我发现4090这款显卡的边际效应相当明显,这一发现让我颇感意外。
在gpu这种超大规模并行计算领域,最能突显性能差距的无疑是gpu渲染或计算能力,因为这类运算完全依赖于gpu,几乎不受其他因素的影响。
我特地从oc渲染的benchmark天梯榜上搜集了40系显卡的成绩数据(未开启rt),并进行了深入分析。
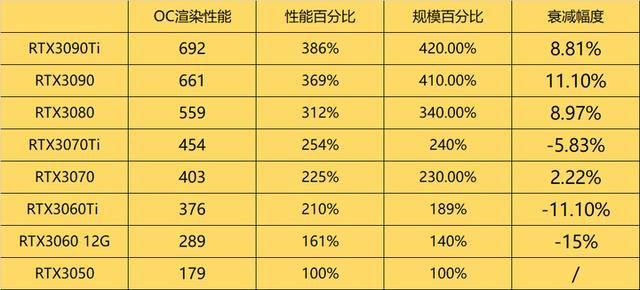
这份数据结果真的让我大吃一惊,4090的渲染性能竟然只比4070高出将近两倍。要知道,在以往的显卡评测中,这种情况可是从未出现过的。毕竟,4090的规模几乎是4070的三倍,但渲染性能却只高出两倍。
我仔细计算了相对衰减幅度,并据此推测,显存带宽可能是rtx40系显卡的一个主要瓶颈。可以说,显存设置上的吝啬可能限制了rtx40系显卡发挥出其应有的性能。
4060ti 8g就是一个典型的例子。尽管它的流处理器数量比4060多了41.67%,但由于显存带宽仅略高于4060,其最终渲染性能的提升幅度也仅有13.6%。
相比之下,4070在流处理器规模仅比4060ti多出35.3%的情况下,其渲染性能却强出了57.56%。这得益于4070的显存配置——192bit 21gbps,最终带宽达到了504gb/s,比4060ti的288gb/s高出了75%。
我记得在rtx30系显卡的时代,我们在进行oc渲染时并没有特别关注显存带宽这个因素。
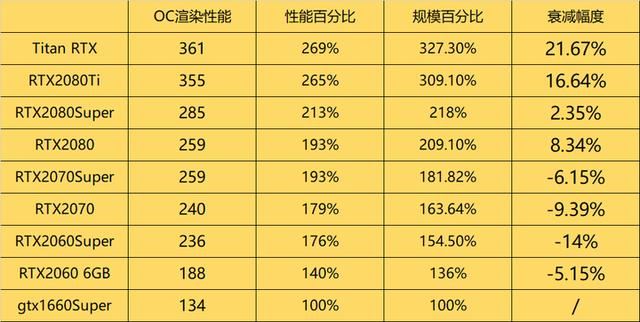
rtx30系的衰减情况可以说是微乎其微,显存带宽问题并没有那么突出。因此,以前我们在评估gpu渲染性能时,通常会将渲染性能与显卡规模直接挂钩。
再来看一下rtx20系的情况。
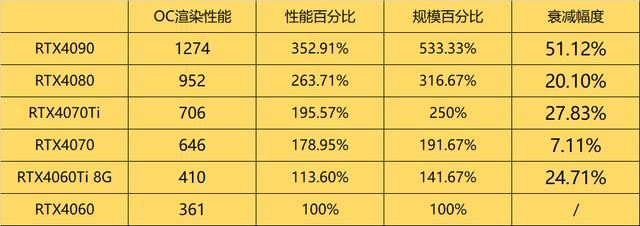
在gddr6显存还未普及的时代,只有高端显卡的衰减情况较为明显。因此,我们有理由相信,rtx40系高端显卡的瓶颈已经变得相当显著,甚至在gpu渲染用途上已经开始出现明显的性能衰减。
对于rtx4090渲染性能仅有4070两倍不到这个问题,我严重怀疑显存带宽是一个重要的制约因素。这可能与gddr7显存的缺失有关。
另一方面,我也对ada lovelace架构的边际效应问题产生了怀疑。从目前已知的信息来看,ada lovelace架构相较于30系的ampere架构,除了加入了一些新特性(如第四代tensor core、第三代rt core以及光流加速器、大l2等)外,主要就是换用了台积电4n工艺,扩大了规模并提高了频率。
然而,ad102核心的流处理器数量相较于ga102有了巨大的增长,但显存带宽却保持不变,都是1008gb/s。这意味着单个sm的光栅渲染性能提升可能主要来自于频率的提高,这可能会导致在超大规模下gpu的并行效率下降。
也许在下一代gpu中,随着架构的改进和gddr7显存的采用,我们才能看到这种规模的gpu应有的实力。
至于游戏方面,由于游戏性能还受到cpu和内存等其他因素的影响,因此性能差距可能会进一步缩小。

发表评论