论文地址:https://arxiv.org/pdf/2405.04434
一、简介
- deepseek-v2是一个总参数为236b的moe模型,每个token仅激活21b的参数,并支持128k的上下文长度。
- 提出了multi-head latent attention(mla),通过压缩kv cache至隐向量,从而保证高效推理。
- 相比于deepseek 67b,deepseek-v2实现了更好的表现,节约了42.5%的训练成本,降低了93.3%的kv cache,提升最大吞吐5.76倍。
- 预训练语料包含了8.1t tokens并进一步进行sft和rl。
二、模型结构
1. mla(multi-head latent attention)
传统transformer采用mha(multi-head attention),但是kv cache会成为推理瓶颈。mqa(multi-query attention)和gqa(grouped-query attention)可以一定程度减少kv cache,但效果上不如mha。deepseek-v2设计了一种称为mla(multi-head latent attention)的注意力机制。mla通过低秩key-value联合压缩,实现了比mha更好的效果并且需要的kv cache要小很多。
1.1 标准mha
令
d
d
d为embedding维度,
n
h
n_h
nh是注意力头的数量,
d
h
d_h
dh是每个头的维度,
h
t
∈
r
d
\textbf{h}_t\in\mathbb{r}^d
ht∈rd是注意力层中第
t
t
t个token的输入。标准mha通过三个矩阵
w
q
,
w
k
,
w
v
∈
r
d
h
n
h
×
d
w^q,w^k,w^v\in\mathbb{r}^{d_h n_h\times d}
wq,wk,wv∈rdhnh×d来产生
q
t
,
k
t
,
v
t
∈
r
d
h
n
h
\textbf{q}_t,\textbf{k}_t,\textbf{v}_t\in\mathbb{r}^{d_h n_h}
qt,kt,vt∈rdhnh。
q
t
=
w
q
h
t
k
t
=
w
k
h
t
v
t
=
w
v
h
t
\begin{align} \textbf{q}_t&=w^q\textbf{h}_t \tag{1}\\ \textbf{k}_t&=w^k\textbf{h}_t \tag{2}\\ \textbf{v}_t&=w^v\textbf{h}_t \tag{3}\\ \end{align} \\
qtktvt=wqht=wkht=wvht(1)(2)(3)
在mha中
q
t
,
k
t
,
v
t
\textbf{q}_t,\textbf{k}_t,\textbf{v}_t
qt,kt,vt会被划分为
n
h
n_h
nh个头:
[
q
t
,
1
;
q
t
,
2
;
…
,
q
t
,
n
h
]
=
q
t
[
k
t
,
1
;
k
t
,
2
;
…
,
k
t
,
n
h
]
=
k
t
[
v
t
,
1
;
v
t
,
2
;
…
,
v
t
,
n
h
]
=
v
t
o
t
,
i
=
∑
j
=
1
t
softmax
(
q
t
,
i
⊤
k
j
,
i
d
h
)
v
j
,
i
u
t
=
w
o
[
o
t
,
1
;
o
t
,
2
;
…
,
o
t
,
n
