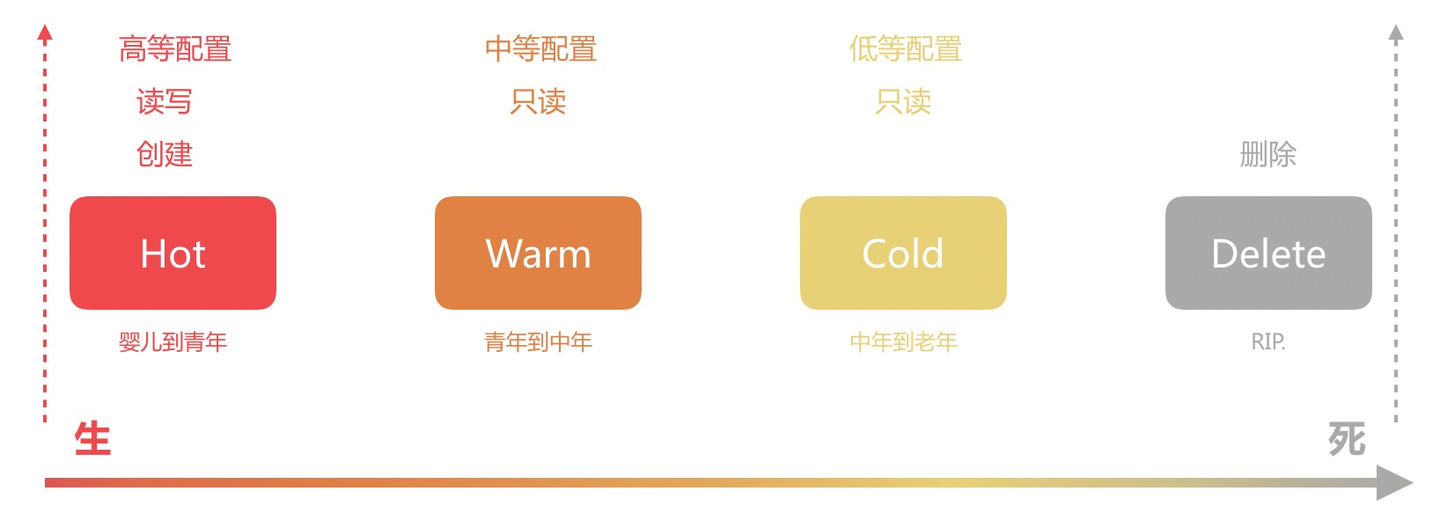
elasticsearch 生命周期可以单独给某个索引进行设置策略,也可以通过索引模版进行设置。要注意的是,如果给某个索引单独设置生命周期策略,那么当索引到下一个周期时则不会使用用上一个周期的策略。
如果使用模板对索引生命周期进行配置,则索引到下一个周期会复用上一个周期的策略。因此在实际开发中,我们会选择索引模版进行生命周期的管理。
elasticsearch 索引生命周期创建步骤
- 创建索引生命周期策略 put _ilm/policy/logstash-demo-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover":{
"max_age":"7d"
}
}
},
"delete": {
"min_age": "23d",
"actions": {
"delete": {}
}
}
}
}
}
这里定义了两个阶段,hot阶段保留7天,然后进入delete再保留23天。亦即索引保留30天。
- 创建索引模板 put _template/demo-log-template
{
"index_patterns": ["demo*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "logstash-demo-policy",
"index.lifecycle.rollover_alias": "demo"
}
}
注意:这里的分片和副本需要根据自己的业务自行设置,这里仅仅是基本的设置,其他的mapping设置这里不在展示。
index.lifecycle.name =第一步创建的生命周期策略
- 创建索引 put demo-000001
{
"aliases": {
"demo": {
"is_write_index": true
}
}
}
这里创建索引只指定了别名,其他参数使用默认。实际开发中要根据自己的业务需要进行创建。
需要注意这个索引并非最终写入端使用的索引,别名才是,这个索引只是为了滚动所需。注意命名要求。命名必须小写字母开口必须包含-必须已数字结尾,这里在官方文档上没有说明,但是在7.9.3版本中如果不按照此规则命名会报错。
因为别名是匹配的,因此会自动应用上前边创建的策略,这也是为什么推荐模版创建生命周期的原因,此时写入方指定的索引名为demo。
在这个索引创建7天之后,就会触发rollover,将老的数据定义到delete阶段,然后新建一个索引,名字应该为:demo-000002,再过23天之后,demo-000002会进入delete阶段,并生成demo-000003 ,然后 demo-000001会被删除,如此循环往复下去。
上边的步骤也可以通过kibana的页面就行创建,也可以查看具体的索引生命周期。
基于open distro插件管理索引生命周期
open distro 将 elasticsearch和kibana的oss发行版与大量开源插件相结合。这些插件填补了oss发行版中的重要功能空白。
基于open distro 管理索引的生命周期(ism)和elasticsearch原有的生命周期管理(ilm)大致思想是一样的,只是请求rest和body有一些差别。
- 创建索引生命周期策略 put __opendistro/_ism/policies/logstash-demo-uat
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"states": [
{
"name": "hot",
"actions": [
{
"rollover": {
"min_index_age": "1h"
}
}
],
"transitions": [
{
"state_name": "warm"
}
]
},
{
"name": "warm",
"actions": [
],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_index_age": "2h"
}
}
]
},
{
"name": "delete",
"actions": [
{
"delete": {}
}
]
}
]
}
}
这里定义了3个阶段,hot阶段保留1h,然后进入warm。当索引存在2h后进行删除
- 创建索引模板 put _index_template/demo-uat-log-template
{
"index_patterns":[
"demo-log-uat*"
],
"template":{
"settings":{
"opendistro.index_state_management.rollover_alias":"demo-log-uat",
"opendistro.index_state_management.policy_id": "logstash-demo-uat"
},
"mappings":{
"properties":{
"request":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"ip":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"servicename":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"routename":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"requesttime":{
"format":"uuuu-mm-dd hh:mm:ss",
"type":"date"
},
"@timestamp":{
