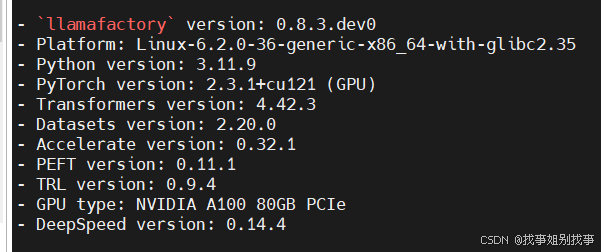
一、安装 llama factory
当我们安装好环境后,可以看一下我们的llama-factory的版本,命令: llamafactory-cli env
二、llama board
他是一个可视化的web页面,可以手动去配置参数,可进行推理,微调,非常的方便,由gradio驱动。
启动命令:
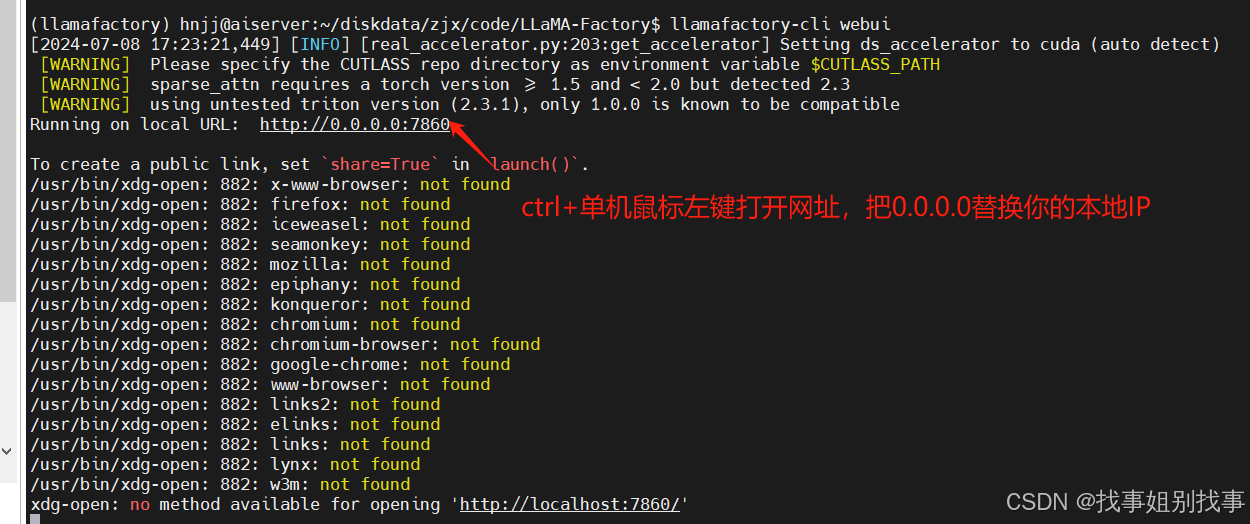
打开链接后的页面展示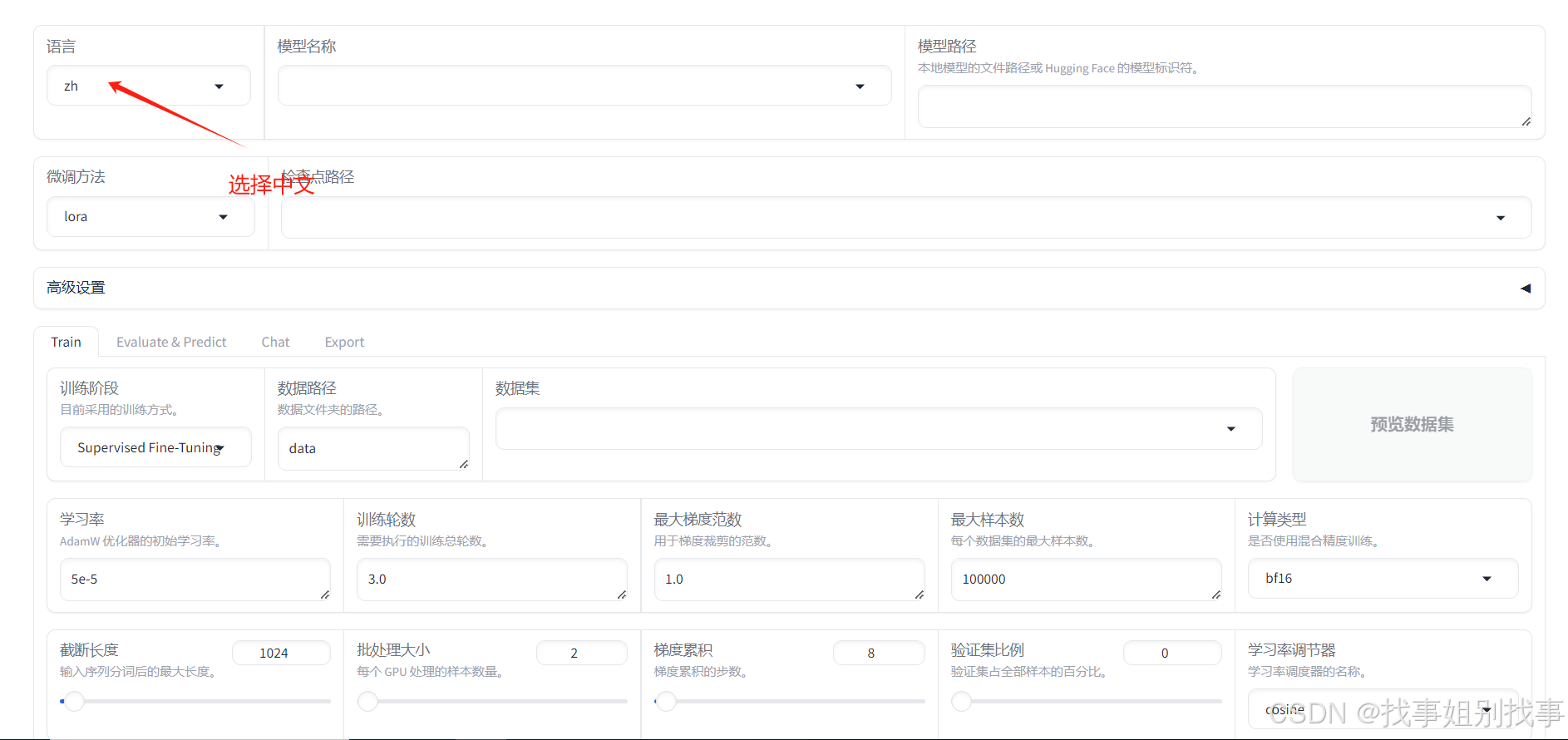
每个参数的作用这里我就不具体解释了,网上一搜一大把,如果是新手,我建议去bilibili搜一个llama board参数讲解视频细心看完!!!
