下面对知识图谱的嵌入模型transe进行原理讲解,文末提供完整全注释版代码。
- transe模型原理
知识图谱首要任务是知识图谱的嵌入,知识图谱的嵌入中,最为经典的模型就是transe模型,transe模型的核心作用就是将知识图谱中的三元组翻译成embedding向量
该模型的基本思想是使head向量和relation向量的和尽可能靠近tail向量。这里我们用l1或l2范数来衡量它们的靠近程度。
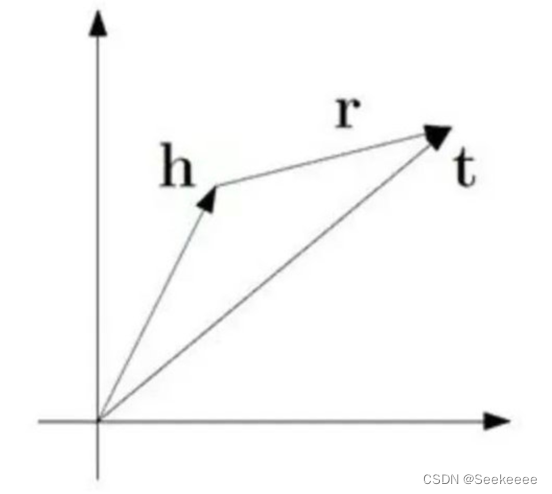
理解下来也就是:
首先,确定训练集,超参数γ,学习率λ
初始化关系向量与实体向量,对于每个向量的每个维度在 [ -6/√k,6/√k)内随机取一个值,k为低维向量的维数,对所有的向量初始化之后要进行归一化
进入循环:采用minibatch,一批一批的训练会加快训练速度,对于每批数据进行负采样(将训练集中的三元组某一实体随机替换掉),t_batch初始为一个空列表,然后向其添加由元组对(原三元组,打碎的三元组)组成的列表 : t_batch = [ ( [h,r,t], [h',r,t'] ), ([ ], [ ]), ......]
拿到t_batch后进行训练,采用梯度下降进行调参

transe 定义了一个距离函数 d(h + r, t),它用来衡量 h + r 和 t 之间的距离,在实际应用中可以使用 l1 或 l2 范数。在模型的训练过程中,transe采用最大间隔方法,最小化目标函数,目标函数如下:
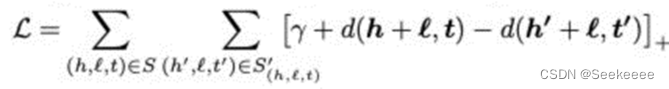
其中,s是知识库中的三元组即训练集,s’是负采样的三元组,通过替换 h 或 t 所得,是人为随机生成的。γ 是取值大于0的间隔距离参数,是一个超参数,[x]+表示正值函数,即 x > 0时,[x]+ = x;当 x ≤ 0 时,[x]+ = 0 。算法模型比较简单,梯度更新只需计算距离 d(h+r, t) 和 d(h’+r, t’)。
免费获取代码:
链接:https://pan.baidu.com/s/1qogwppt_jfputzxdonvmka?pwd=2222
提取码:2222
--来自百度网盘超级会员v4的分享

发表评论