h
]
\begin{align} &[\textbf{q}_{t,1};\textbf{q}_{t,2};\dots,\textbf{q}_{t,n_h}]=\textbf{q}_t \tag{4}\\ &[\textbf{k}_{t,1};\textbf{k}_{t,2};\dots,\textbf{k}_{t,n_h}]=\textbf{k}_t \tag{5}\\ &[\textbf{v}_{t,1};\textbf{v}_{t,2};\dots,\textbf{v}_{t,n_h}]=\textbf{v}_t \tag{6}\\ &\textbf{o}_{t,i}=\sum_{j=1}^t\text{softmax}(\frac{\textbf{q}_{t,i}^\top\textbf{k}_{j,i}}{\sqrt{d_h}})\textbf{v}_{j,i} \tag{7}\\ &\textbf{u}_t=w^o[\textbf{o}_{t,1};\textbf{o}_{t,2};\dots,\textbf{o}_{t,n_h}] \tag{8}\\ \end{align} \\
[qt,1;qt,2;…,qt,nh]=qt[kt,1;kt,2;…,kt,nh]=kt[vt,1;vt,2;…,vt,nh]=vtot,i=j=1∑tsoftmax(dhqt,i⊤kj,i)vj,iut=wo[ot,1;ot,2;…,ot,nh](4)(5)(6)(7)(8)
其中
q
t
,
i
,
k
t
,
i
,
v
t
,
i
∈
r
d
h
\textbf{q}_{t,i},\textbf{k}_{t,i},\textbf{v}_{t,i}\in\mathbb{r}^{d_h}
qt,i,kt,i,vt,i∈rdh是第
i
i
i个注意力头的query、key和value,
w
o
∈
r
d
×
d
h
n
h
w^o\in\mathbb{r}^{d\times d_h n_h}
wo∈rd×dhnh是输出投影矩阵。在推理时,所有的key和value都会被缓存来加速推理。对于每个token,mha需要缓存
2
n
h
d
h
l
2n_h d_h l
2nhdhl个元素。
1.2 低秩key-value联合压缩
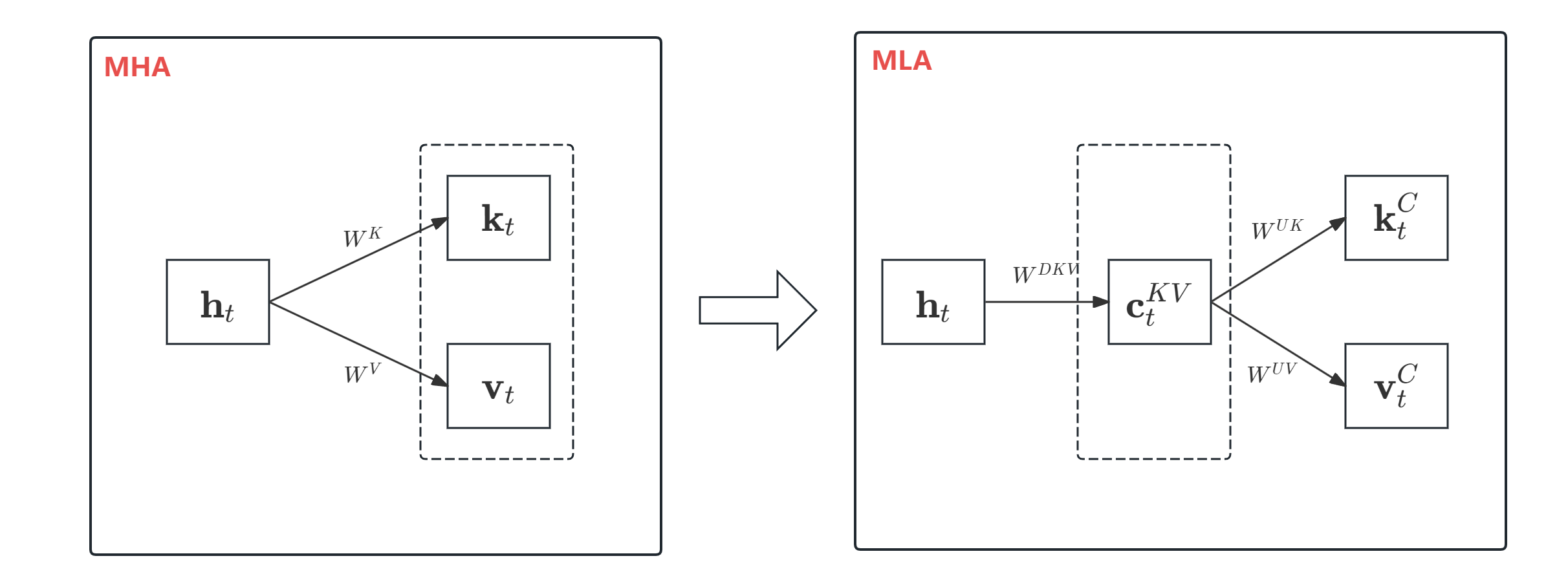
mla通过低秩联合压缩key和value来减少kv cache:
c
t
k
v
=
w
d
k
v
h
t
k
t
c
=
w
u
k
c
t
k
v
v
t
c
=
w
u
v
c
t
k
v
\begin{align} \textbf{c}_t^{kv}&=w^{dkv}\textbf{h}_t \tag{9}\\ \textbf{k}_t^c&=w^{uk}\textbf{c}_t^{kv} \tag{10}\\ \textbf{v}_t^c&=w^{uv}\textbf{c}_t^{kv} \tag{11}\\ \end{align} \\
ctkvktcvtc=wdkvht=wukctkv=wuvctkv(9)(10)(11)
其中
c
t
k
v
∈
r
d
c
\textbf{c}_t^{kv}\in\mathbb{r}^{d_c}
ctkv∈rdc是用于压缩key和value的隐向量;
d
c
(
≪
d
h
n
h
)
d_c(\ll d_h n_h)
dc(≪dhnh)表示kv压缩的维度;
w