2.1 inference
下面我们来做一个简单的推理测试,我本次的测试模型是qwen2-7b-instruct
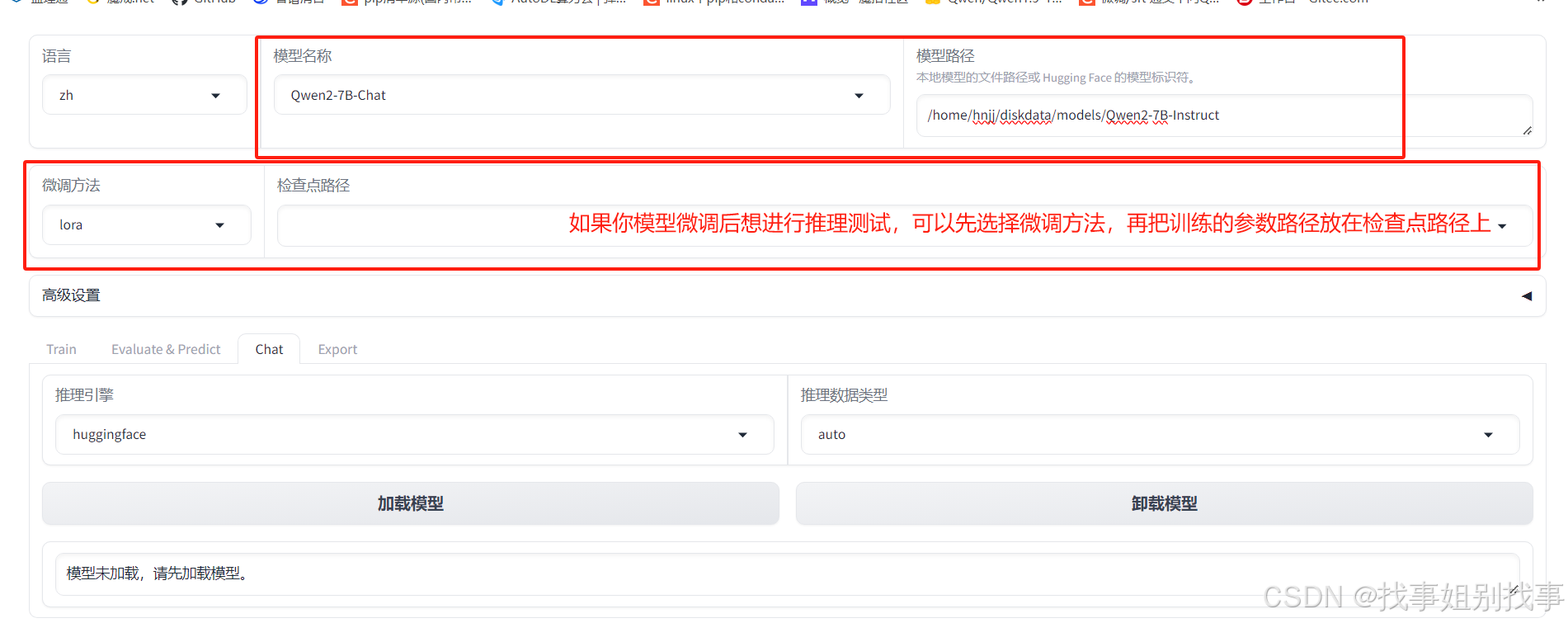
1.第一步先点击chat
2.第二部选择你的模型名称
3.粘贴模型路径
2.2 train
首先选择模型和数据还有微调方式
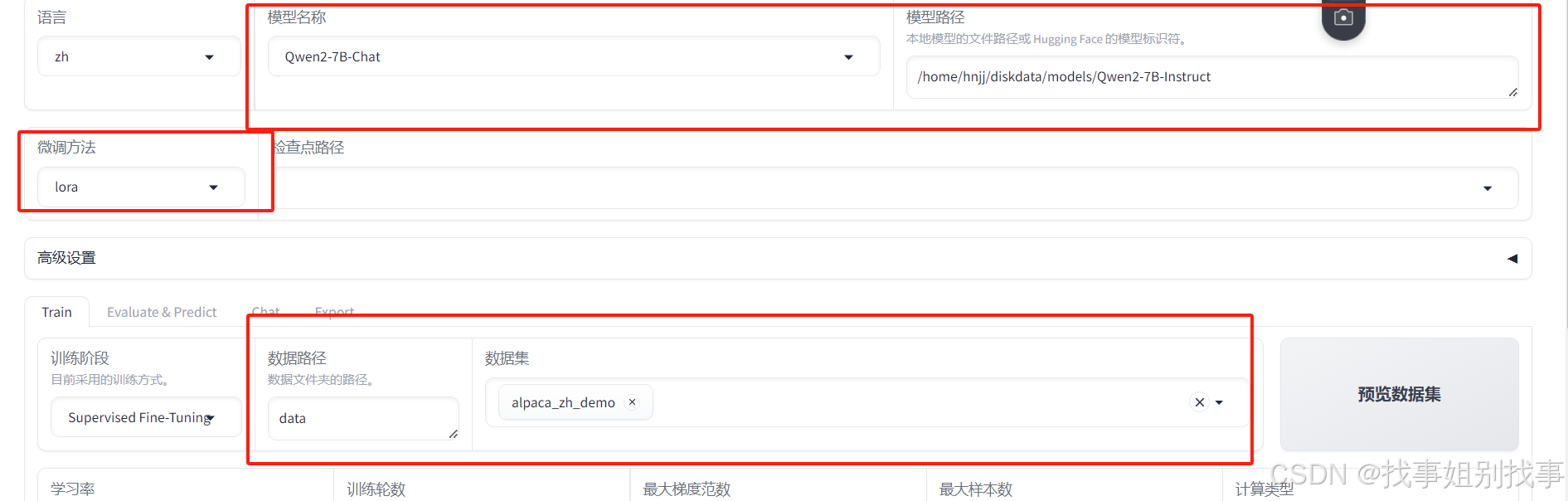
然后选择保存模型的位置
注:如果你的模型比较大,一台显卡无法加载你的模型,你可以选择使用deepspeed单机多卡,deepspeed stage选择zero3,如果你一张显卡能够微调,但你有多张显卡的话,这里建议你使用zero2,可以提高接近两倍的训练速度,也就是节省一半的时间
