纠删码和异构存储测试需要5台虚拟机。准备另外一套5台服务器集群。
环境准备:
(1)克隆hadoop105为hadoop106,修改ip地址和hostname,然后重启。
vim /etc/sysconfig/network-scripts/ifcfg-ens33
vim /etc/hostname
reboot
(2)关闭集群,删除所有服务器hadoop的data和logs文件。
rm -rf data/ logs/
(3)在hadoop102上修改xsync和jpsall文件,把hadoop105和hadoop106加上。
xsync存储地址:/bin,在root下修改,然后后分发xsync:xsync xsync
jpsall、myhadoop.sh 、xsync存储地址:/home/liaoyanxia/bin,修改后退出到liaoyanxia目录然后分发:xsync bin/
(4)在hadoop102上修改blacklist、whitelist、hdfs-site.xml、workers。
删除blacklist里的内容;在workers和whitelist加上所有的主机(即hadoop102-106);修改hdfs-site.xml的多目录:namenode只留一个节点name、datanode只留一个节点data:
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
(5)退出到hadoop-3.3.1/etc目录,分发hadoop,然后启动集群。
xsync hadoop/
myhadoop-sh start
jpsall查看进程,集群启动没问题。
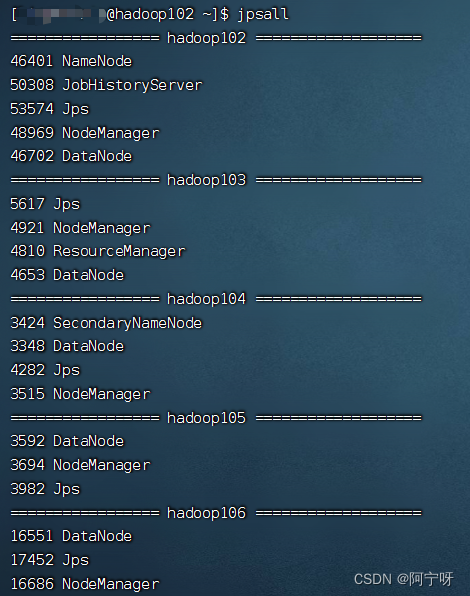
(6)关闭集群和所有服务器,把5个主机依次克隆。
1 纠删码
1.1 原理
hdfs默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余存储开销。
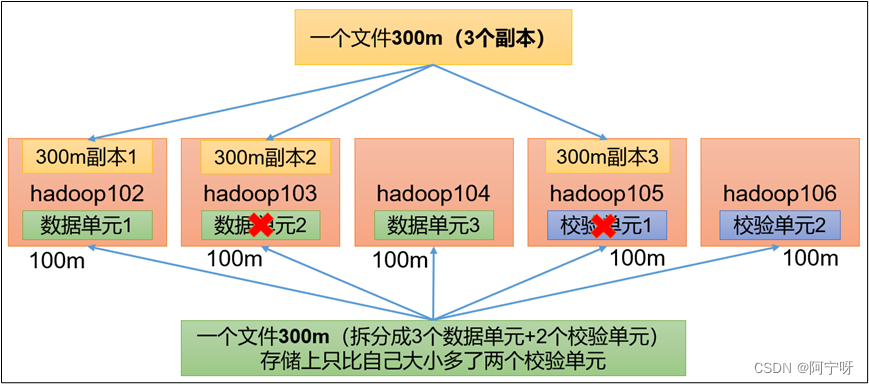
hadoop3.x引入了纠删码(假如如上图一个文件拆分为3个数据单元和2个校验单元),任意两个节点挂掉都可以采用计算的方式恢复(所以占用了计算资源即占用cpu时间,以cpu换存储空间),可以节省约50%左右的存储空间。
纠删码相关命令:
hdfs ec
[-listpolicies] 查看当前支持的纠删策略
[-addpolicies -policyfile<file>]
[-getpolicy -path <path>] 针对某个路径的获得其策略
[-removepolicy -policy<policy>] 删除策略
[-setpolicy -path <path> [-policy <policy>][-replicate]] 针对某个路径的设置其策略
[-unsetpolicy -path <path>]
[-listcodecs]
[-enablepolicy -policy <policy>] 开启纠删策略
[-disablepolicy -policy <policy>] 关闭纠删策略
[-help <command-name>].
纠删码策略解释:
rs-a-b-1024k:使用rs编码,每a个数据单元(cell),生成b个校验单元,共a+b个单元,也就是说:这a+b个单元中,只要有任意的a个单元存在(不管是数据单元还是校验单元,只要总数=a),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576,即拆分时先按1m进行拆分。
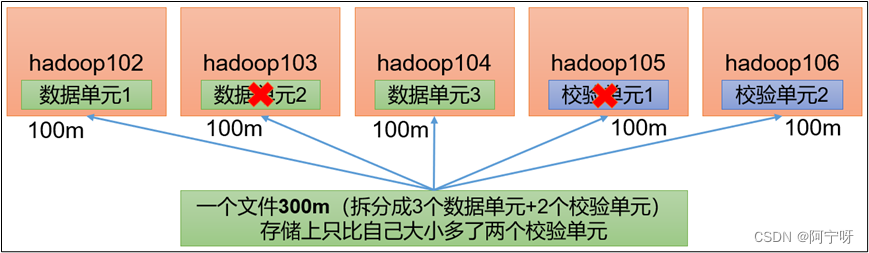
如rs-3-2-1024k:使用rs编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=10241024=1048576,即拆分时先按1m进行拆分,对上图来说,再将100个1m的数据放在一起。
rs-legacy-6-3-1024k:策略和rs-6-3-1024k一样,只是编码的算法用的是rs-legacy。
xor-2-1-1024k:使用xor编码(速度比rs编码快)。
1.2 案例
纠删码策略针对具体路径设置,所有在此路径下存储的文件都会执行此策略。
把/input目录设置为rs-3-2-1024k策略。
(1)开启rs-3-2-1024k策略:
hdfs ec -enablepolicy -policy rs-3-2-1204k
(2)在hdfs创建目录并设置rs-3-2-1204k策略:
hdfs dfs -mkdir /input
hdfs ec -setpolicy -path /input -policy rs-3-2-1024k
(3)在该目录下上传大于2m的文件,在hdfs上可以看到replication(副本)只有1份,因为数据分成了3份数据单元放在不同的节点,另外两个节点存放校验单元。
hdfs dfs -put web.log /input
(4)查看存储路径的数据单元和校验单元,并作破坏实验
查看data/dfs/current/…用cat 看数据,看哪些节点是数据单元和校验单元。
删除两个节点的以上数据(快速删除)可以在hdfs文件系统里下载,且观察到删除的数据有恢复。
2 异构存储(冷热数据分离)
经常使用和存储的数据为热数据,否则为冷数据。
异构存储主要解决:不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
存储类型:
ram_disk:内存
ssd:固态硬盘
disk:机械硬盘,即普通磁盘
archive:归档,不指定某种存储介质,主要指计算能力较弱但存储密度高的介质。
存储策略:

2.1 异构存储shell操作
(1)查看当前有哪些存储策略可以用
hdfslistpolicies storagepolicies -listpolicies
(2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setstoragepolicy -path 路径 -policy 存储策略
(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getstoragepolicy -path 路径
(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是hot
hdfs storagepolicies -unsetstoragepolicy-path 路径
(5)查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations
(6)查看集群节点
hadoop dfsadmin -report
2.2 测试环境准备
服务器5台,副本数为2,提前创建带有 存储类型的目录。
集群规划:

配置文件:
hadoop102的hdfs-site.xml添加:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ssd]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[ram_disk]file:///opt/module/hadoop-3.1.3/hdfsdata/ram_disk</value>
</property>
hadoop103的hdfs-site.xml添加:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ssd]file:///opt/module/hadoop-3.1.3/hdfsdata/ssd,[disk]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
hadoop104的hdfs-site.xml添加:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ram_disk]file:///opt/module/hdfsdata/ram_disk,[disk]file:///opt/module/hadoop-3.1.3/hdfsdata/disk</value>
</property>
hadoop105的hdfs-site.xml添加:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[archive]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value>
</property>
hadoop106的hdfs-site.xml添加:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[archive]file:///opt/module/hadoop-3.1.3/hdfsdata/archive</value></property>
重新格式化namenode,启动集群
hdfs namenode -format
myhadoop.sh start
在hdfs创建目录并上传资料
hadoop fs -mkdir /hdfsdata
hadoop fs -put /opt/module/hadoop-3.3.1/notice.txt /hdfsdata
2.3 hot存储策略案例
刚开始没有设置存储策略,先获取目录存储策略:
hdfs storagepolicies -getstoragepolicy -path /hdfsdata
查看上传的文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