d
k
v
∈
r
d
c
×
d
w^{dkv}\in\mathbb{r}^{d_c\times d}
wdkv∈rdc×d是下投影矩阵,
w
u
k
,
w
u
v
∈
r
d
h
n
h
×
d
c
w^{uk},w^{uv}\in\mathbb{r}^{d_h n_h\times d_c}
wuk,wuv∈rdhnh×dc表示上投影矩阵。在推理时,mla仅需要缓存
c
t
k
v
\textbf{c}_t^{kv}
ctkv,因此kv cache仅需要缓存
d
c
l
d_c l
dcl个元素。此外,在推理时可以把
w
u
k
w^{uk}
wuk吸收到
w
q
w^q
wq,
w
u
v
w^{uv}
wuv吸收到
w
o
w^o
wo中,这样甚至都不需要计算key和value。
此外,为了在训练时降低激活的显存占用,对query也进行低秩压缩,即使其不能降低kv cache。具体来说,
c
t
q
=
w
d
q
h
t
q
t
c
=
w
u
q
c
t
q
\begin{align} \textbf{c}_t^q&=w^{dq}\textbf{h}_t \tag{12}\\ \textbf{q}_t^c&=w^{uq}\textbf{c}_t^q \tag{13} \\ \end{align} \\
ctqqtc=wdqht=wuqctq(12)(13)
其中
c
t
q
∈
r
d
c
′
\textbf{c}_t^q\in\mathbb{r}^{d_c'}
ctq∈rdc′是query的压缩后隐向量;
d
c
′
(
≪
d
h
n
h
)
d_c'(\ll d_h n_h)
dc′(≪dhnh)表示query的压缩维度;
w
d
q
∈
r
d
c
′
×
d
,
w
u
q
∈
r
d
h
n
h
×
d
c
′
w^{dq}\in\mathbb{r}^{d_c'\times d},w^{uq}\in\mathbb{r}^{d_h n_h\times d_c'}
wdq∈rdc′×d,wuq∈rdhnh×dc′是下投影矩阵和上投影矩阵。
1.3 解耦rope
rope与低秩kv压缩并不兼容。具体来说,rope对于query和key是位置敏感的。若将rope应用在 k t c \textbf{k}_t^c ktc上,等式10中的 w u k w^{uk} wuk将与位置敏感rope矩阵耦合。但是在推理时, w u k w^{uk} wuk就无法被吸收到 w q w^q wq中,因为对当前生成token相关的rope矩阵将位于 w q w^q wq和 w u k w^{uk} wuk之间,而矩阵乘法不满足交换律。因此,推理时必须重新计算前面token的key,这会显著影响推理效率。
为了解决这个问题,提出使用额外的多头query
q
t
,
i
r
∈
r
d
h
r
\textbf{q}_{t,i}^r\in\mathbb{r}^{d_h^r}
qt,ir∈rdhr和共享key
k
t
r
∈
r
d
h
r
\textbf{k}_t^r\in\mathbb{r}^{d_h^r}
ktr∈rdhr来携带rope,其中
d
h
r
d_h^r
dhr表示解耦query和key的每个头的维度。在mla中使用解耦rope策略的方式为:
q
t
r
=
[
q
t
,
1
r
;
q
t
,
2
r
;
…
;
q
t
,
n
h
r
]
=
rope
(
w
q
r
c
t
q
)
k
t
