一,mongodb数据性能测试
之前公司将用户的游戏数据存储在mysql中,就是直接将json数据存储到mysql数据库里面,几个月不到,数据库里面已经有两亿条数据,而且每行中每个json数据量也比较大,导致占用的磁盘容量也比较大,因此为了解决mysql带来多方面的瓶颈,最终选择使用mongodb来代替mysql。为了测试mongodbdb的性能以及是否满足需求,因此做了以下测试,对mongodb在高流量时验证其增删改查的效率,以及对其进行压测
服务器配置:2核4g轻量级服务器 磁盘容量 70gb
每条数据大概在500个字节,索引有一个id主键索引,还有一个parentid和category的联合唯一索引,这里两个字段能保证唯一性,因此用唯一索引效率更优
1,mongodb数据库创建和索引设置
首先在java代码中创建一个实体类,用这个类作为json对象插入到文档中即可。
@data
public class archive {
private string id;
//账号id
private string parentid;
private string category;
private string content;
}
随后在mongodb中创建一个数据库,然后再该库下面建立一个名为 archive 的集合,mongodb的集合就是类似于mysql的表,两者概念是一样的。由于后期数据量可能非常大,因此根据mongodb官方文档所说,在数据插入前,尽量提前建立索引,为了满足业务需求,这里选择创建一个联合索引,由于我这边业务能保证要加索引的两个字段的唯一性,因此选择直接添加唯一索引
db.users.createindex({parentid: 1,category:1}, {unique: true})
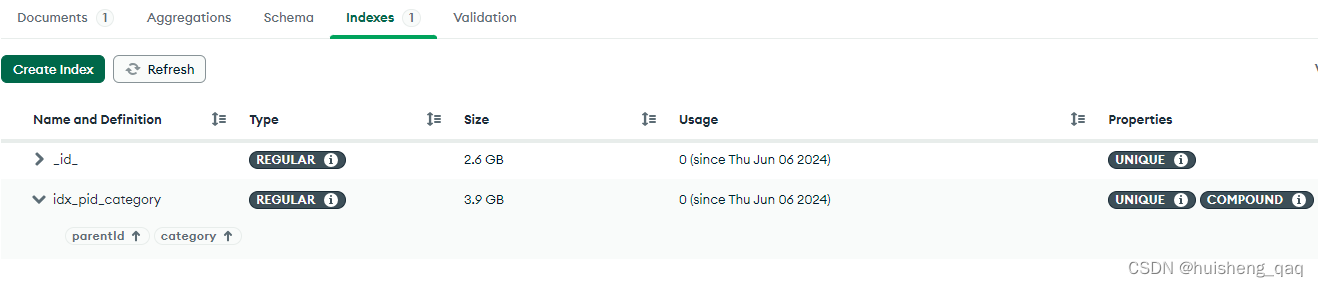
如果navicate操作不方便的话,可以安装一个 mongodb compass 可视化工具,如下图,很多操作都是可以在这个可视化图形界面上面直接操作的
2,线程池+批量方式插入数据
由于这边主要是io操作将数据插入,不需要计算之类的,因此选择使用io密集型线程池,接下来自定义一个线程池
@slf4j
public class threadpoolutil {
public static threadpoolexecutor pool = null;
public static synchronized threadpoolexecutor getthreadpool() {
if (pool == null) {
//获取当前机器的cpu
int cpunum = runtime.getruntime().availableprocessors();
int maximumpoolsize = cpunum * 2 ;
pool = new threadpoolexecutor(
maximumpoolsize - 2,
maximumpoolsize,
5l, //5s
timeunit.seconds,
new linkedblockingqueue<>(), //数组有界队列
executors.defaultthreadfactory(), //默认的线程工厂
new threadpoolexecutor.abortpolicy()); //直接抛异常,默认异常
}
return pool;
}
}
第二步就是定义一个线程任务,到时将任务丢到线程池里面,其代码如下,该任务实现callable接口,每个线程插入10万条,每次批量插入100条数据,大概就是需要1000次
@data
public class archivetask implements callable {
private mongotemplate mongotemplate;
public archivetask(mongotemplate mongotemplate){
