行索引、列索引、loc和iloc
import pandas as pd
import numpy as np
# 准备数据
df = pd.dataframe(np.arange(12).reshape(3,4),index=list("abc"),columns=list("wxyz"))
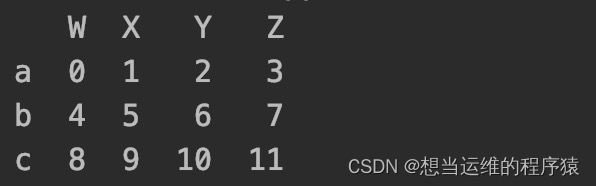
行索引(index):对应最左边那一竖列
列索引(columns):对应最上面那一横行
.loc[]官方释义: access a group of rows and columns by label(s) or a boolean array.(通过标签或布尔数组访问一组行和列) 官方链接
- loc使用索引来取值,基础用法 df.loc[[行索引],[列索引]]
.iloc[]官方释义: purely integer-location based indexing for selection by position.(按位置进行索引选择) 官方链接
- iloc使用位置(从0开始)来取值,基础用法 df.iloc[[行位置],[列位置]]
一、根据列索引取某一列/多列(常用)
df['w'] # 取‘w'列,返回类型是series df[['w']] # 取‘w'列,返回类型是dataframe df[['w','y']] # 取‘w'列和‘y'列 df.loc[:,'w':'y'] # 取‘w'列到‘y'列
二、根据行索引取某一行/多行
df.loc['a'] # 取‘a'行,返回类型是series df.loc[['a']] # 取‘a'行,返回类型是dataframe df.loc[['a','c']] # 取‘a'行和‘c'行,也可以写成 df.loc[['a','c'],:] df.loc['a':'c',:] # 取‘a'行到‘c'行
三、根据列位置取某一列/多列
df.iloc[:,1] # 取第2列(‘x'列),列号为1,返回类型是series df.iloc[:,0:2] # 取前2列(‘w'列和‘x'列),列号为0和1 df.iloc[:,0:-1] # 取最后一列之前的所有列
四、根据行位置取某一行/多行(常用)
df[:2] #取前2行,行号为0和1 df[1:2] #取第2行,行号为1 df.iloc[1] # 取第2行(‘b'行),行号为1,返回类型是series,也可以写成df.iloc[1,:]
五、取某一行某一列(常用)
df.loc[['b'],['w']] # 取‘b'行‘w'列,返回类型是dataframe,带着行、列索引的 df.loc['b','w'] # 取‘b'行‘w'列的值,返回类型是int,不带行列索引 df.loc['b']['w'] # 取‘b'行‘w'列的值(从series类型df.loc['b']中通过索引取值) df.iloc[[0],[0]] # 取第1行、第1列,返回类型是dataframe,带着行、列索引的 df.iloc[0,0] # 取第1行、第1列的值 df.iloc[0][0] # 取第1行、第1列的值(从series类型df.iloc[0]中通过序号取值) df.iloc[0]['w'] # 取第1行、‘w'列的值(从series类型df.iloc[0]中通过索引取值)
六、取多行多列
df[:2][['w','y']] # 取前2行的‘w'列和'y‘列 df[:2].loc[:2,'w':'y'] # 取前2行的‘w'列到'y‘列 df.iloc[0][['w','y']] # 取第1行的‘w'列和'y‘列 df.iloc[0]['w':'y'] # 取第1行的‘w'列到'y‘列 df.loc[["a","c"],["w","y"]] # 取‘a'行和‘c'行,‘w'列和‘y'列 df.iloc[[0,2],[1,3]] # 取1、3行,2、4列
总结: 一般通过行位置来取行,通过列索引来取列,且行索引大多数情况下和行位置是相同的。
最常用的是以下几个
# 取某一列 df['w'] # 取某一行 df.iloc[0] # 取多列 df.loc[:,'w':'y'] # 取‘w'列到‘y'列 df.iloc[:,0:-1] # 取最后一列之前的所有列 # 取对应行列的值 df.iloc[0]['w'] df.loc['a','w'] # 在行索引和行位置相同的情况下的写法就是,df.loc[0,'w']
到此这篇关于python读取dataframe的某行或某列的方法实现的文章就介绍到这了,更多相关python读取dataframe行列内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论