目录
一、下载nltk_data-gh-pages.zip数据文件
一、下载nltk_data-gh-pages.zip数据文件
nltk_data: nltk data - gitee.com
点击上方链接,进入到如下界面:
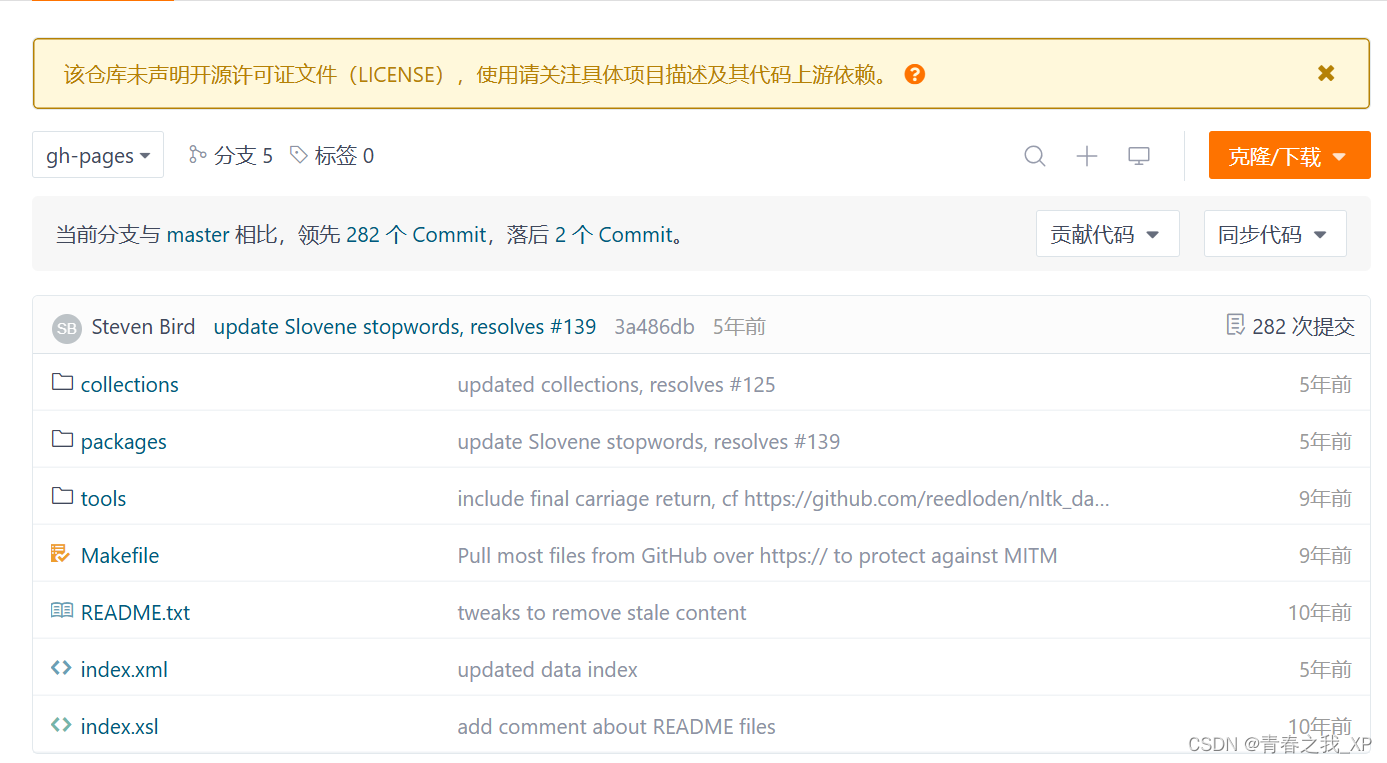
然后点击右上角的克隆下载,进入到如下界面,然后再点击下载zip,开始下载nltk_data-gh-pages.zip文件。

将下载得到的nltk_data-gh-pages.zip文件解压缩,解压缩后的内容如下:
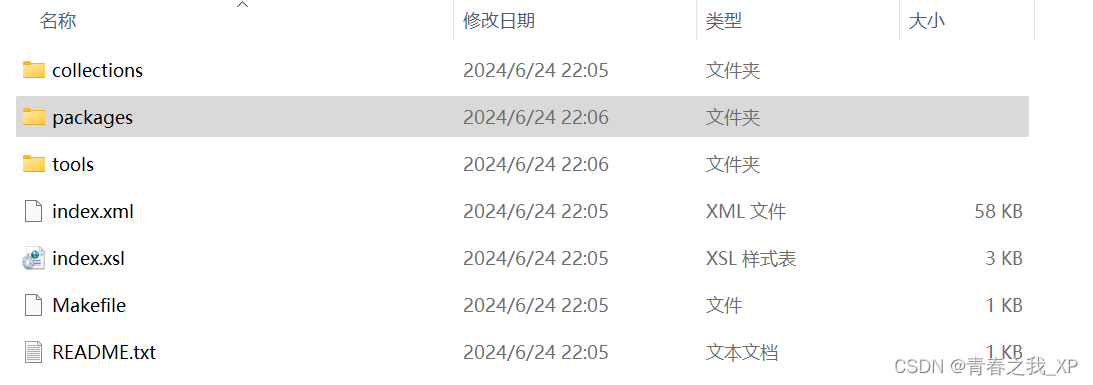
重点:我们只需要其中的packages,将packages文件夹重新命名为nltk_data
二、将nltk_data文件夹移到对应的目录
import nltk
nltk.find('.')运行上方两行代码,我的运行结果是
