在当今快速发展的人工智能环境中,部署开源大型语言模型 (llm) 通常需要复杂的计算基础设施。然而,ollama 的创新平台正在改变这一规范,支持在标准个人计算机上使用这些强大的模型,支持cpu和gpu配置。本指南介绍了如何使用 ollama 在您自己的设备上设置和管理 llm,重点介绍了允许广泛的参数模型在仅具有 cpu 的系统上高效运行的技术进步。
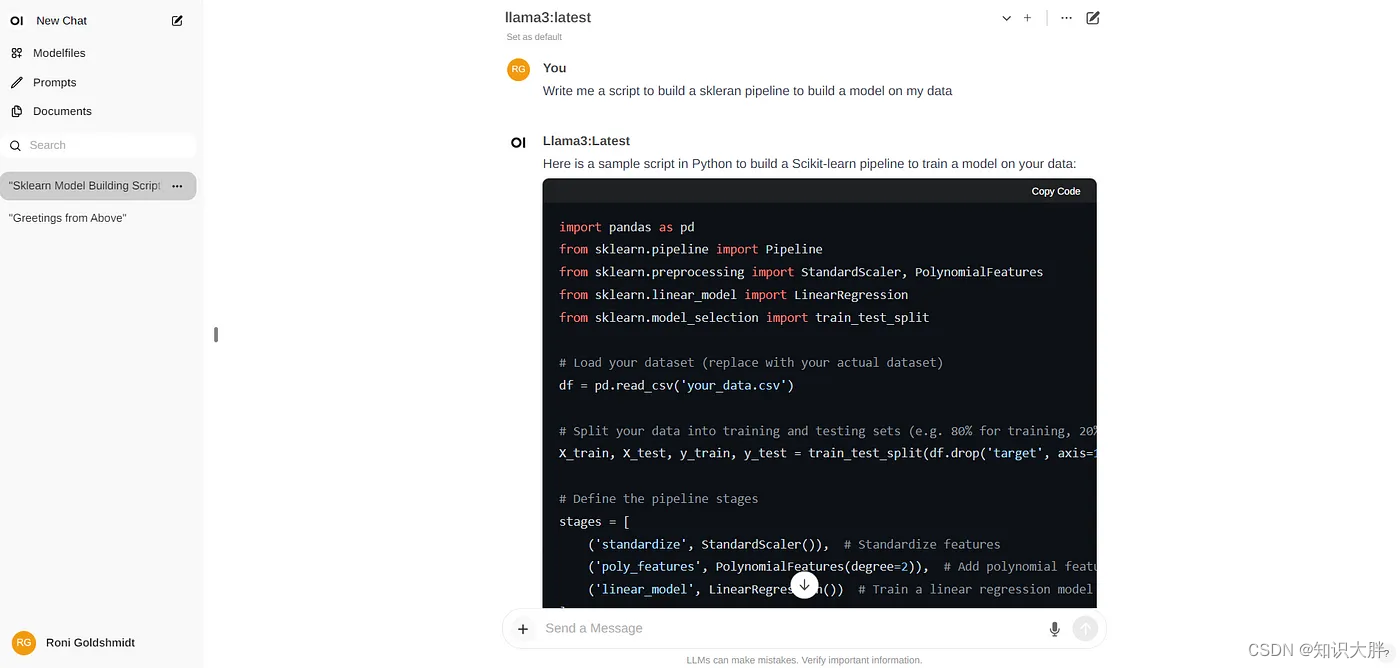
本指南提供了使用 ollama 平台安装 llm llama-3 的分步说明。如果您希望使用 ollama 库中的不同模型,只需相应地替换模型名称即可。您可以在此处访问完整的 ollama 库。
此外,本指南详细介绍了ollama的完整设置过程,包括在基础设施中部署 llama- 3模型,以及如何使用 api 或open webui ui与模型交互,并提供了安装步骤。此外,它还包括使用 gpu 和 cpu 设置之间的性能比较。
介绍
ollama是一个强大的框架,专为大型语言模型的本地执行而设计。它提供了一种用户友好的方法来部署和管理人工智能模型,使用户能够直接从他们的机器运行各种预训练或自定义模型。 ollama 的多功能性突出在于其全面的模型库,范围从较小的 80 亿参数模型到大量的 700 亿参数版本,可满足不同的计算和应用需求。
ollama 优化的技术见解
ollama 采用了一系列优化来确保跨不同硬件设置的高效模型性能:
硬件优化:利用 gpu 加速显着提高性能,在纯 cpu 配置上实现高达两倍的处理速度。
模型压缩:实施量化和稀疏微调等先进技术,以减少模型




发表评论