r
=
rope
(
w
k
r
h
t
)
q
t
,
i
=
[
q
t
,
i
c
;
q
t
,
i
r
]
k
t
,
i
=
[
k
t
,
i
c
;
k
t
r
]
o
t
,
i
=
∑
j
=
1
t
softmax
j
(
q
t
,
i
⊤
k
j
,
i
d
h
+
d
h
r
)
v
j
,
i
c
u
t
=
w
o
[
o
t
,
1
;
o
t
,
2
;
…
;
o
t
,
n
h
]
\begin{align} \textbf{q}_t^r&=[\textbf{q}_{t,1}^r;\textbf{q}_{t,2}^r;\dots;\textbf{q}_{t,n_h}^r]=\text{rope}(w^{qr}\textbf{c}_t^q) \tag{14}\\ \textbf{k}_t^r&=\text{rope}(w^{kr}\textbf{h}_t) \tag{15}\\ \textbf{q}_{t,i}&=[\textbf{q}_{t,i}^c;\textbf{q}_{t,i}^r] \tag{16}\\ \textbf{k}_{t,i}&=[\textbf{k}_{t,i}^c;\textbf{k}_t^r] \tag{17} \\ \textbf{o}_{t,i}&=\sum_{j=1}^t\text{softmax}_j(\frac{\textbf{q}_{t,i}^\top\textbf{k}_{j,i}}{\sqrt{d_h+d_h^r}})\textbf{v}_{j,i}^c \tag{18} \\ \textbf{u}_t&=w^o[\textbf{o}_{t,1};\textbf{o}_{t,2};\dots;\textbf{o}_{t,n_h}] \tag{19}\\ \end{align} \\
qtrktrqt,ikt,iot,iut=[qt,1r;qt,2r;…;qt,nhr]=rope(wqrctq)=rope(wkrht)=[qt,ic;qt,ir]=[kt,ic;ktr]=j=1∑tsoftmaxj(dh+dhrqt,i⊤kj,i)vj,ic=wo[ot,1;ot,2;…;ot,nh](14)(15)(16)(17)(18)(19)
其中
w
q
r
∈
r
d
h
r
n
h
×
d
c
′
w^{qr}\in\mathbb{r}^{d_h^r n_h\times d_c'}
wqr∈rdhrnh×dc′和
w
k
r
∈
r
d
h
r
×
d
w^{kr}\in\mathbb{r}^{d_h^r\times d}
wkr∈rdhr×d是用于产生解耦query和key的矩阵;
rope
(
⋅
)
\text{rope}(\cdot)
rope(⋅)表示应用rope的操作;
[
⋅
;
⋅
]
[\cdot;\cdot]
[⋅;⋅]表示拼接操作。在推理时,解耦的key也需要被缓存。因此,deekseek-v2需要的总kv cache包含
(
d
c
+
d
h
r
)
l
(d_c+d_h^r)l
(dc+dhr)l个元素。
1.4 结论
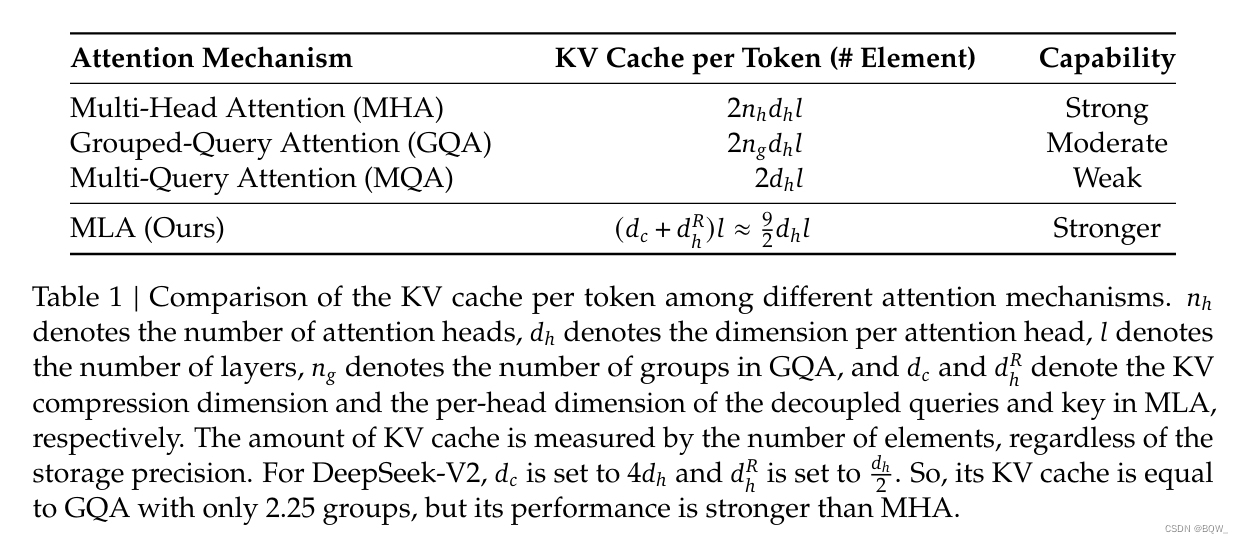
mla能够通过更少的kv cache实现比mha更好的效果。
2. 整体结构
2.1 基础结构
对于ffn层,利用deepseekmoe架构,即将专家划分为更细粒度,从而获得更专业化的专家以及获取更准确的知识。在具有相同激活和总专家参数的情况下,deepseekmoe能够大幅度超越传统moe架构。
