文章目录
1、简介
https://github.com/systran/faster-whisper
https://pypi.org/project/faster-whisper/
faster-whisper是whisper开源后的第三方进化版本,它对原始的 whisper 模型结构进行了改进和优化。
faster-whisper 是使用 ctranslate2 重新实现 openai 的 whisper 模型,ctranslate2 是 transformer 模型的快速推理引擎。
此实现比 openai/whisper 快 4 倍,同时使用更少的内存实现相同的准确性。通过对 cpu 和 gpu 进行 8 位量化,可以进一步提高效率。
1.1 ctranslate2
https://github.com/opennmt/ctranslate2/
ctranslate2 是一个 c++ 和 python 库,用于使用 transformer 模型进行高效推理。
该项目实现了一个自定义运行时,该运行时应用了许多性能优化技术,例如权重量化、层融合、批量重新排序等,以加速和减少 transformer 模型在 cpu 和 gpu 上的内存使用。
ctranslate2 可以用 pip 安装:
pip install ctranslate2
1.2 intel mkl
https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/onemkl-download.html
ctranslate2 的核心是其高度优化的模型推理实现。它支持多种硬件平台,包括 cpu 和 gpu,并利用了底层的并行计算库如 intel mkl 或者 cudnn 来最大化性能。
1.3 cudnn
https://developer.nvidia.com/cudnn
nvidia cuda® 深度神经网络库 (cudnn) 是用于深度神经网络的 gpu 加速基元库。cudnn 为标准例程(如前向和后向卷积、注意力、matmul、池化和归一化)提供高度优化的实现。
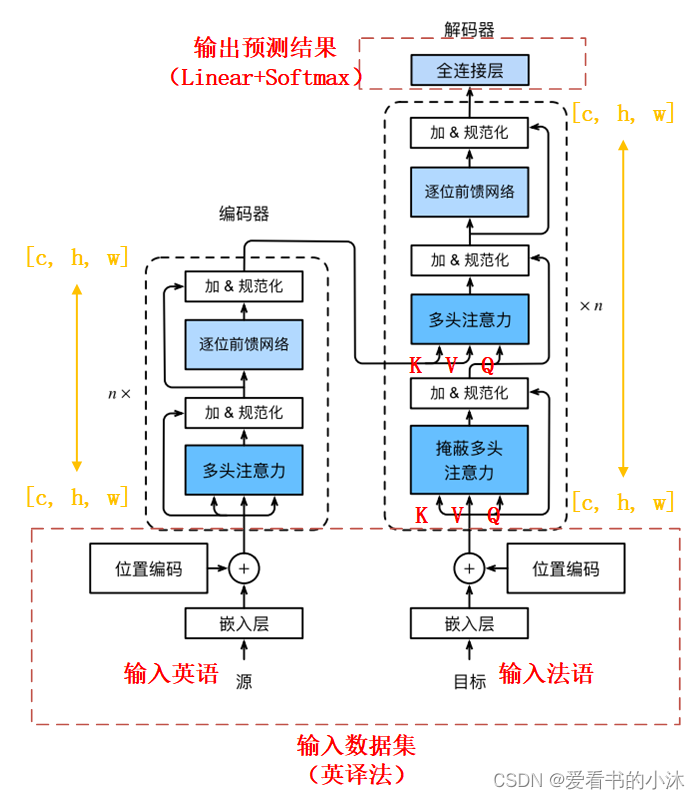
1.4 transformer
https://arxiv.org/pdf/1706.03762
目前,自然语言处理中,有三种特征处理器:卷积神经网络、递归神经网络和后起之秀 transformer。transformer 风头已经盖过两个前辈,它抛弃了传统的卷积神经网络和递归神经网络,整个网络结构完全是由注意力机制组成。准确地讲,transformer 仅由自注意力和前馈神经网络组成。

2、下载和安装
2.1 命令行
https://github.com/purfview/whisper-standalone-win