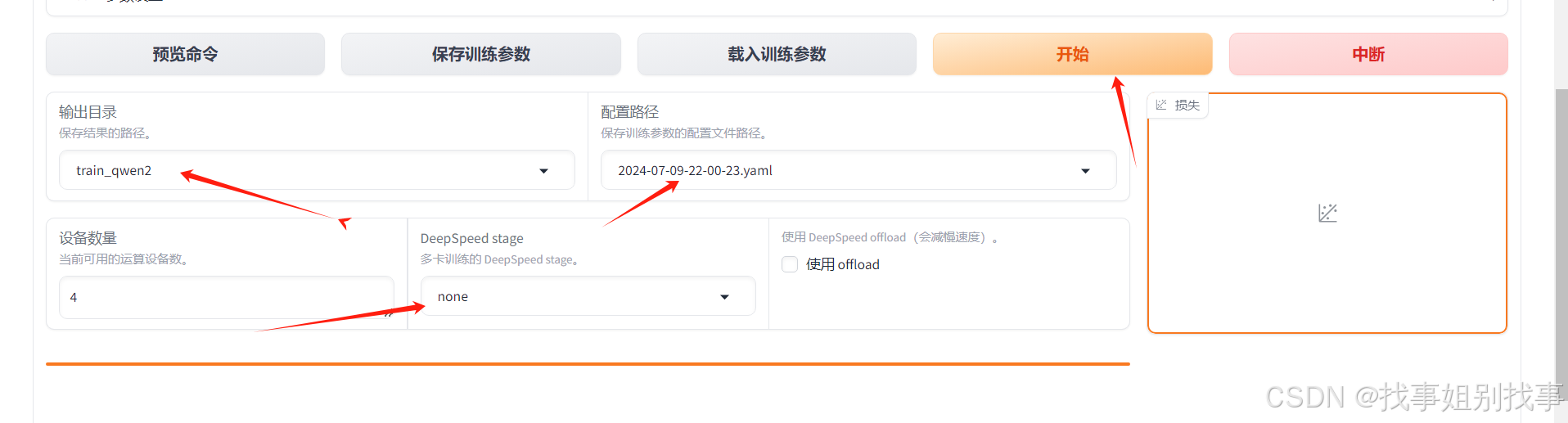
可以看到后台正在训练
前端也可以看到loss在下降,说明模型在正常训练
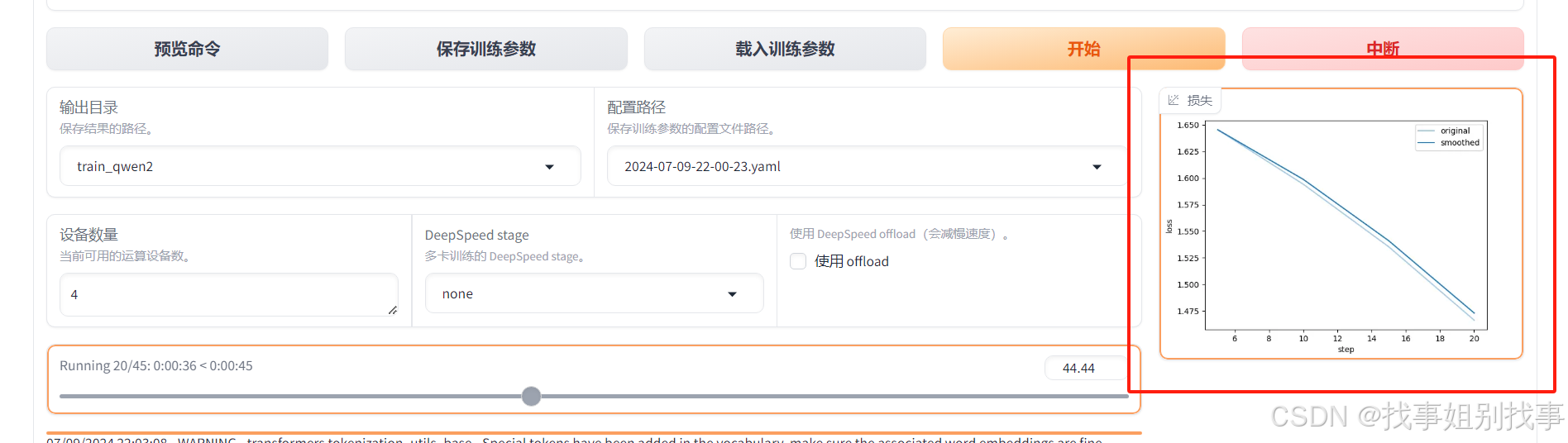
2.3 train_xinference
当我们训练好模型后,我们可以先测试一下模型的后坏,如果认为模型没问题的话我们再合并模型。
这是我们微调后模型的参数的保存位置
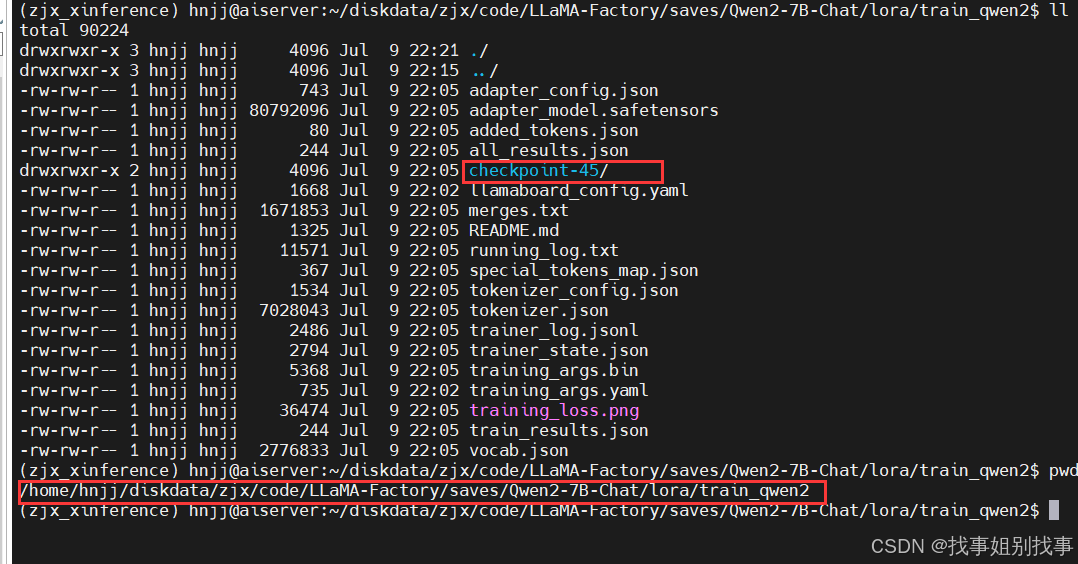
我们进入checkpoint-45,然后复制模型路径,粘贴到检查点路径位置上,然后点击加载模型
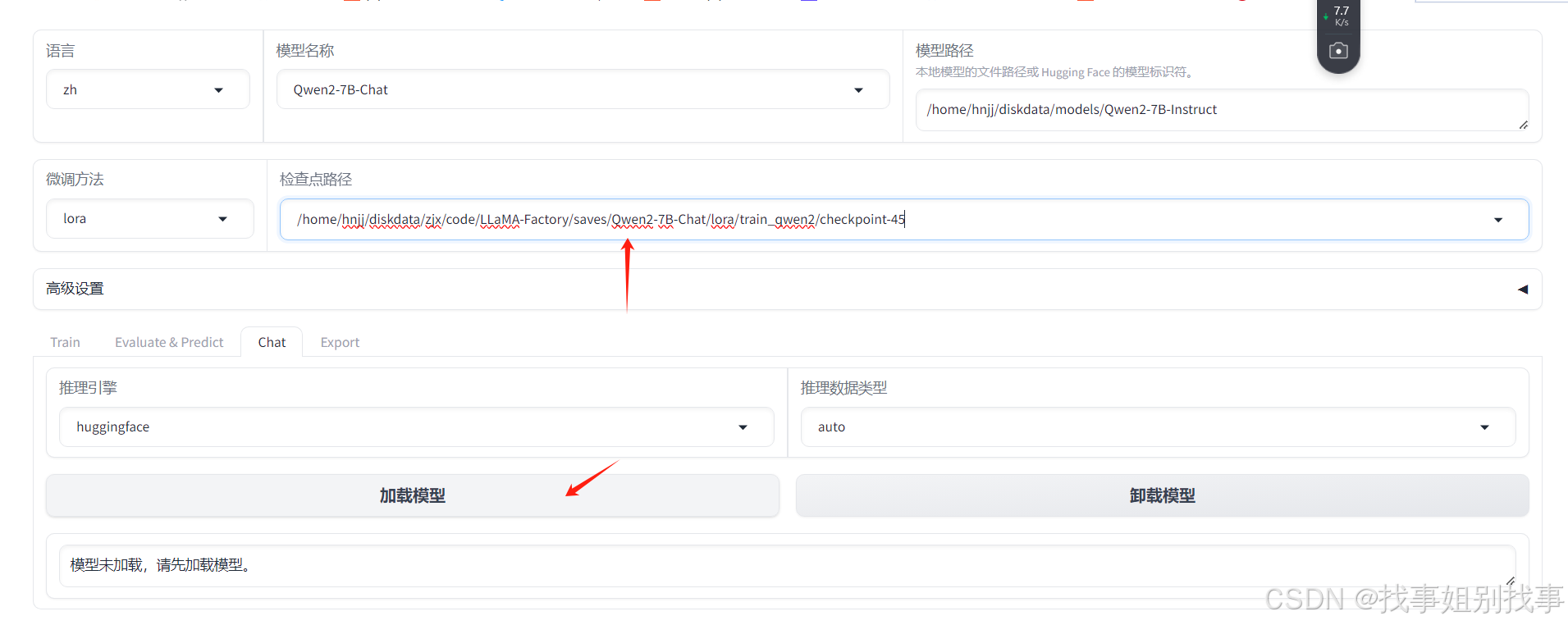