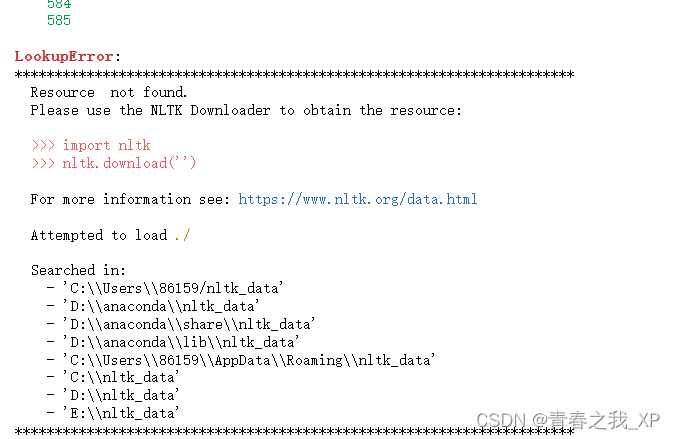
则将nltk_data文件夹移动到searched in下边的任意路径都可。
三、测试
运行结果出现以下界面就是安装成功了。

四、成功调用punkt库
问题:
有的小伙伴在成功完成上边的步骤之后,在运行下边两行代码的时候仍然报错。
import nltk
nltk.download('punkt') 或者
运行下方代码时,仍然报错,报错的大概意思是没有punkt库。
from nltk.tokenize import word_tokenize
from nltk.text import text
input_str = "today's weather is good, very windy and sunny, we have no classes in the afternoon,we have to play basketball tomorrow."
