[at the heart of pytorch data loading utility is the torch.utils.data.dataloader class.]
目录
准备:
1.pytorch官网链接pytorch
2.训练采用数据集准备
这里推荐用:cifar10(数据集)
执行下面代码,就可以下载了:download 设置为true
import torchvision
train_data = torchvision.datasets.cifar10(root="./dataset",
transform=torchvision.transforms.totensor(),
train=true,
download =true)
test_data = torchvision.datasets.cifar10(root="./dataset",
transform=torchvision.transforms.totensor(),
train=false,
download =true)可以得到训练集train_data和测试集test_data。
3.关于dataloader的预备知识
torch.utils.data — pytorch 2.2 documentation
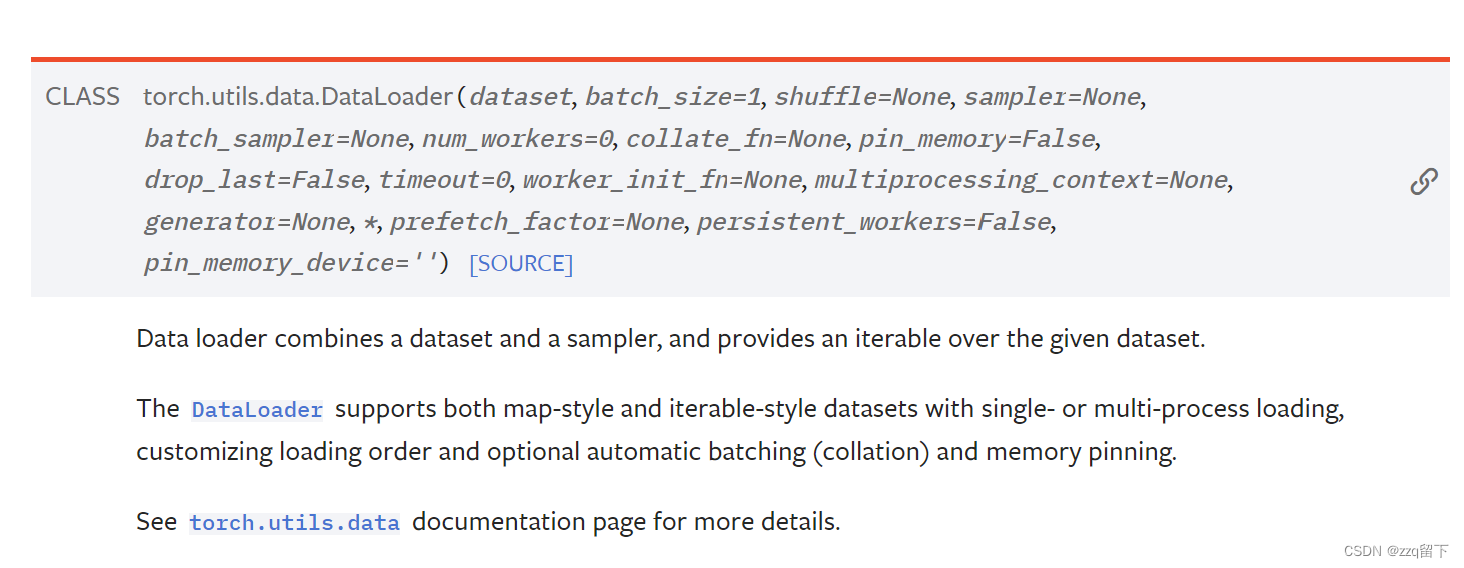
这是整个类,但今天我们重点讲的是函数dataloader