this.mongotemplate = mongotemplate;
}
@override
public object call() throws exception {
list<archive> list = new arraylist<>();
for (int i = 1; i <= 100000; i++) {
archive archive = new archive();
archive.setcategory("score");
archive.setid(snowflakeutils.nextorderid());
archive.setparentid(snowflakeutils.nextorderid());
map<string,string> map = new hashmap<>();
stringbuilder sb = new stringbuilder();
for (int j = 0; j < 15; j++) {
sb.append(uuid.randomuuid());
}
map.put("key" + i, sb.tostring());
archive.setcontent(json.tojsonstring(map));
list.add(archive);
if (i%100 == 0){
mongotemplate.insertall(list);
list.clear(); //手动gc,100个对象没被引用会被回收
list = new arraylist<>();
}
}
return null;
}
}
最后定义一个测试类或者一个接口,我这边使用接口,部分代码如下,循环100次,就是会创建100个线程任务,随后将这个线程任务丢到线程池中,100乘以100000就是1千万条数据
@resource
private mongotemplate mongotemplate;
static threadpoolexecutor threadpool = threadpoolutil.getthreadpool();
@getmapping("/add")
public void test(){
for (int i = 0; i < 100; i++) {
archivetask archivetask = new archivetask(mongotemplate);
threadpool.submit(archivetask);
}
log.info("数据添加完成");
}
3,一千万数据性能测试
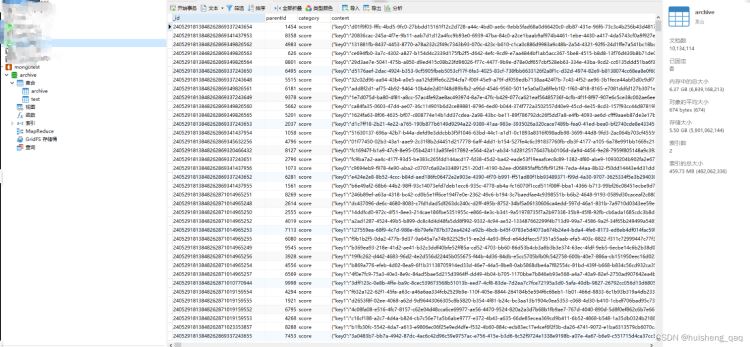
mongodb性能测试,此时archive 集合中已有10134114条数据,平均每条数据大小674字节,1千多万条,此时的存储大小为5.5个g,索引的总大小为459m
接下来通过唯一索引查询一条数据,这里直接通过parentid查询一条数据,此时数据还是在不断插入的
db.archive.find({parentid:"2405291858848274156091867143"})
是的,如下图所示,1000多万条数据里面查询,只需要25ms即可将数据放回,当然这里没有在高流量的情况下进行压测。
4,两千万数据性能测试
此时archive集合来到了两千万条,每条数据和之前一样,平均大小是674字节,数据总大小来到了10.92g,内存大小12.65g,索引总大小是913m
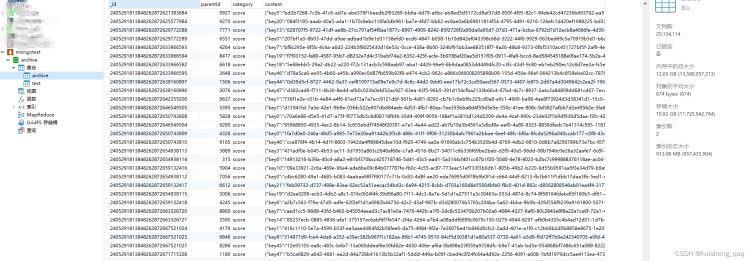
接下来测试查询效率,依旧使用上面的这个parentid,由于设置的是parentid+category的联合唯一索引,接下来两个参数一起查
db.archive.find({parentid:"2405291858848274156091867143",category:"score"})
2000万的数据查询结果如下,只需要21ms,和上面的25ms慢了将近4ms,但是这4ms可以忽略