令
u
t
\textbf{u}_t
ut是第t个token对ffn的输入,那么计算ffn的输出
h
t
′
\textbf{h}_t'
ht′为:
h
t
′
=
u
t
+
∑
i
=
1
n
s
ffn
i
(
s
)
(
u
t
)
+
∑
i
=
1
n
r
g
i
,
t
ffn
i
(
r
)
(
u
t
)
g
i
,
t
=
{
s
i
,
t
,
s
i
,
t
∈
topk
(
{
s
j
,
t
∣
1
≤
j
≤
n
r
}
,
k
r
)
0
,
otherwise
s
i
,
t
=
softmax
i
(
u
t
⊤
e
i
)
\begin{align} \textbf{h}_t'&=\textbf{u}_t+\sum_{i=1}^{n_s}\text{ffn}_i^{(s)}(\textbf{u}_t)+\sum_{i=1}^{n_r}g_{i,t}\text{ffn}_{i}^{(r)}(\textbf{u}_t) \tag{20}\\ g_{i,t}&=\begin{cases} s_{i,t},& s_{i,t}\in\text{topk}(\{s_{j,t}|1\leq j\leq n_r\},k_r)\\ 0,&\text{otherwise} \end{cases}\tag{21}\\ s_{i,t}&=\text{softmax}_i(\textbf{u}_t^\top \textbf{e}_i) \tag{22}\\ \end{align} \\
ht′gi,tsi,t=ut+i=1∑nsffni(s)(ut)+i=1∑nrgi,tffni(r)(ut)={si,t,0,si,t∈topk({sj,t∣1≤j≤nr},kr)otherwise=softmaxi(ut⊤ei)(20)(21)(22)
其中
n
s
n_s
ns和
n
r
n_r
nr表示共享专家和路由专家的数量;
ffn
i
(
s
)
(
⋅
)
\text{ffn}_i^{(s)}(\cdot)
ffni(s)(⋅)和
ffn
i
(
r
)
(
⋅
)
\text{ffn}_i^{(r)}(\cdot)
ffni(r)(⋅)表示第i个共享专家和第i个路由专家;
k
r
k_r
kr表示激活路由专家的数量;
g
i
,
t
g_{i,t}
gi,t是第i个专家的门限值;
e
i
\textbf{e}_i
ei是当前层第i个路由专家的中心。
2.2 设备受限路由
设计了一种设备受限路由机制来控制moe相关的通信成本。当采用专家并行时,路由专家将分布在多个设备上。对于每个token,moe相关的通信频率与目标专家覆盖的设备数量成正比。由于在deepseekmoe中细粒度专家划分,激活专家的数量会很大,因此应用专家并行时,与moe相关的通信将更加昂贵。
对于deepseek-v2,除了路由专家会选择top-k个以外,还会确保每个token的目标专家最多分布在m个设备上。具体来说,对于每个token,先选择包含最高分数专家的m个设备。然后在这m个设备上执行top-k选择。在实践中,当 m ≥ 3 m\geq 3 m≥3时,设备受限路由能够实现与不受限top-k路由大致一致的良好性能。
2.3 用于负载均衡的辅助loss