these options are configured by the constructor arguments of a dataloader
就是说功能可以由dataloader实现,又展示了这些参数。
截图自官网
启动
dataset
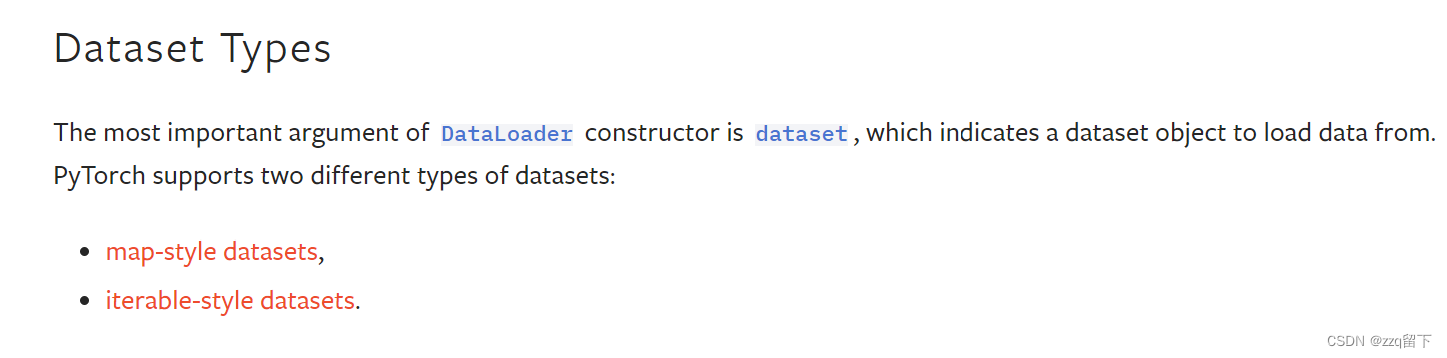
indicates a dataset object to load data from 即数据来源。

列举了一些(which has a default function)有默认值的。参考准备标题下的图片,可以发现真正要填的只有dataset即数据来源。根据文章开头下载的数据集,把test_data或train_data 填进去就行了。
batch_size

batch_size 这个参数控制的是一个步骤有多少图片,默认值是1,即每个步骤一张图片。
那我们再在tensorboard上面呈现一下。这里我就不填了,就是默认值1(代码直接放了,tensorboard之前讲过深度学习:pytorch 图片呈现 tensorboard (add_image)控制台自学调试检验,含终极代码-csdn博客
import torchvision
from torch.utils.tensorboard import summarywriter
from torch.utils.data import dataloader
trans_to = torchvision.transforms.totensor()
train_set = torchvision.datasets.cifar10(root="./dataset",transform= trans_to,train=true,download = false)
test_set = torchvision.datasets.cifar10(root = "./dataset",transform= trans_to,train =false ,download =false)
test_loader =dataloader(dataset=test_set)
writer = summarywriter('fff')
step = 0
for data in test_loader:
imgs,targets =data
writer.add_images("batch_size=1",imgs,step)
step = step +1
writer.close()
(刚刚下载过了,我这里download就设置成false了,但你“./dataset”这个路径刚刚写的是什么这里就写什么不然识别不出来的)
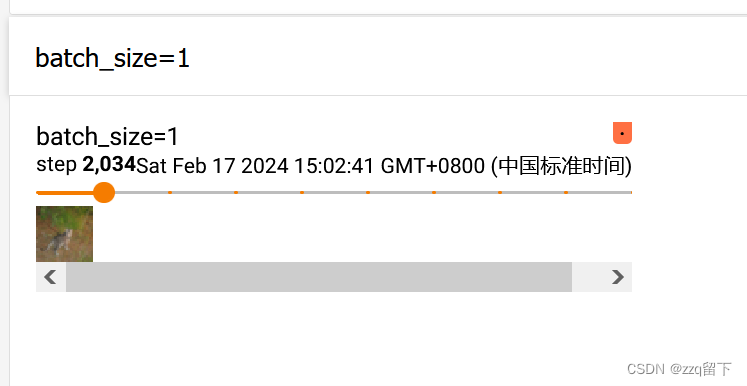
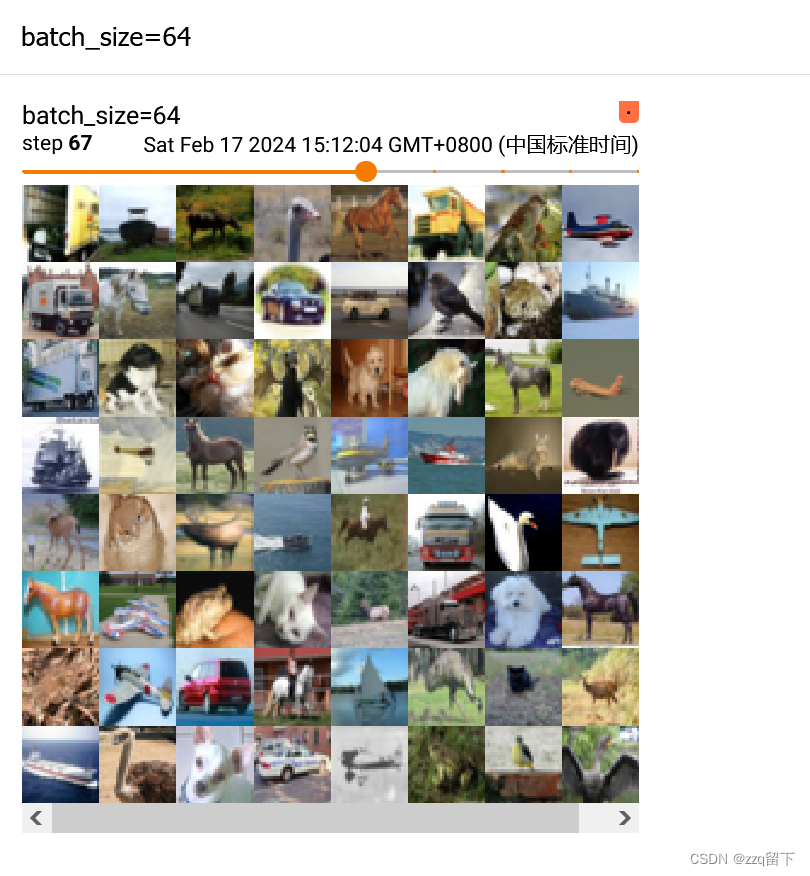
board上就呈现出这个了。那我们试试看batch_size=64
test_loader =dataloader(dataset=test_set,batch_size=64)然后把名称也改一下,改成batch_size=64 直观一点。
shuffle

