apache hadoop概述
hadoop的功能组件
hadoop发展
hadoop版本
分布式的基础架构分析
hadoop中的hdfs集群和yarn集群都是主从模式架构.
hdfs的基础架构
hdfs的角色分配:
hdfs集群环境部署
前期准备:
下载hadoop安装包:
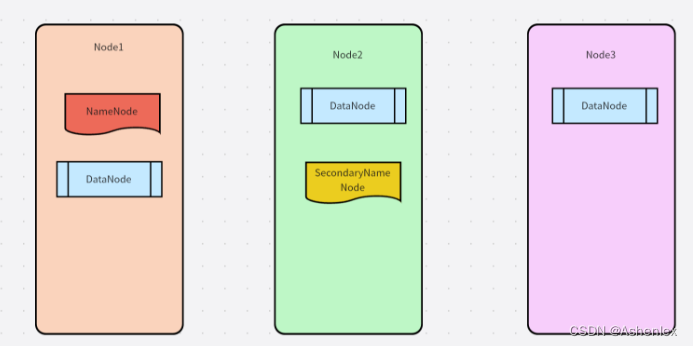
集群规划
node1: cpu 2*1 内存 4g 60g
node2: cpu 1*1 内存 2g 60g
node3: cpu 1*1 内存 2g 60g
通过分析可知, node1服务器性能最好,可以作为主服务使用,将我们的主角色部署在node1上
但是,namenode和secondarynamenode都是服务器内存消耗的大户,且snn会将nn的元数据进行获取合并,所以建议放置在两台不同的服务上
最优方案是每个服务一台服务器
角色分配
node1: namenode datanode
node2: datanode secondarynamenode
node3: datanode
node4 : datanode
node5 : datanode
.....
hadoop用户创建,并配置免密登录
vim core-site.xml # 在文件末尾添加如下内容 # 在文件内部填入如下内容 <property> <name>fs.defaultfs</name> <value>hdfs://node1:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> # 注意要卸载configuration的标签内部,多余的标签要删掉
打开hdfs-site.xml文件,配置hdfs的相关服务信息
# 在文件内部填入如下内容 <property> <name>dfs.datanode.data.dir.perm</name> <value>700</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/nn</value> </property> <property> <name>dfs.namenode.hosts</name> <value>node1,node2,node3</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/dn</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property>
准备数据存储目录
# 进入root权限,创建目录 # node1 mkdir -p /data/nn mkdir /data/dn # node2, node3 mkdir -p /data/dn
将hadoop目录复制到node2和node3中
scp -r /export/server/hadoop node2:/export/server scp -r /export/server/hadoop node3:/export/server
配置环境变量
export hadoop_home=/export/server/hadoop export path=$path:$hadoop_home/bin:$hadoop_home/sbin
注意:使用source /etc/profile进行激活
初始化namenode
hadoop namenode -format
启动服务
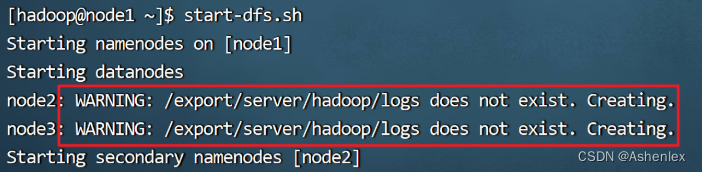
# 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh # 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行 /export/server/hadoop/sbin/start-dfs.sh /export/server/hadoop/sbin/stop-dfs.sh
警告不用在意,是告诉我们该目录之前没有,现在需要创建
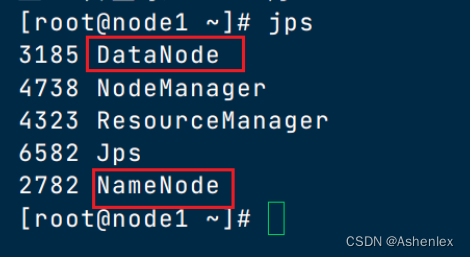
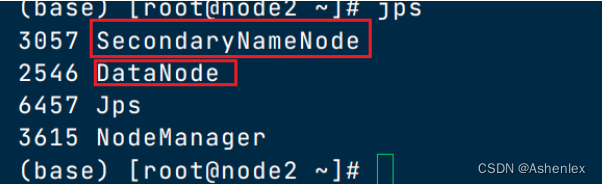
服务启动后,可以使用jps查看服务进程

如果出现服务启动问题去日志文件中找答案
四、hdfs的服务启停[重要]
对整个hadoop服务的启动和关闭
start-all.sh stop-all.sh
一键启停hdfs集群
# 一键启动 start-dfs.sh # 一键停止 stop-dfs.sh
单起单停
# 只能控制当前服务器中服务的启停 hdfs --daemon start|stop|status namenode|datanode|secondarynamenode
注意: 在开发中,一般我们的服务不会频繁启停,如果服务出现故障进行单起单停,否则影响面太广.