不平衡的负载会增加路由坍缩的风险,使一些专家无法得到充分的训练和利用。此外,当使用专家并行时,不平衡的负载降低计算效率。在deepseek-v2训练时,设计了三种辅助损失函数用于控制专家级别负载均衡 ( l expbal ) (\mathcal{l}_{\text{expbal}}) (lexpbal)、设备级别负载均衡 ( l devbal ) (\mathcal{l}_{\text{devbal}}) (ldevbal)和通信均衡 l commbal \mathcal{l}_{\text{commbal}} lcommbal。
专家级均衡loss。专家级均衡loss用于缓解路由坍缩问题:
l
expbal
=
α
1
∑
i
=
1
n
r
f
i
p
i
,
f
i
=
n
r
k
r
t
∑
t
=
1
t
1
(token t selects expert i)
p
i
=
1
t
∑
t
=
1
t
s
i
,
t
\begin{align} \mathcal{l}_{\text{expbal}}&=\alpha_1\sum_{i=1}^{n_r}f_ip_i, \tag{23} \\ f_i&=\frac{n_r}{k_r t}\sum_{t=1}^t\mathbb{1}\text{(token t selects expert i)} \tag{24} \\ p_i&=\frac{1}{t}\sum_{t=1}^t s_{i,t} \tag{25} \\ \end{align} \\
lexpbalfipi=α1i=1∑nrfipi,=krtnrt=1∑t1(token t selects expert i)=t1t=1∑tsi,t(23)(24)(25)
其中
α
1
\alpha_1
α1是称为专家级均衡因子的超参数;
1
(
⋅
)
\mathbb{1}(\cdot)
1(⋅)是指示函数;
t
t
t是序列中token的数量。
设备级均衡loss。除了专家级均衡loss以外,也设计了设备级别均衡loss来确保跨设备均衡计算。在deepseek-v2训练过程中,将所有的专家划分至
d
d
d组
{
e
1
,
e
2
,
…
,
e
d
}
\{\mathcal{e}_1,\mathcal{e}_2,\dots,\mathcal{e}_d\}
{e1,e2,…,ed}并在单个设备上部署每个组。设备级均衡loss计算如下:
l
devbal
=
α
2
∑
i
=
1
d
f
i
′
p
i
′
f
i
′
=
1
e
i
∑
j
∈
e
i
f
j
p
i
′
=
∑
j
∈
e
i
p
j
\begin{align} \mathcal{l}_{\text{devbal}}&=\alpha_2\sum_{i=1}^d f_i' p_i'\tag{26} \\ f_i'&=\frac{1}{\mathcal{e}_i}\sum_{j\in\mathcal{e}_i}f_j \tag{27} \\ p_i'&=\sum_{j\in\mathcal{e}_i}p_j \tag{28} \\ \end{align} \\
ldevbalfi′pi′=α2i=1∑dfi′pi′=ei1j∈ei∑fj=j∈ei∑pj(26)(27)(28)
其中
α
2
\alpha_2
α2是称为设备级均衡因子的超参数。
通信均衡loss。通信均衡loss能够确保每个设备通信的均衡。虽然设备限制路由机制能够确保每个设备发送信息有上限,但是当某个设备比其他设备接收更多的tokens,那么实际通信效率将会有影响。为了缓解这个问题,设计了一种通信均衡loss如下:
l
commbal
=
α
3
∑
t
=
1
d
f
i
′
′
p
i
′
′
f
i
′
′
=
d
m
t
∑
t
=
1
t
1
(token t is sent to device i)
p
i
′
′
=
∑
j
∈
e
i
p
j
\begin{align} \mathcal{l}_{\text{commbal}}&=\alpha_3\sum_{t=1}^d f_i''p_i''\tag{29} \\ f_i''&=\frac{d}{mt}\sum_{t=1}^t\mathbb{1}\text{(token t is sent to device i)}\tag{30} \\ p_i''&=\sum_{j\in\mathcal{e}_i}p_j\tag{31} \\ \end{align} \\
lcommbalfi′′pi′′=α3t=1∑dfi′′pi′′=mtdt=1∑t1(token t is sent to device i)=j∈ei∑pj(29)(30)(31)
其中
α
3
\alpha_3
α3是称为通信均衡因子的超参数。设备受限路由机制操作主要确保每个设备至多向其他设备传输mt个hidden states。同时,通信均衡loss用来鼓励每个设备从其他设备接受mt个hidden states。通信均衡loss确保设备间信息均衡交换,实现高效通信。
2.4 token-dropping策略
虽然均衡loss的目标是确保均衡负载,但是其并不能严格确保负载均衡。为了进一步缓解由于不均衡导致的计算浪费,在训练时引入了设备级别的token-dropping策略。该方法会先计算每个设备的平均计算预算,这意味着每个设备的容量因子等于1.0。然而,在每个设备上drop具有最低affinity分数的token,直到达到计算预算。此外,确保大约10%的训练序列的token永远不会被drop。这样,可以根据效率要求灵活地决定是否在推理过程中drop token,并确保训练和推理的一致性。
三、预训练
1. 实验设置
1.1 数据构造
数据处理过程同deepseek 67b,并进一步扩展数据量和质量。采用与deepseek 67b相同的tokenizer。预训练语料包含8.1t tokens,中文token比英文多12%。
1.2 超参数
略
1.3 infrastructures
deepseek-v2训练基于hai-llm框架。利用16路0气泡流水并行、8路专家并行和zero-1数据并行。考虑到deepseek-v2具有相对较少的激活参数,并且对一部分操作进行重计算来节约激活显存,因此可以不使用张量并行,从而降低通信开销。此外,为了进一步提高训练效率,使用专家并行all-to-all通信来重叠共享专家的计算。使用定制化的cuda核来改善通信、路由算法和不同专家之间融合线性计算。此外,mla基于改善版本的flashattention-2进行优化。
1.4 长上下文扩展
使用yarn将上下文窗口尺寸从4k扩展至128k。
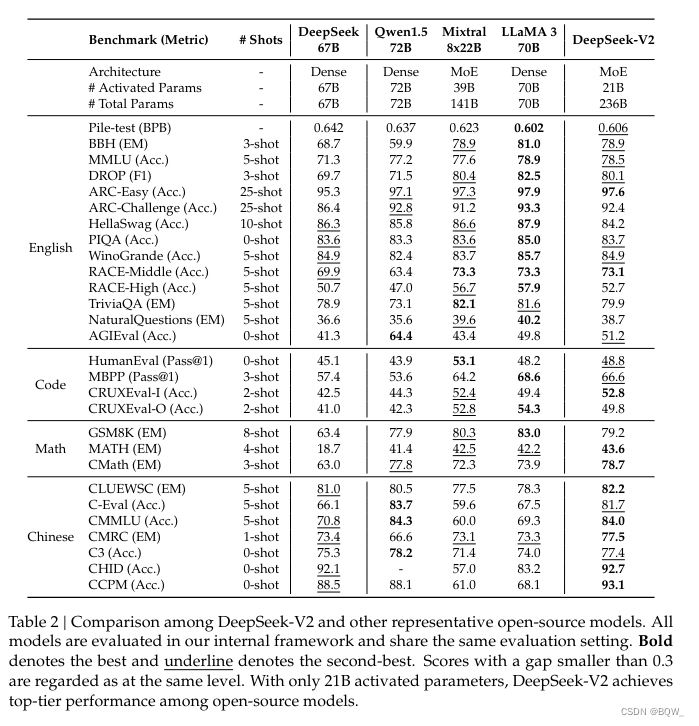
2. 评估
四、对齐
sft。 使用了150万样本的微调数据,其中120万是用于有用性,30万则用于安全性。
强化学习。仍然采用grpo。
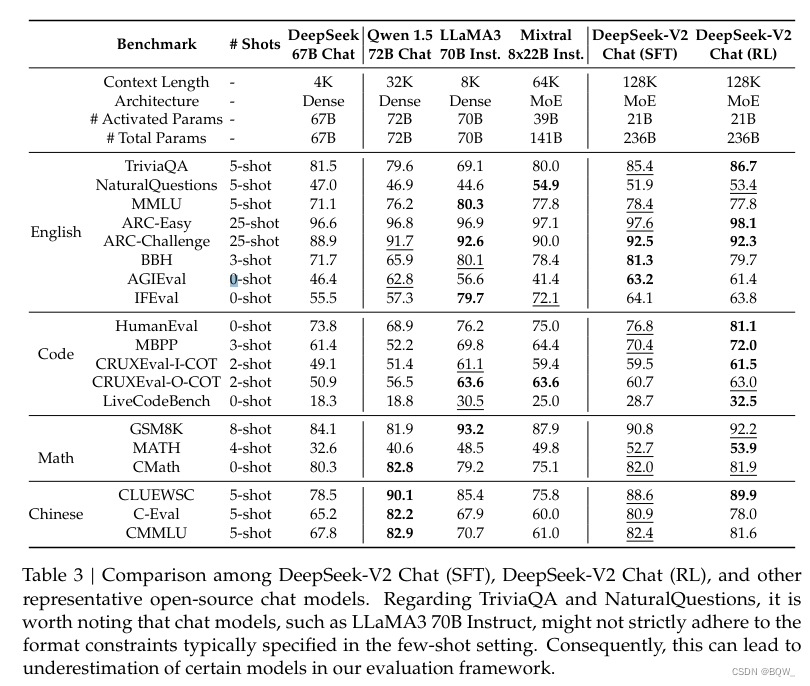
结果。




发表评论