5,五千万数据性能测试
由于70g的磁盘容量已经只剩48g,因此在content字段将500字节的值调小,调整到150个字节,以便能插入更多数据。将上面的stringbuilder拼接的15个uuid改成1个uuid
map.put("key" + i,uuid.randomuuid().tostring());
此时数据来到50245694条数据,每条数据平均大小372kb,总存储大小12.66g,内存中的总大小17.45g,索引大小目前只有2.8g
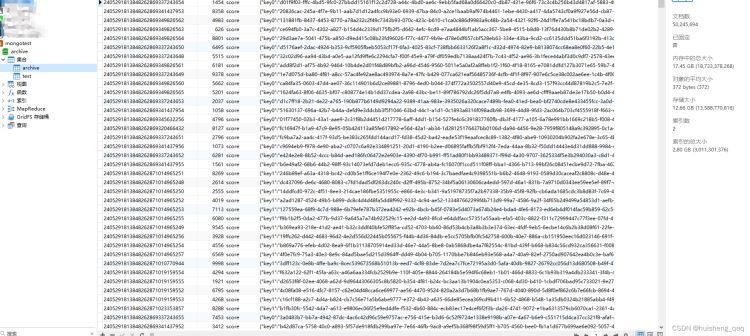
为了保证拿到的parentid是一次没有查询过的,手动的插入一批数据,手动单条插入20条数据,耗时600ms,在插入数据时会改变索引,插入数据会稍微慢些。此时的插入操作都是在多线程插入大量数据的时候测试的
db.archive.insertone({parentid:"2024111222337",category:"score1",content:"cbasbsadhpasdbsaodgs"})
db.archive.insertone({parentid:"2024111222337",category:"score2",content:"cbasbsadhpasdbsaodgs"})
....
此时第一次查询这条数据,共耗时153ms,共查出20条数据
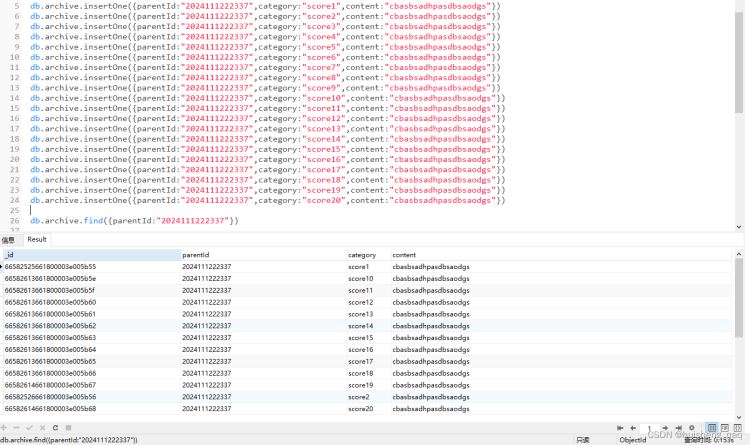
再第二次查询之后,花费78ms,内部应该也是会将查询结果加入到缓存中,方便第二次查询

