在python的pandas库中,series对象支持多种运算操作,这些包括算术运算、比较运算和逻辑运算等。下面,我将分别演示这些运算的代码示例,并提供相应的场景说明。
1. 算术运算
算术运算包括加、减、乘、除等基本运算。pandas允许对series进行这些运算,同时自动对齐不同series之间的索引。
series长度相同时
示例代码:
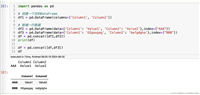
import pandas as pd
# 创建两个series对象
s1 = pd.series([1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.series([4, 5, 6], index=['a', 'b', 'c'])
# 加法运算
result_add = s1 + s2
print("加法结果:\n", result_add)
# 减法运算
result_sub = s1 - s2
print("减法结果:\n", result_sub)
# 乘法运算
result_mul = s1 * s2
print("乘法结果:\n", result_mul)
# 除法运算
result_div = s1 / s2
print("除法结果:\n", result_div)
执行结果:
加法结果:
a 5
b 7
c 9
dtype: int64
减法结果:
a -3
b -3
c -3
dtype: int64
乘法结果:
a 4
b 10
c 18
dtype: int64
除法结果:
a 0.25
b 0.40
c 0.50
dtype: float64
适用场景:
在进行统计分析或数据预处理时,可以用来计算不同数据的总和、差值、产品或商,例如计算总销售额或平均销售额。
series长度不同时
算术运算(加、减、乘、除)在索引不完全对应时,结果的索引将是两个series索引的并集,不存在的索引将填充为nan。
示例代码:
import pandas as pd
# 创建长度不相同的两个series
s1 = pd.series([1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.series([4, 5, 6, 7], index=['b', 'c', 'd', 'e'])
# 加法运算
result_add = s1 + s2
print("加法结果:\n", result_add)
# 乘法运算
result_mul = s1 * s2
print("乘法结果:\n", result_mul)
执行结果:
加法结果:
a nan
b 6.0
c 8.0
d nan
e nan
dtype: float64乘法结果:
a nan
b 8.0
c 15.0
d nan
e nan
dtype: float64
适用场景:
非常适合于金融数据分析中的时间序列数据,因为不同的金融工具可能在不同的时间有交易记录,通过这种方式可以轻松处理数据对齐的问题。
2. 比较运算
比较运算包括等于、不等于、大于、小于等,用于比较series中的元素。
series长度相同时
示例代码:
# 比较运算
result_gt = s1 > s2
print("大于运算结果:\n", result_gt)
result_eq = s1 == s2
print("等于运算结果:\n", result_eq)
执行结果:
大于运算结果:
a false
b false
c false
dtype: bool
等于运算结果:
a false
b false
c false
dtype: bool
适用场景:
在数据筛选过程中,比较运算常用于根据条件过滤数据,例如筛选出所有销量超过某一阈值的记录。
series长度不同时
比较运算(等于、不等于、大于、小于等)在索引不对应时,也会产生nan。
示例代码:
# 等于运算
result_eq = s1 == s2
print("等于运算结果:\n", result_eq)
执行结果:
等于运算结果:
a false
b false
c false
d false
e false
dtype: bool
适用场景:
同样适用于时间序列的数据对齐和比较。例如,用于比较不同时间点的股票价格是否相等。
3. 逻辑运算
series长度相同时
逻辑运算主要是对series中的bool值进行and、or、not运算。
示例代码:
# 创建逻辑运算的series
s3 = pd.series([true, false, true])
s4 = pd.series([false, true, true])
# 逻辑与运算
result_and = s3 & s4
print("与运算结果:\n", result_and)
# 逻辑或运算
result_or = s3 | s4
print("或运算结果:\n", result_or)
执行结果:
与运算结果:
0 false
1 false
2 true
dtype: bool
或运算结果:
0 true
1 true
2 true
dtype: bool
适用场景:
在处理多个条件筛选的情况下,例如同时满足多个条件或至少满足一个条件的数据筛选处理。
series长度不同时
逻辑运算(与、或、非)同样会出现nan,因为布尔逻辑运算在涉及nan时的结果也是nan。
示例代码:
# 创建逻辑数据series
s3 = pd.series([true, false, true], index=['a', 'b', 'c'])
s4 = pd.series([false, true, true, false], index=['b', 'c', 'd', 'e'])
# 逻辑与运算
result_and = s3 & s4
print("与运算结果:\n", result_and)
# 逻辑或运算
result_or = s3 | s4
print("或运算结果:\n", result_or)
执行结果:
与运算结果:
a false
b false
c true
d false
e false
dtype: bool或运算结果:
a true
b true
c trued true
e false
dtype: bool
适用场景:
逻辑运算通常用于处理资料筛选。在实际的数据处理过程中,例如在处理用户行为数据时,可能需要根据多个时间点的行为数据来确定用户的最终行为倾向,逻辑运算可以用来组合不同时间点的条件。
总结
对于长度不同的series进行计算时,pandas的处理方式是非常智能的,它通过自动对齐索引并用nan填充缺失值,保证了计算的可行性和结果的准确性。这使得pandas在处理实际工作中遇到的不规则数据时显得格外强大和灵活。
- 在金融分析中,经常需要对齐交易数据,比如股票的日交易数据,尤其是在合并多个股票数据进行比较时。
- 在科研数据处理中,例如生物信息学或气象数据分析,数据的时间点可能不完全一致,此时这种对齐方式极为重要。
- 在商业智能中,处理销售数据或用户行为数据时,需要对产品线不同阶段的数据进行整合分析。
pandas通过这种灵活的数据处理方式,极大地简化了数据预处理的复杂度,使得数据分析师可以更加专注于数据分析本身,而不是花费大量时间处理数据对齐和缺失问题。
到此这篇关于pandas中series运算汇总(算术、比较和逻辑运算)的文章就介绍到这了,更多相关pandas series运算内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论