2.4 merge_model
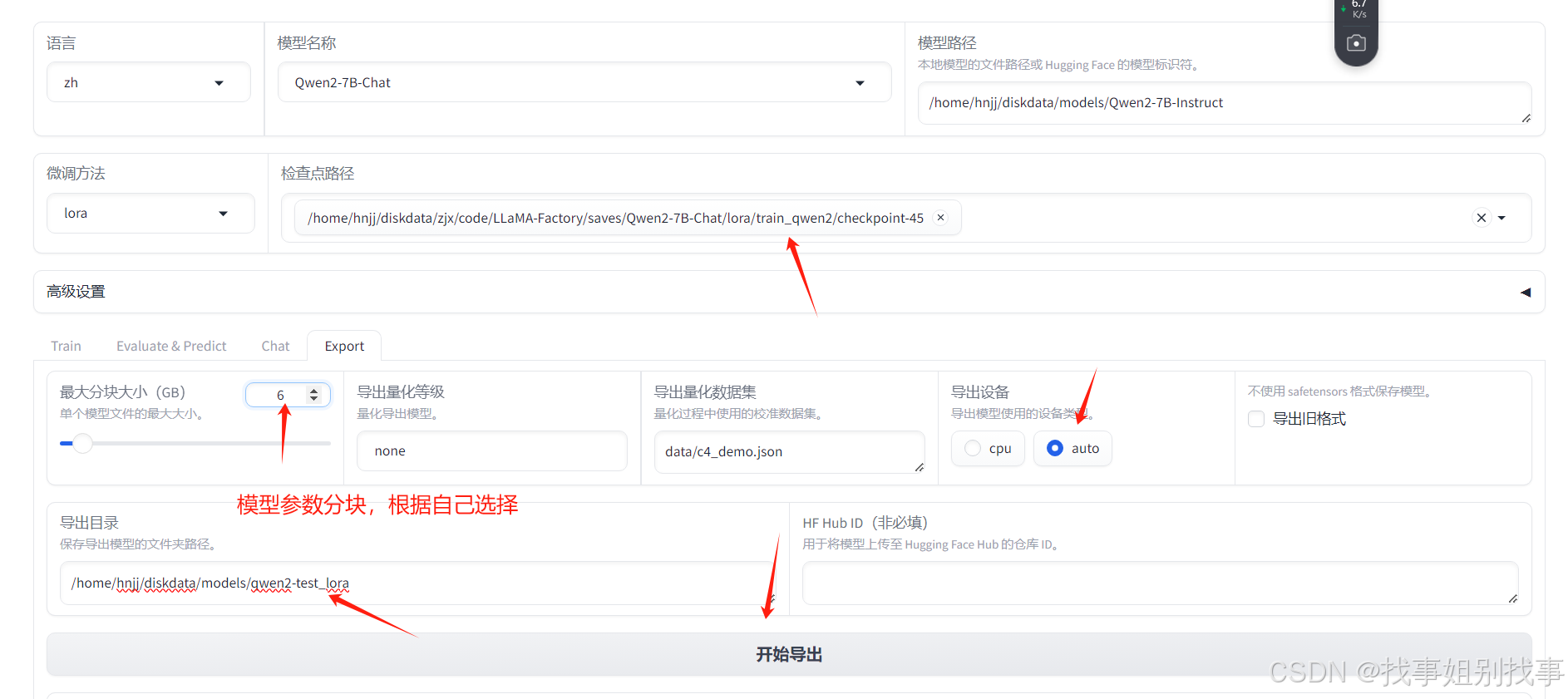
我们只需要配置下面箭头指向的几个位置就可以了
注:模型分块不要太大,太大的话会按默认参数,不会按你设置的参数去分块
三、命令形式
3.1 inference
3.1.1 cli-inference
我还是那qwen2举例子,下图是我的参数配置

然后运行推理命令
注:主要执行命令时自己的所在路径!!!!!!![]()

3.1.2 webchat-inference
现在我们来演示一下web推理加载方式
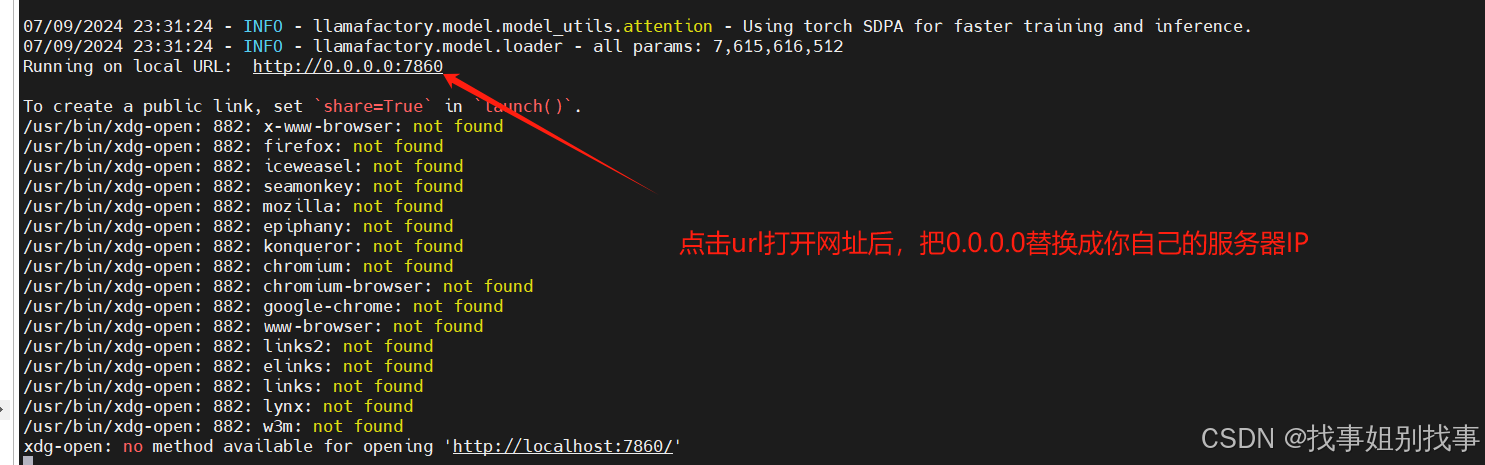
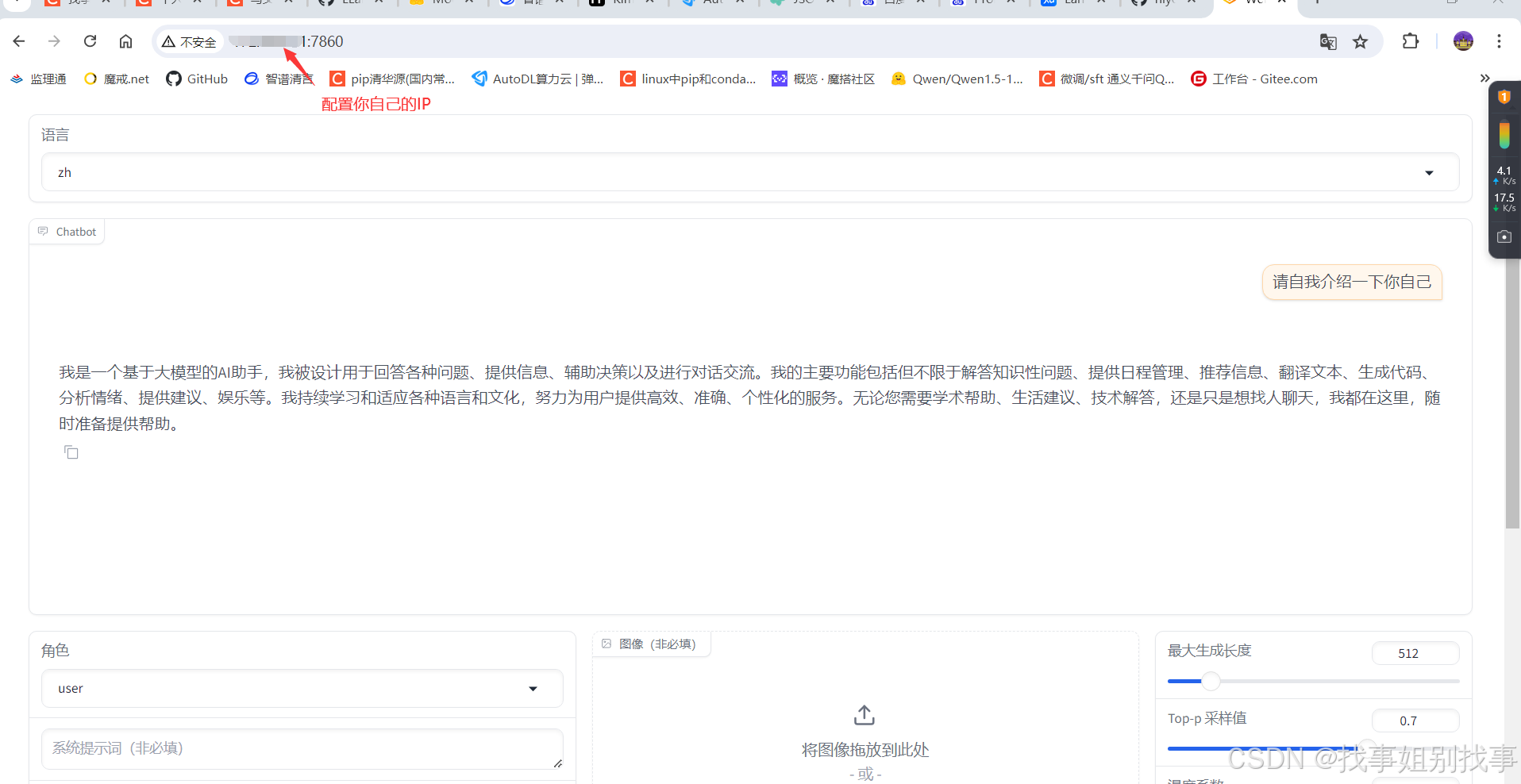