在上面的插入操作中由于会破坏到索引结构,因此耗时久一点。接下来看这个更新操作,
db.archive.updateone(
{ parentid: "2024111222337",category:"score1" },
{ $set: { content: "cbasbsadhpasdbsaodgsscore" } }
);
其结果如下,更新了一条数据,只花费了13毫秒的时间,因此更新操作速度是很快的。由于这里每一条数据都是唯一数据,因此不测试批量更新

最后测试删除数据,将这20条数据全部删除,总共花费18毫秒

6,一亿条数据性能测试
数据通过多线程+批量插入的方式来到一亿条,存储大小15.5g,索引长度是6g
db.archive.countdocuments() //查询共有多少条数据 100082694
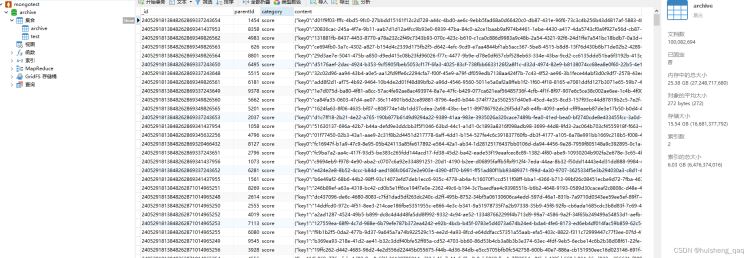
接下来往里面重新插入一部分数据,往里面插入20条数据,大概花费160多ms,插入数据会导致索引重构,所以耗时久一些,批量插入性能会更快。重新插入的数据可以保证这条数据没被查过,并且知道parentid是什么
db.archive.insertone({parentid:"20240531101059",category:"score1",content:"abcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxy"})
....
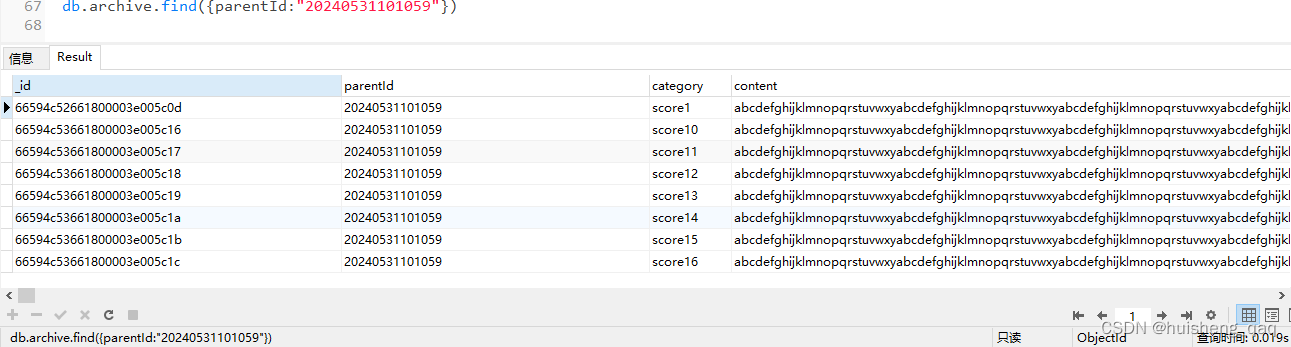
接下来测试查询数据,只需要19ms
db.archive.find({parentid:"20240531101054"},{parentid:1,category:1}) //只返回部分字段
db.archive.find({parentid:"20240531101058"})
更新数据如下,只需要10ms
db.archive.updateone(
{ parentid: "20240531101059",category:"score1" },
{ $set: { content: "cbasbsadhpasdbsaodgsscore" } }
);
7,压测
以下压测都是数据达到1亿之后进行测试的,并且都是使用的2核4g的服务器
在1s内同时1000个线程插入数据,每个线程插入20条数据,中位数24,吞吐量391

在1s内10000个线程插入数据,也是每个线程批量插入20条数据,可以发现就算是2核4g这么垃圾的轻量级服务器,10000qps也是毫无压力的

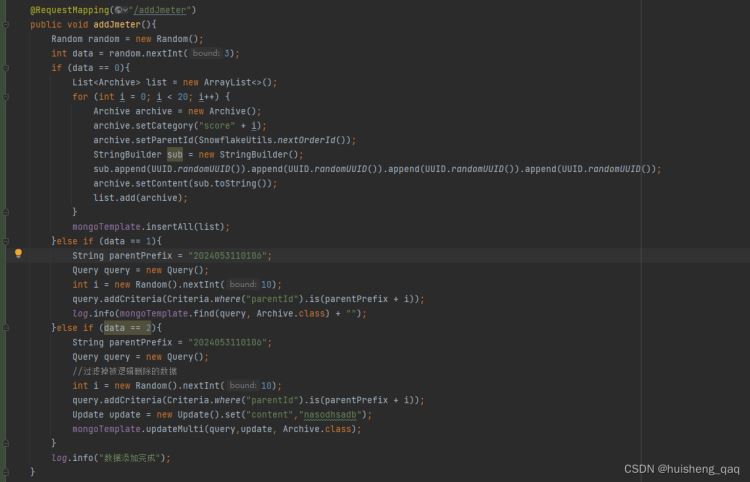
插入数据会破坏索引,相对于修改和查询是更慢的,接下来测试1s内10000个线程同时执行增改查,吞吐量可以达到2251.7

部分代码片段如下,让10000个线程随机的执行增改查的操作,在1s内是毫无压力的
8,总结
通过上面的数据以及mongodb的响应来看,mongodb的性能还是非常不错的。看看gpt对这种数据的评价,gpt也认为mongodb是非常合适的。当然不管什么数据和业务,只要其本质是 json 数据,不管json内部结构多复杂,用mongodb都是非常合适的。mongodb还适合存一些订单数据,地理数据,大数据等等,其应用范围是非常广泛的

以上就是mongodb亿级数据性能测试和压测的详细内容,更多关于mongodb数据性能测试的资料请关注代码网其它相关文章!






发表评论