默认有序,true的话要reshuffle(重新排序)
drop_last

默认是最后一步展现的图片会少一些 。就是整个数据的个数可以不可以被你设置的batch_size整除,如果不可以,最后一步展示的必然与你设置的batch_size不同,而drop_last就是决定要不要展示剩余的图片,如果true则不展示,false则展示。
前面都是默认展示的,看看
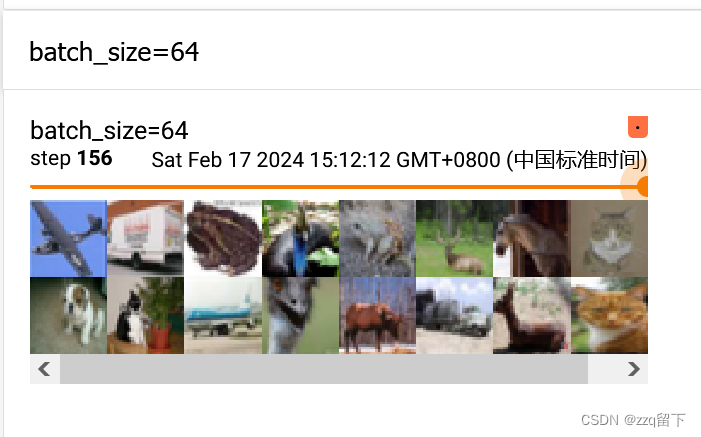
这是刚刚的设置为64的,显然,我把其拖到最后一步,这一步里的数据一定没有64张,也确实没有。 然后可以看到总共有156步。
那我改一下设置,设置其为true
test_loader =dataloader(dataset=test_set,batch_size=64,shuffle=true,drop_last=true)
最后一页还是有64张,但只有155步了。说明剩余的被删掉了。
那个
其他的,有兴趣试试 。




发表评论