3.2 train
3.2.1 single_train
如果你只要一台显卡,那么就使用单卡训练
首先进入路径,修改单卡训练的文件配置
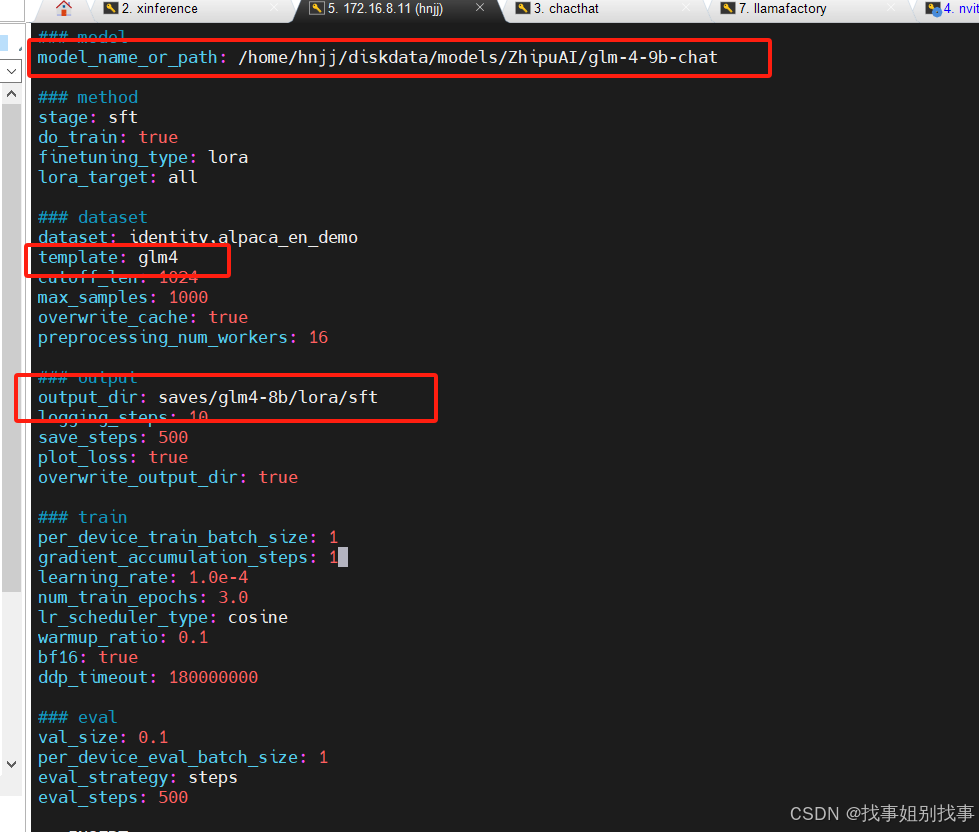
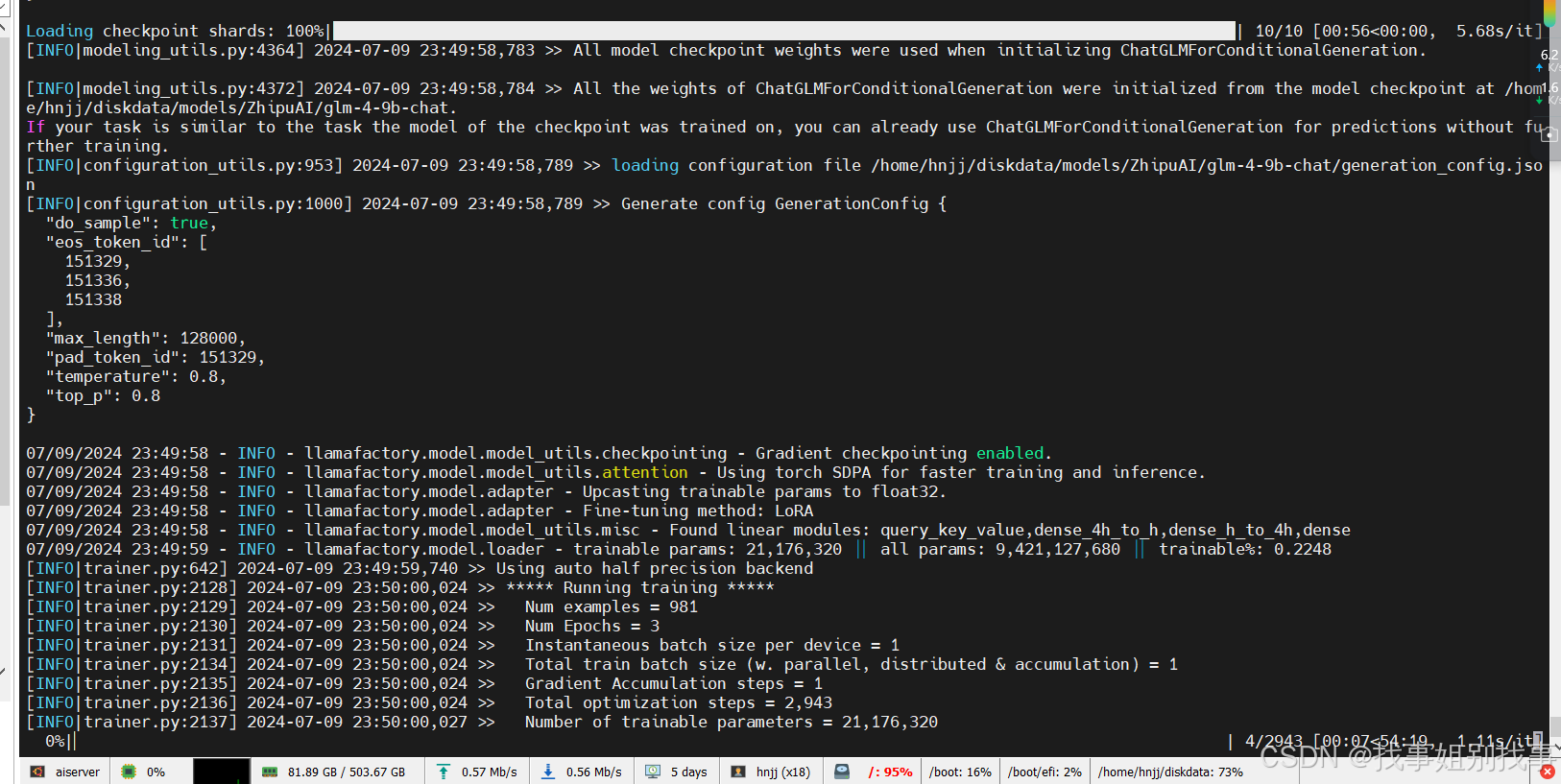
下面就开始训练了!
3.2.2 multi_train
如果你的模型参数比较大,一张卡无法加载你的模型参数,那么你就需要使用单机多卡来训练模型,你可选择deepspeed的zero3,如果你的一张显卡能够加载模型参数,你又有多张卡,可以选择zero2,使数据并行,这样可以大大减少训练时间。