tokens = word_tokenize(input_str)解决方案:
step1:打开刚刚路径下的nltk_data
step2:打开其中的tokenizers文件夹
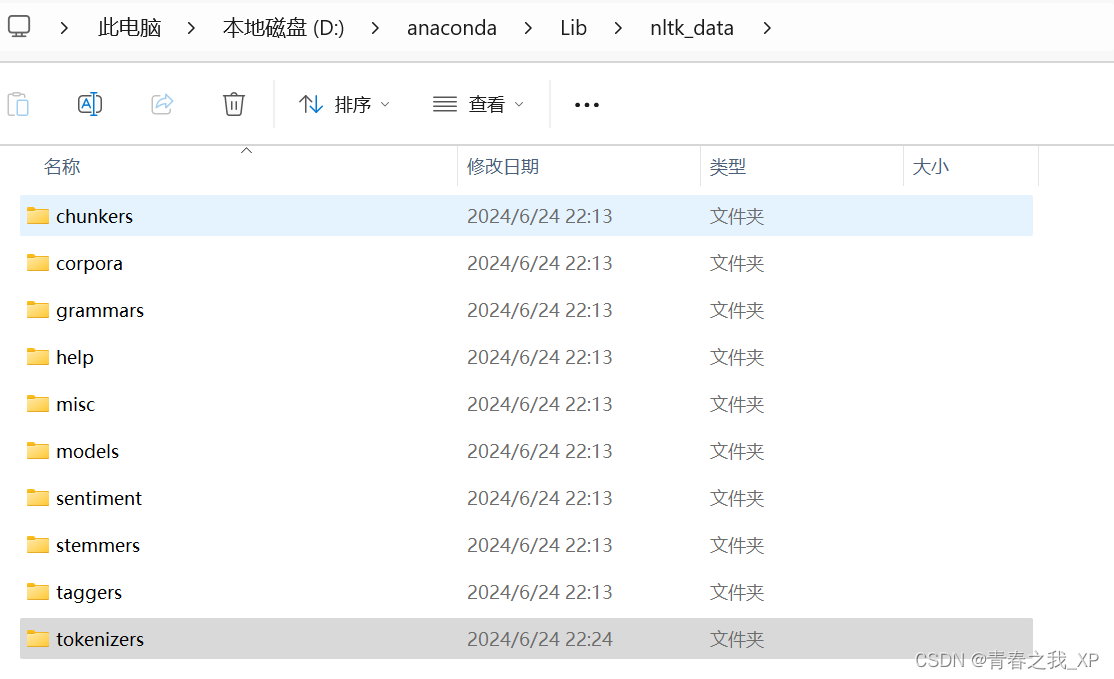
发现其中虽然有punkt,但是还没有解压,关键点就在于将其解压到当前文件路径下。

同时还有一个关键点需要注意,否则很有可能不成功。解压punkt.zip之后,punkt文件夹里的内容应该是如下:
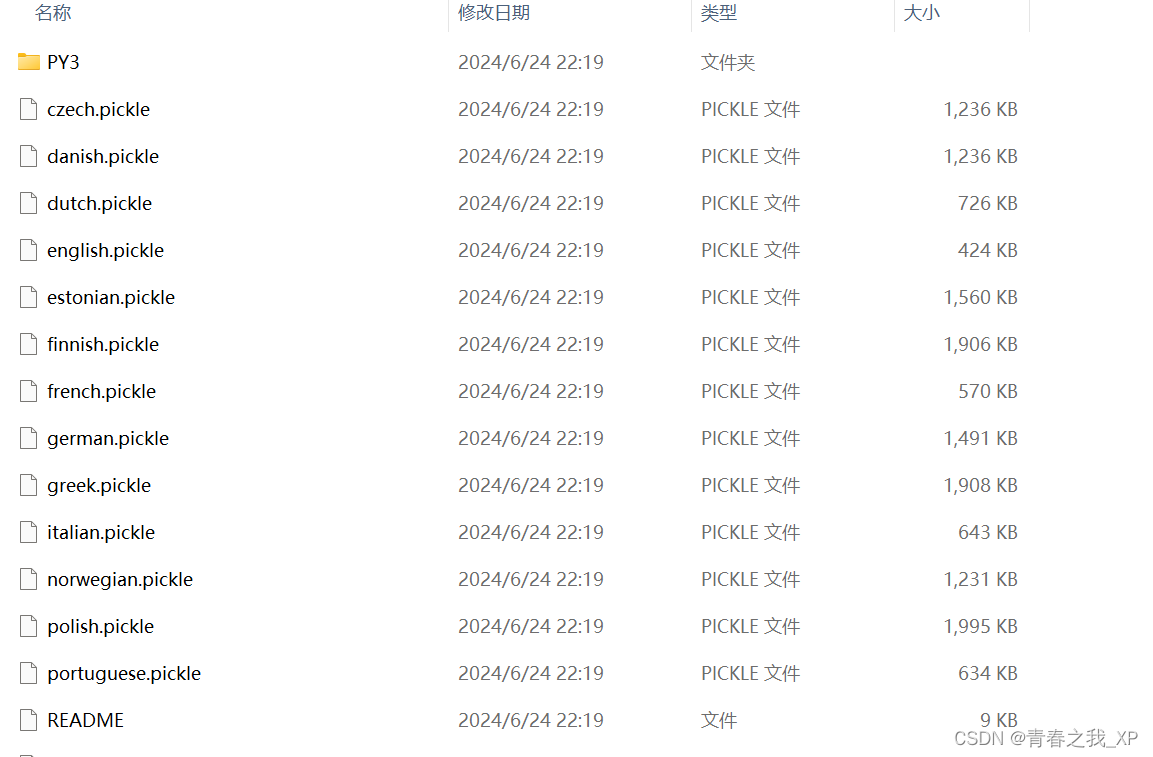
如果打开punkt文件夹,里边还嵌套一个punkt文件夹,再打开第二个punkt文件夹之后才出现上方的界面,这样就需要删除一个punkt文件夹了。也就是避免nltk_data\tokenizers\punkt\punkt的情况出现,理想状态是nltk_data\tokenizers\punkt\

发表评论