这是我的第276篇原创文章。
一、引言
前面我介绍了多个方法实现单变量和多变量时序数据的单站点单步预测,好多小伙伴最近问我这个lstm模型数据的输入的格式是怎么样的,今天我专门写一篇文章来聊一聊这个问题,希望对大家有所启发和帮助。
二、实现过程
2.1 单变量时序数据
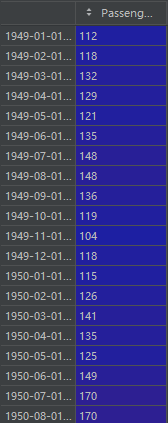
1、原始data
原始数据是一个144行1列的(144,1)的dataframe:
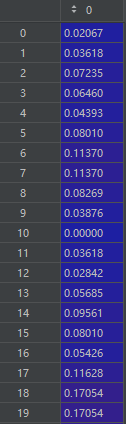
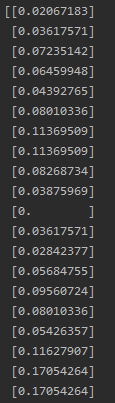
2、数据集按照8:2划分,并进行归一化处理
train_data_scaler是一个(115,1)的二维数组:
3、创建滑动窗口数据集
将train_data_scaler集转换为 lstm 模型所需的形状(样本数,时间步长,特征数):
def create_sliding_windows(data, window_size):
x, y = [], []
for i in range(len(data) - window_size):
x.append(data[i:i+window_size, 0:data.shape[1]])
y.append(data[i+window_size,0])
return np.array(x), np.array(y)
x_train, y_train = create_sliding_windows(train_data_scaler, window_size)这里我假设窗口window_size设为12,i的范围0-102,103取不到:
当i=0时,取出train_data_scaler第【1-12】行第【1】列的12条数据作为x_train[0],取出train_data_scaler第【13】行第【1】列的1条数据作为y_train[0];
当i=1时,取出train_data_scaler第【2-13】行第【1】列的12条数据作为x_train[1],取出train_data_scaler第【14】行第【1】列的1条数据作为y_train[1];
...
当i=102时,取出train_data_scaler第【103-114】行第【1】列的12条数据作为x_train[102],取出train_data_scaler第【115】行第【1】列的1条数据作为y_train[102];
返回的x_train是一个(103,12,1)的三维数组;y_train是一个(103,1)的二维数组;
x_train = np.reshape(x_train, (x_train.shape[0], window_size, 1)经过滑动窗口之后返回的形状已经是lstm所需的形状了,所以这句话可以省略。
4、构建 lstm 模型
# 构建 lstm 模型
model = sequential()
model.add(lstm(50, activation='relu', input_shape=(window_size, 1)))
model.add(dense(1))
model.compile(optimizer='adam', loss='mse')lstm的input_shape=(时间步长,特征数),其实就是一个样本输入的形状。
5、训练 lstm 模型
# 训练 lstm 模型
model.fit(x_train, y_train, epochs=100, batch_size=32)-
x_train是一个(103,12,1)的三维数组,三个维度分别表示(样本数,时间步长,特征数)
-
y_train是一个(103,1)的二维数组,两个维度分别表示(样本数,标签)
-
类似一个103行(12*1+1)列的表格,前(12*1)列是特征,第(12*1+1)列是标签
2.2 多变量时序数据
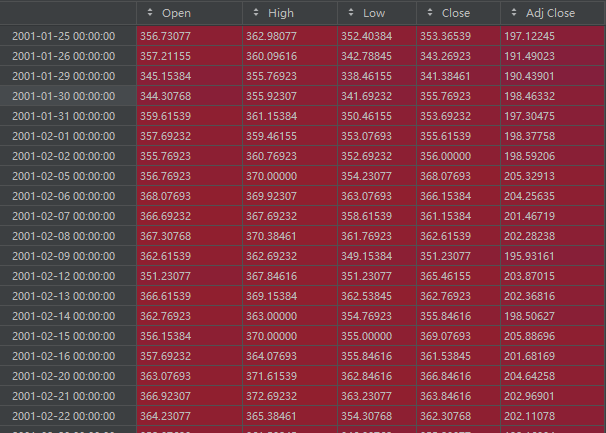
1、原始的data
是一个(5203,5)的dataframe:
2、数据集按照8:2划分,并进行归一化处理
train_data_scaler是一个(4162,5)的二维数组:
3、创建滑动窗口数据集
将数据集转换为 lstm 模型所需的形状(样本数,时间步长,特征数):
def create_sliding_windows(data, window_size):
x, y = [], []
for i in range(len(data) - window_size):
x.append(data[i:i+window_size, 0:data.shape[1]])
y.append(data[i+window_size,0])
return np.array(x), np.array(y)
x_train, y_train = create_sliding_windows(train_data_scaler, window_size)这里我假设窗口window_size设为30,i的范围0-4131:
当i=0时,取出train_data_scaler第【1-30】行第【1-5】列的12条数据作为x_train[0],取出train_data_scaler第【31】行第【1】列的1条数据作为y_train[0];
当i=1时,取出train_data_scaler第【2-31】行第【1-5】列的12条数据作为x_train[1],取出train_data_scaler第【32】行第【1】列的1条数据作为y_train[1];
...
当i=4131时,取出train_data_scaler第【4132-4161】行第【1-5】列的12条数据作为x_train[4131],取出train_data_scaler第【4162】行第【1】列的1条数据作为y_train[4131];
返回的x_train是一个(4132,30,5)的三维数组;y_train是一个(4132,1)的二维数组;
x_train = np.reshape(x_train, (x_train.shape[0], window_size, 5)经过滑动窗口之后返回的形状已经是lstm所需的形状了,所以这句话可以省略。
4、构建 lstm 模型
# 构建 lstm 模型
model = sequential()
model.add(lstm(50, activation='relu', input_shape=(window_size, 5)))
model.add(dense(1))
model.compile(optimizer='adam', loss='mse')lstm的input_shape=(时间步长,特征数),其实就是一个样本输入的形状。
5、训练 lstm 模型
# 训练 lstm 模型
model.fit(x_train, y_train, epochs=100, batch_size=32)-
x_train是一个(4132,30,5)的三维数组;(样本数,时间步长,特征数)
-
y_train是一个(4132,1)的二维数组;(样本数,标签)
-
类似一个4132行(30*5+1)列的表格,前(30*5)列是特征,第(30*5+1)列是标签
三、小结
由于滑动窗口,实际的训练数据数量少一个窗口数量,实际能预测的数据量也少一个窗口数量。


发表评论