可以看到没有设置存储策略的情况下所有的文件块都存储在disk下,即默认存储处理为host。
2.4 warm存储策略测试
先给数据降温:
hdfs storagepolicies -setstoragepolicy -path /hdfsdata -policy warm
查看上传的文件块分布,还是在原处
hdfs fsck /hdfsdata -files -blocks -locations

让hdfs按照存储策略自行移动文件块(不会自动改变存储策略,需要手动移动):
hdfs mover /hdfsdata
再查看文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations
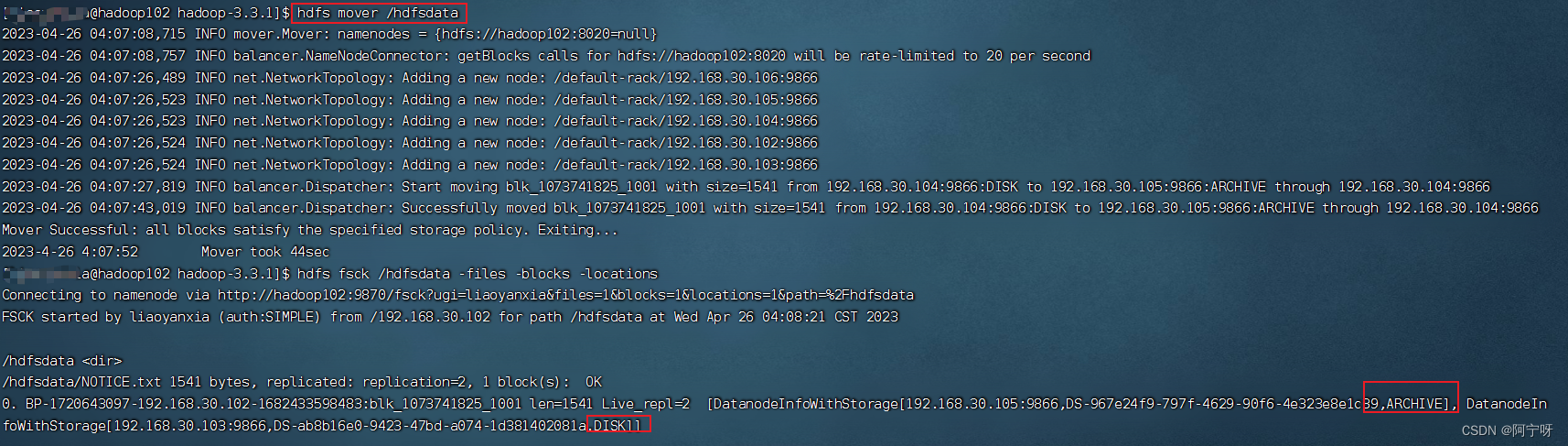
文件块一半在disk,一半在archive,符合设置的warm策略。
2.5 cold策略测试
数据降温为cold:
hdfs storagepolicies -setstoragepolicy -path /hdfsdata -policy cold
在上传文件到cold策略的目录前需要配置archive存储目录,不然会报异常。
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

所有文件都在archive,符合cold存储策略。
2.6 one_ssd策略测试
存储策略改为one_ssd:
hdfs storagepolicies -setstoragepolicy -path /hdfsdata -policy one_ssd
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

文件块分布一半在ssd,一半在disk,符合one_ssd存储策略。
2.7 all_ssd策略测试
存储策略改为all_ssd:
hdfs storagepolicies -setstoragepolicy -path /hdfsdata -policy all_ssd
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

文件块全部存储在ssd,符合all_ssd存储策略。
2.8 lazy_persist策略测试
存储策略改为lazy_persist:
hdfs storagepolicies -setstoragepolicy -path /hdfsdata -policy lazy_persist
手动移动:
hdfs mover /hdfsdata
检查文件块分布:
hdfs fsck /hdfsdata -files -blocks -locations

理论上结果为一个副本存储在ram_disk,其它都存储在disk,但最终发现所有的文件块都存储在disk。
原因:
(1)当客户端所在的datanode节点没有ram_disk时,则会写入客户端所在的datanode节点的disk磁盘,其余副本会写入其他节点的disk磁盘。
(2)当客户端所在的datanode有ram_disk,但“dfs.datanode.max.locked.memory”参数值未设置或者设置过小(小于“dfs.block.size”参数值)时,会写入客户端所在的datanode节点的disk磁盘,其余副本会写入其他节点的disk磁盘。
解决:
配置“dfs.datanode.max.locked.memory”,“dfs.block.size”参数。但是由于虚拟机的“max locked memory”为64kb,所以,如果参数配置过大,还会报错。


发表评论