加入我现在使用的是qwen2-72b-instruct模型,一张卡无法加载模型参数,这个时候我们必须使用deepspeed的zero3,我们就新建一个yaml文件,参考llama3_lora_sft_ds3.yaml文件内容。
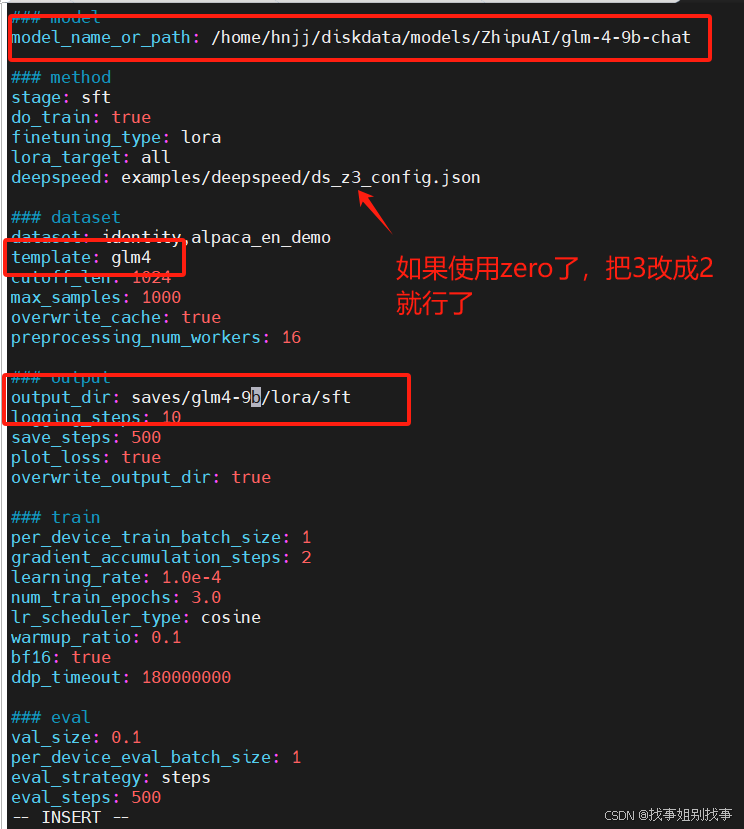
模型开始训练了!
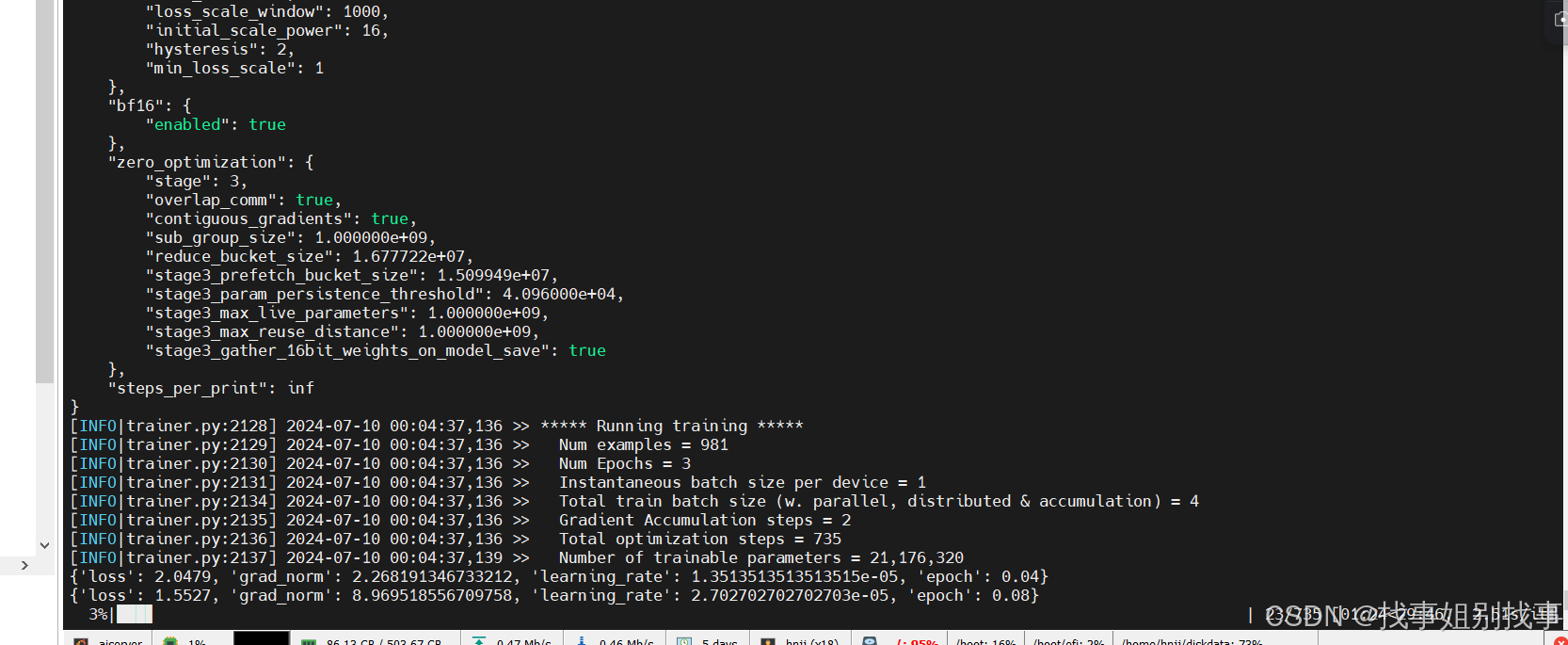
3.3 train_inference
当我们训练好模型参数后,可以先验证一下训练参数的好坏再进行模型合并
进入~/llama-factory/examples/inference路径下,新建一个yaml文件,参照llama3_lora_sft.yaml修改文件配置