五、hdfs的shell操作(了解)
hdfs的完整路径:
hdfs://node1:8020/root/test
hdfs的文件结构和linux中基本一致 : 树状结构
文件和数据的区别???
hdfs的shell命令格式:
# 新写法 hdfs dfs -命令 [-选项] [参数] # 老写法 hadoop fs -命令 [-选项] [参数]
注意: 在hdfs dfs - 之后或hadoop fs -之后和linux终端指令基本没有区别
hadoop中的shell命令
usage: hadoop fs [generic options]
[-appendtofile <localsrc> ... <dst>]
[-cat [-ignorecrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-r] group path...]
[-chmod [-r] <mode[,mode]... | octalmode> path...]
[-chown [-r] [owner][:[group]] path...]
[-concat <target path> <src path> <src path> ...]
[-copyfromlocal [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-copytolocal [-f] [-p] [-crc] [-ignorecrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] [-t <thread count>] [-q <thread pool queue size>] <src> ... <dst>]
[-createsnapshot <snapshotdir> [<snapshotname>]]
[-deletesnapshot <snapshotdir> <snapshotname>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate] [-fs <path>]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-crc] [-ignorecrc] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>]
[-getfacl [-r] <path>]
[-getfattr [-r] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-c] [-d] [-h] [-q] [-r] [-t] [-s] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-movefromlocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-movetolocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] [-t <thread count>] [-q <thread pool queue size>] <localsrc> ... <dst>]
[-renamesnapshot <snapshotdir> <oldname> <newname>]
[-rm [-f] [-r|-r] [-skiptrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-r] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-r] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignorecrc] <src> ...]
[-touch [-a] [-m] [-t timestamp (yyyymmdd:hhmmss) ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
generic options supported are:
-conf <configuration file> specify an application configuration file
-d <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem url to use, overrides 'fs.defaultfs' property from configurations.
-jt <local|resourcemanager:port> specify a resourcemanager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
the general command line syntax is:
command [genericoptions] [commandoptions]
注意: 与linux中使用方法基本相同的指令我们不过多讲解
例如:ls mkdir touch.....
ls指令查看hdfs中的文件目录信息
hdfs dfs -ls 路径 路径要从根路径指定 hadoop fs -ls 路径
hdfs的文件目录操作
hdfs dfs -mkdir /路径 hdfs dfs -touch /路径/文件 hdfs dfs -mv 原始路径 目标路径 hdfs dfs -cp 原始路径 目标路径 hdfs dfs -rm -r /路径
文件的上传和下载
put指令: 从linux 服务器本地上传到hdfs文件系统中
hdfs dfs -put /var/log/messages /
get命令: 从hdfs文件系统将文件下载到linux文件系统中
hdfs dfs -get /sparklog/local-1664869425770.lz4 /root
注意: 在hdfs中使用任何文件或目录,要使用绝对路径进行查找,在hdfs中 没有工作目录的概念,更没有相对路径的概念.

发表评论