whisper & faster-whisper 独立可执行文件,适合那些不想打扰 python 的人。
解压文件夹如下:
测试如下:
whisper-faster.exe "d:\videofile.mkv" --language english --model medium --output_dir source
whisper-faster.exe "d:\videofile.mkv" -l english -m medium -o source --sentence
whisper-faster.exe "d:\videofile.mkv" -l japanese -m medium --task translate --standard
whisper-faster.exe --help
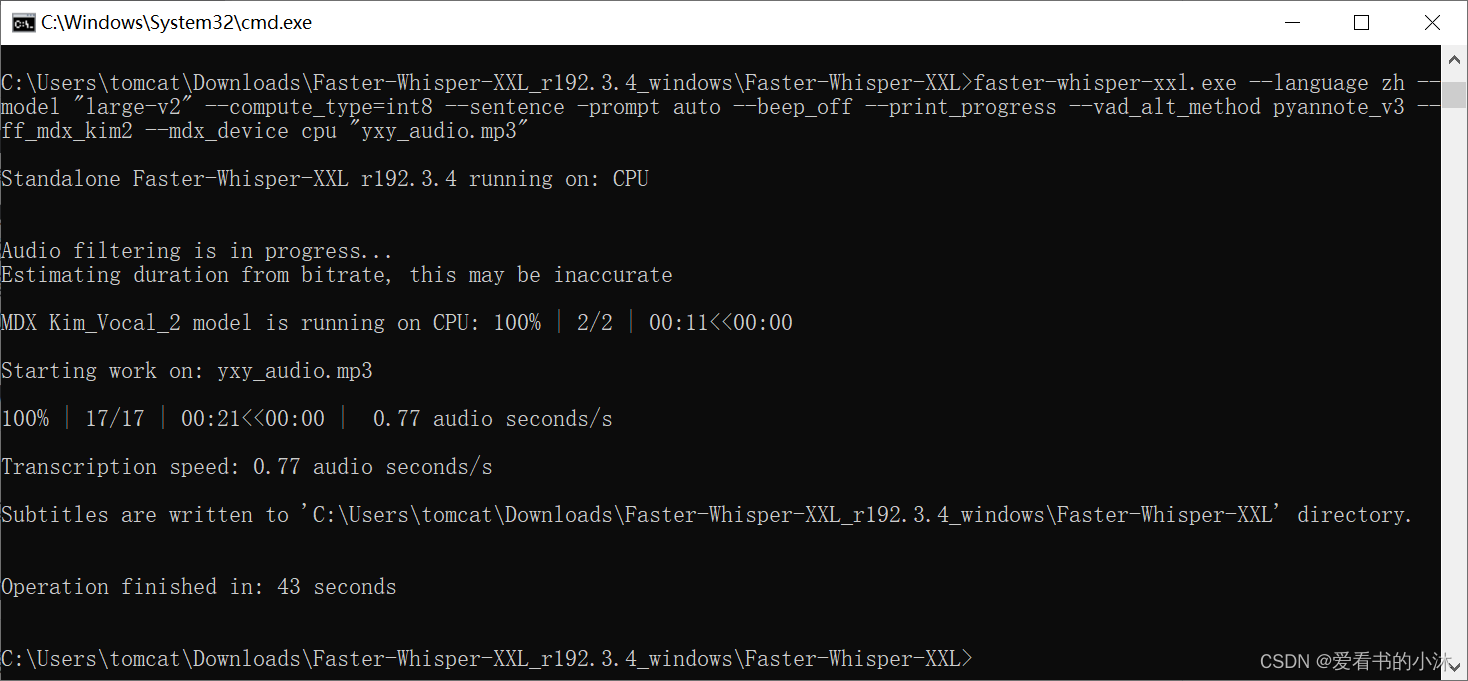
faster-whisper-xxl.exe --language zh --model "large-v2" --compute_type=int8 --sentence -prompt auto --beep_off --print_progress --vad_alt_method pyannote_v3 --ff_mdx_kim2 --mdx_device cpu "yxy_audio.mp3"
2.2 代码
从 pypi 安装:
pip install faster-whisper
3、模型下载
3.1 在线测试
3.1.1 tiny
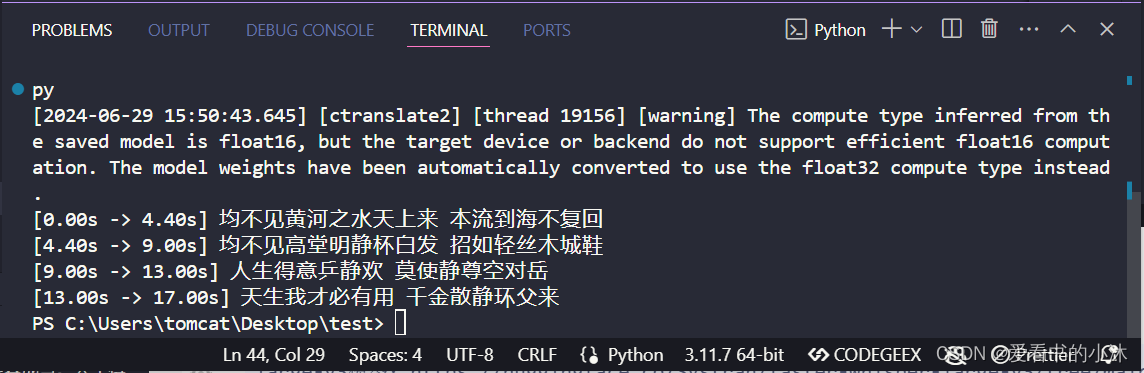
from faster_whisper import whispermodel
model = whispermodel("tiny")
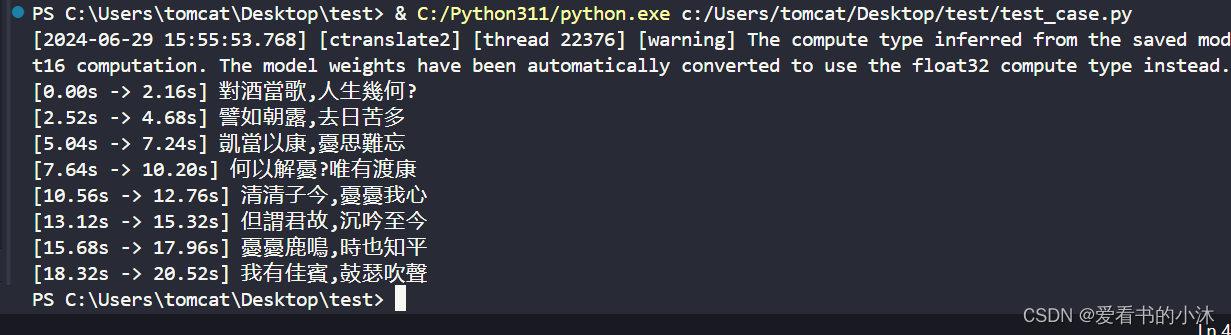
segments, info = model.transcribe("yxy_audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
3.1.2 large-v2
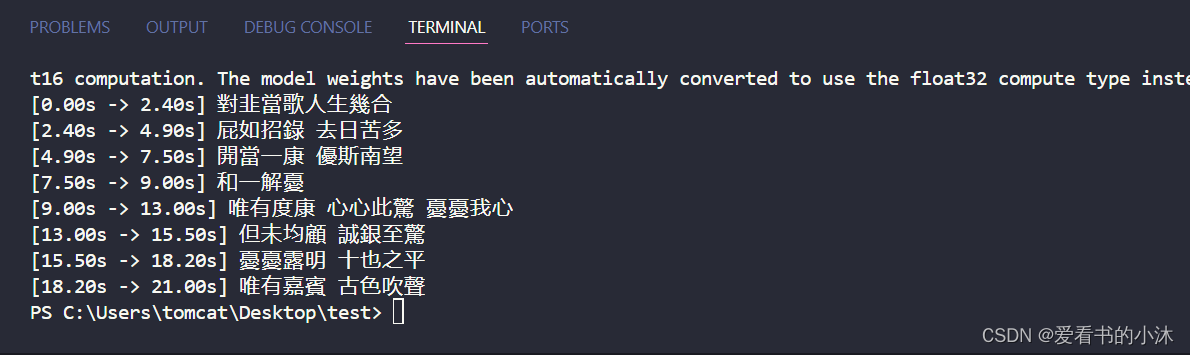
from faster_whisper import whispermodel
model = whispermodel("large-v2")
segments, info = model.transcribe("yxy_audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
3.2 离线测试
large-v3模型:https://huggingface.co/systran/faster-whisper-large-v3/tree/main