单机url,改成自己的ip就可以打开web页面进行模型测试了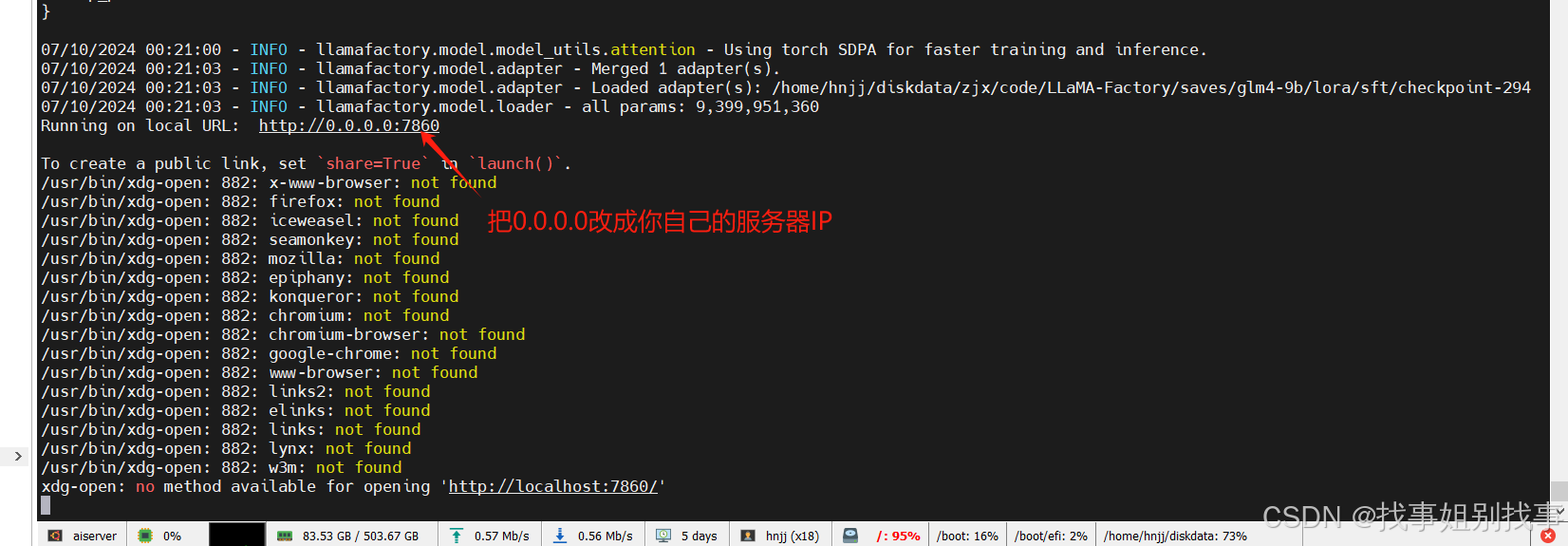
3.4 merge_model
进入~/llama-factory/examples/merge_lora目录下,参考llama3_lora_sft.yaml文件创建并修改glm4_lora_sft.yaml文件参数,如下图
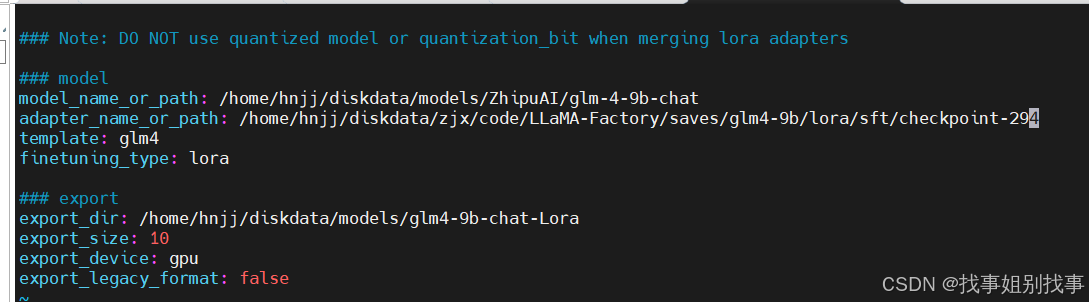
然后运行合并模型的命令就可以了!!!
3.5 api_model
如果想封装model,然后使用模型的接口,可以使用启动 openai 风格的api
四、数据格式修改
我们拿两种格式举例,首先我们需要找到dataset_info.json文件的位置,进入~/llama-factory/data,目录下有个dataset_info.json,我们需要修改他的参数文件。