"type":"date"
},
"routeid":{
"type":"long"
},
"response":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"@version":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"isvname":{
"type":"text",
"fields":{
"keyword":{
"ignore_above":256,
"type":"keyword"
}
}
},
"isvid":{
"type":"long"
},
"id":{
"type":"long"
},
"serviceid":{
"type":"long"
}
}
}
}
}
- 创建索引 put demo-log-uat-000001
{
"aliases": {
"demo-log-uat": {
"is_write_index": true
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"id": {
"type": "long"
},
"ip": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"isvid": {
"type": "long"
},
"isvname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"request": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"requesttime": {
"type": "date",
"format": "uuuu-mm-dd hh:mm:ss"
},
"response": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"routeid": {
"type": "long"
},
"routename": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"serviceid": {
"type": "long"
},
"servicename": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"refresh_interval": "1s",
"number_of_shards": "1",
"store": {
"type": "fs"
},
"priority": "100",
"number_of_replicas": "0"
}
}
}
elasticsearch 配置
在测试环境配置1个分片0个副本,经过测试1万行日志(大数据经过截取,出参和入参都是1024长度)数据大约7m 每天700万 每天就是4.78g 每月143.55g
按照每天2000万异常数据每天就是13.67g每月就是410.15g。建议这样的数据量建议配置6个分片,日志数据不是十分重要的数据建议不添加副本节省空间。如果日志量大,可以随时调整索引的生命周期策略。
elasticsearch 查询优化
根据elasticsearch相关文档,elasticsearch 分页查询如果数据量很大,越往后翻页,查询速度会越慢,这是因为elasticsearch默认采用的分页方式是from+size的形式,但是在深度分页的情况下,这种使用方式的效率是非常低的。
因此elasticsearch分页查询默认最大返回1万行数据,实际使用中此操作很少,业务使用场景大多是浅度分页,而且可以根据查询条件精确查询后在查看数据,暂时不需要优化。如果业务确实需要查询大于一万条的数据,也可以临时修改elasticsearch
的默认分页大小
put index/_settings
{
"index":{
"max_result_window":"size"
}
}
如果需要将来需要深度分页,可采取以下方式进行优化
scroll方式
为了满足深度分页的场景,elasticsearch提供了scroll的方式进行分页读取。原理上是对某次查询生成一个游标scroll_id,后续的查询只需要根据这个游标去取数据,直到结果集中返回的hits字段为空,就表示遍历结束。scroll的作用不是用于实时查询数据,
因为它会对es做多次请求,不能做到实时查询。它的主要作用是用来查询大量数据或全部数据。
使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景。这类似新浪微博一直下拉刷新数据,kibana查询es数据也是使用改方式。
logstash 部署
logstash连接kafka和elasticsearch, logstash为了保证高可用,在线上单独部署2个节点,单独处理数据不影响网关性能。
#consumer_threads这里可以根据kafka实际分区进行设置
input {
kafka {
bootstrap_servers => ["127.0.0.1:16492"]
topics => ["demo-visit-log-test"]
codec => json { charset => "utf-8" }
consumer_threads => 12
decorate_events => true
}
}
#线上还需要配置证书文件
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
username => "user"
password=> "password"
index => "demo-log"
document_id => "%{id}"
}
}

发表评论