large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-large-v2/tree/main
large-v1模型:https://huggingface.co/guillaumekln/faster-whisper-large-v1/tree/main
medium模型:https://huggingface.co/guillaumekln/faster-whisper-medium/tree/main
small模型:https://huggingface.co/guillaumekln/faster-whisper-small/tree/main
base模型:https://huggingface.co/guillaumekln/faster-whisper-base/tree/main
tiny模型:https://huggingface.co/guillaumekln/faster-whisper-tiny/tree/main
or
https://aifasthub.com/models/guillaumekln
3.2.1 tiny
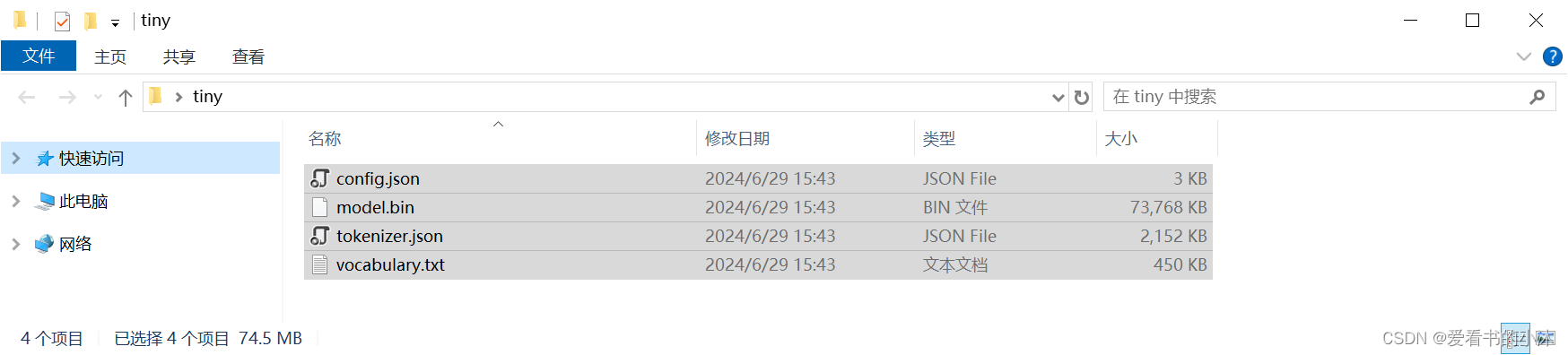
这里下载tiny模型到本地:
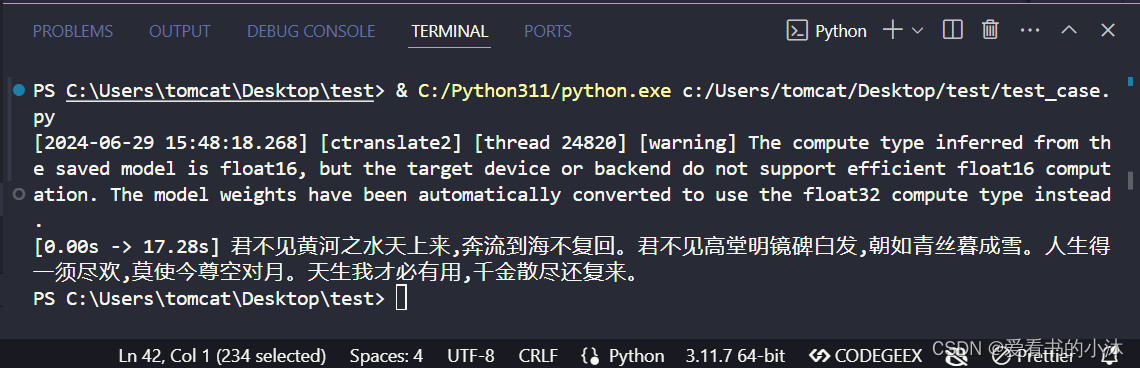
from faster_whisper import whispermodel
model_size = "large-v2"
path = r"c:\users\tomcat\desktop\tiny"
# run on gpu with fp16
model = whispermodel(model_size_or_path=path, device="cpu", local_files_only=true)
# or run on gpu with int8
# model = whispermodel(model_size, device="cuda", compute_type="int8_float16")
# or run on cpu with int8
# model = whispermodel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("yxy_audio2.mp3", beam_size=5, language="zh", vad_filter=true, vad_parameters=dict(min_silence_duration_ms=1000))
print("detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))

