方法1(df.append())
import pandas as pd
# 创建一个空的dataframe
df = pd.dataframe(columns=['column1', 'column2'])
# 新增一行数据
data = {'column1': 'value1', 'column2': 'value2'}
df = df.append(data, ignore_index=true)
print(df)
raw_data ={"column1":"adafafa","column2":"123123"}
df = df.append(raw_data,ignore_index=true)
df
可以看到这个pandas的添加行的方式和list也是一样,都是使用append函数,但是有一个问题,就是这个append是要返回值的, 这个倒是和list不同,还有一个区别是就是这个ignore_index的参数,必须得有,否则会报错
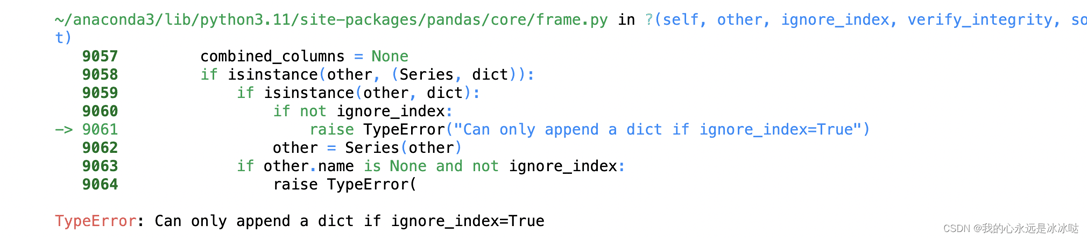
比如下面的例子就会报错
import pandas as pd
# 创建一个空的dataframe
df = pd.dataframe(columns=['column1', 'column2'])
# 新增一行数据
data = {'column1': 'value1', 'column2': 'value2'}
df = df.append(data, ignore_index=true)
print(df)
raw_data ={"column1":"adafafa","column2":"123123"}
df = df.append(raw_data,ignore_index=false)
df
但是值得注意的是,df.append()并非只能添加字典形式的数据,而是能添加dataframe的形式。
但是需要注意这个index的区别,如果设置了ignore_index=true的话,这个index的下标就会被覆盖,而且是从0开始的计数,所以如果要求保留index信息的话,可以选择使用df.concat()
方法2(df.concat())
import pandas as pd
# 创建一个空的dataframe
df1 = pd.dataframe(columns=['column1', 'column2'])
# 新增一行数据
df2 = pd.dataframe(data={'column1': 'value1', 'column2': 'value2'},index=["aaa"])
df3 = pd.dataframe(data={'column1': 'gsgasgag', 'column2': 'bafgdgha'},index=["bbb"])
df = pd.concat([df1,df2])
print(df)
df = pd.concat([df,df3])
df
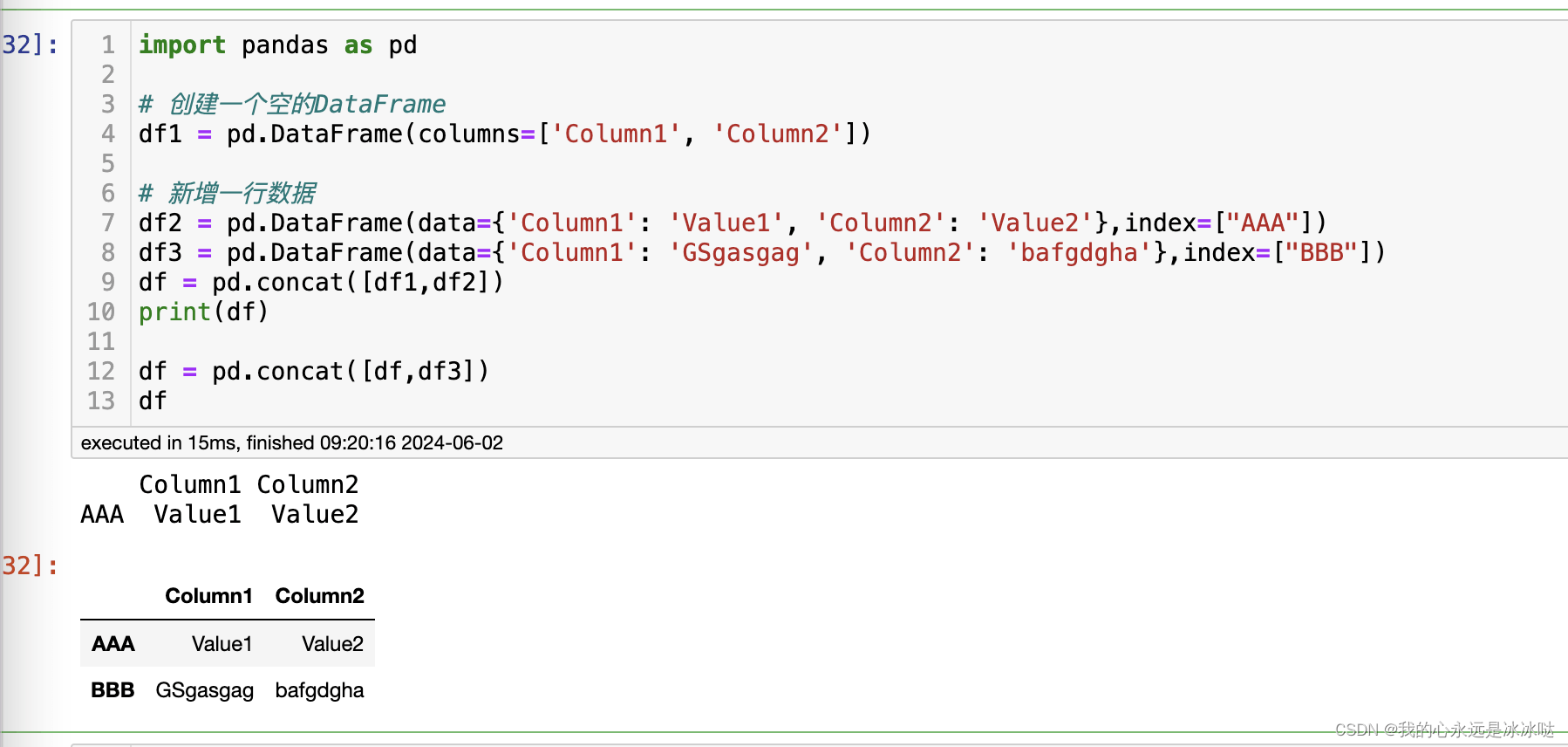
可以看到,这个结果就是很好的
到此这篇关于pandas添加行的两种实现方式的文章就介绍到这了,更多相关pandas添加行内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论