4.1 alpaca 格式
如果你的文件是如下图格式
就按官方的例子修改
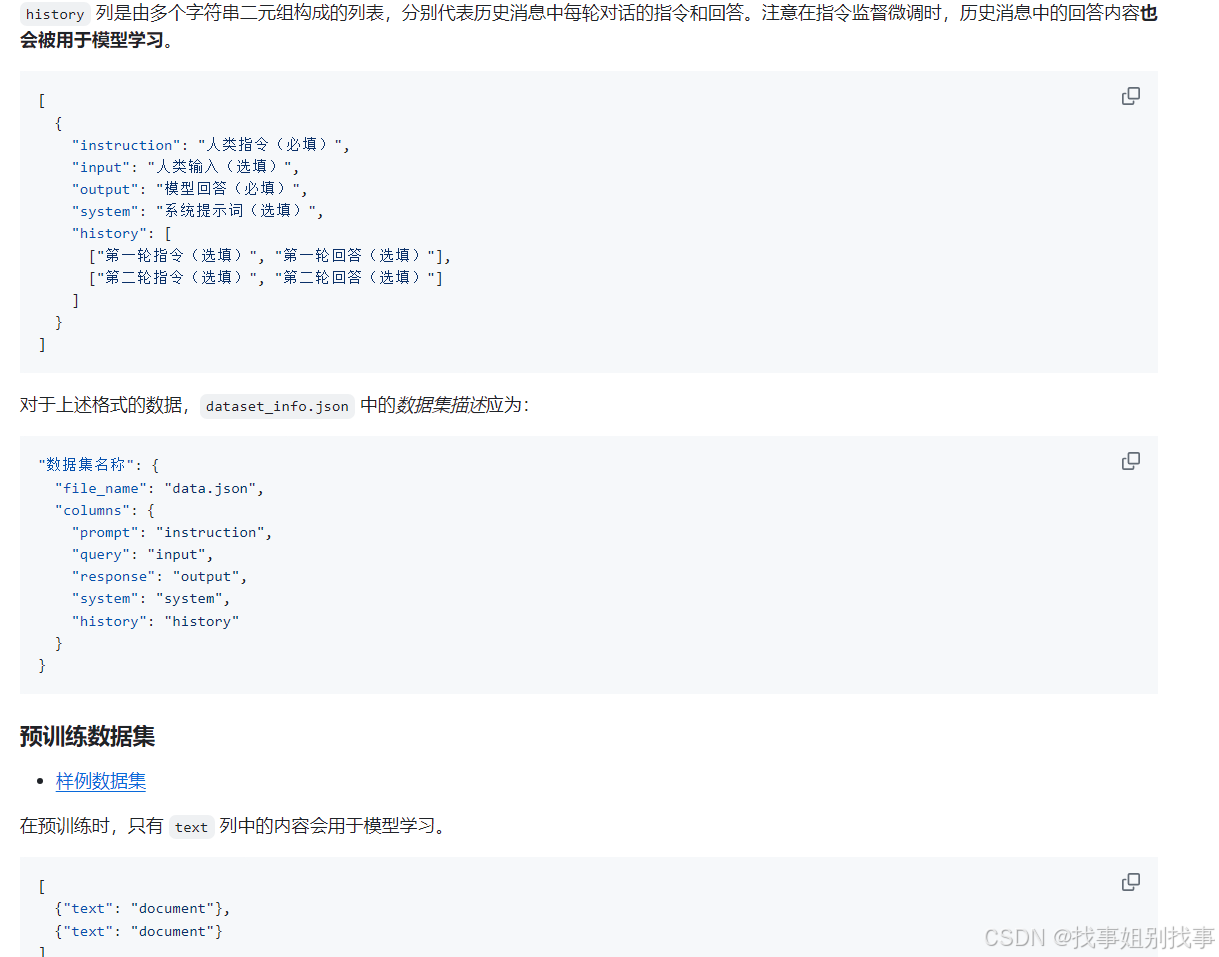
例子如下: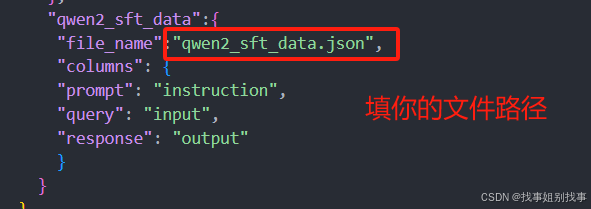
4.2 sharegpt 格式
如果你的文件格式如下:
官方的说明如下:
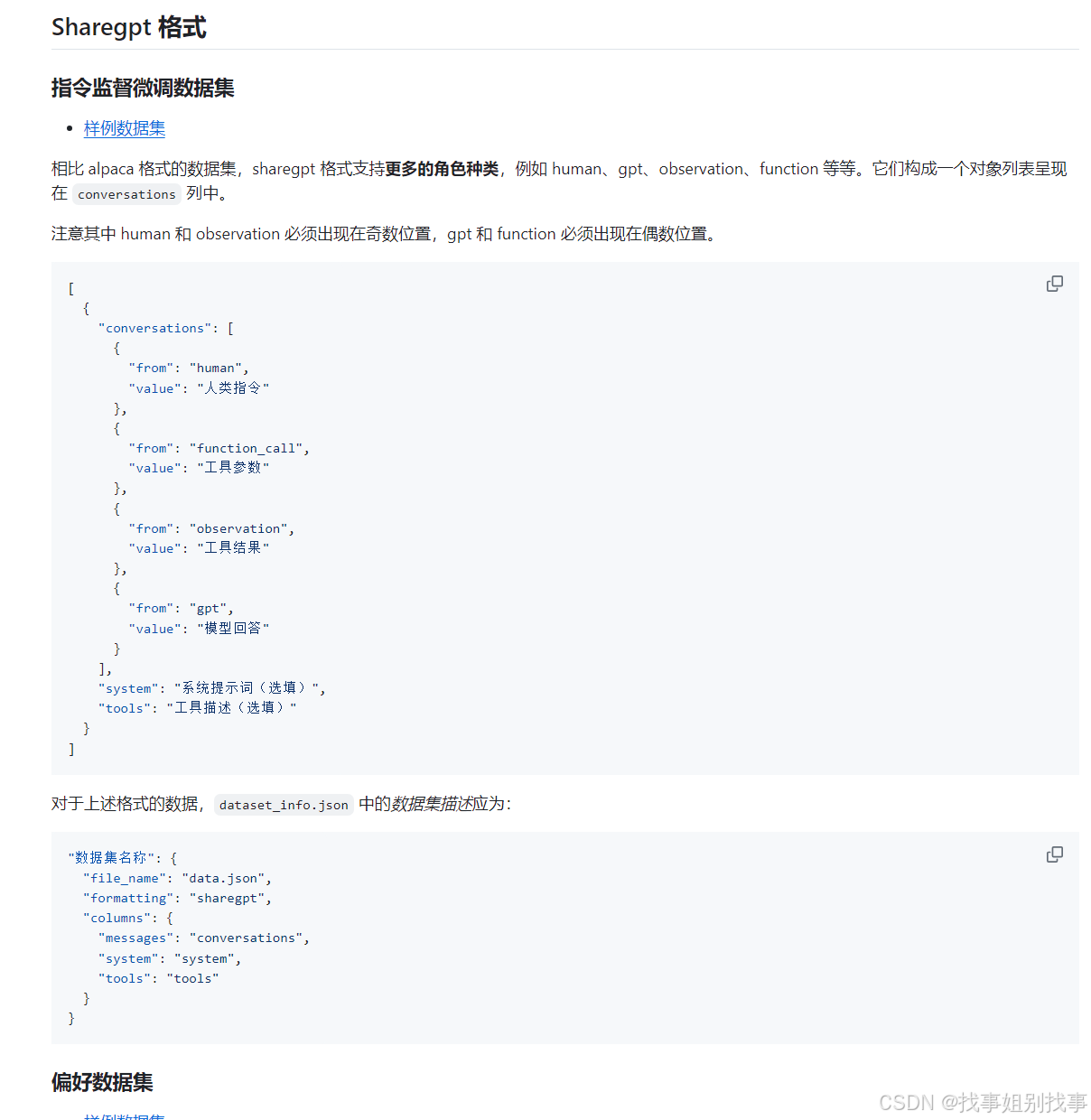
示例: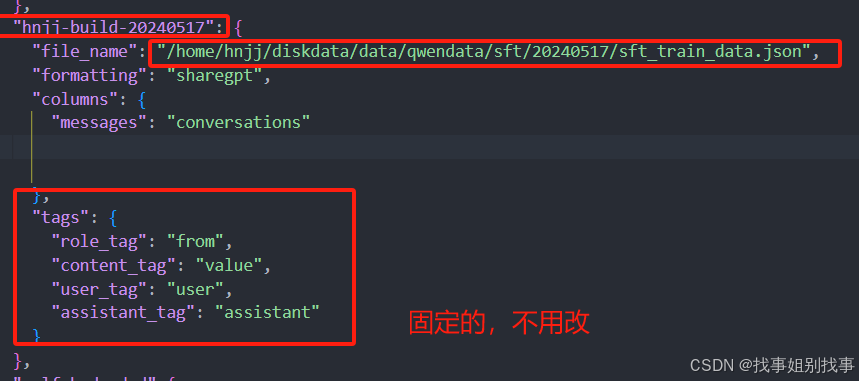
只需要修改文件名字和文件路径就可以了!
完结!!!
如果后期有什么疑问,欢迎大家评论区留言



发表评论