local_files_only=true 表示加载本地模型
model_size_or_path=path 指定加载模型路径
device="cuda" 指定使用cuda or cpu
compute_type="int8_float16" 量化为8位
language="zh" 指定音频语言
vad_filter=true 开启vad
vad_parameters=dict(min_silence_duration_ms=1000) 设置vad参数
3.2.1 large-v2
这里下载large-v2模型到本地:
from faster_whisper import whispermodel
model_size = "large-v2"
path = r"c:\users\tomcat\desktop\large-v2"
# run on gpu with fp16
model = whispermodel(model_size_or_path=path, device="cpu", local_files_only=true)
# or run on gpu with int8
# model = whispermodel(model_size, device="cuda", compute_type="int8_float16")
# or run on cpu with int8
# model = whispermodel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("yxy_audio2.mp3", beam_size=5, language="zh", vad_filter=true, vad_parameters=dict(min_silence_duration_ms=1000))
print("detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
下载cublas and cudnn:
https://github.com/purfview/whisper-standalone-win/releases/tag/libs


2024第四届人工智能、自动化与高性能计算国际会议(aiahpc 2024)将于2024年7月19-21日在中国·珠海召开。
大会网站:更多会议详情
时间地点:中国珠海-中山大学珠海校区|2024年7月19-21日
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_o???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!

发表评论