前言
什么是正则表达式?
正则表达式(regular expression,通常简写为regex、regexp或re)是一种强大的文本处理工具,它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为“元字符”)组成的文字模式。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
例如,在python中,可以使用re模块来使用正则表达式。正则表达式的主要应用包括:数据验证、搜索和替换操作等。例如,你可以使用正则表达式来验证一个字符串是否为有效的电子邮件地址,或者在一个大的文本文件中查找所有符合特定模式的字符串并进行替换。
正则表达式的优点在于其灵活性和强大性,能够处理各种复杂的文本匹配和替换任务。然而,其复杂性也使得学习和使用它具有一定的难度。需要掌握正则表达式的基本语法和常用元字符,才能有效地利用它来处理文本数据。
常见正则表达式元字符表
匹配字符
普通字符:大部分字符,如 a, b, 1, 2 等,匹配它们自身。
转义字符:\ 用于引入特殊字符或转义序列。
\n:换行符\t:制表符\\:反斜杠字符本身\r:回车符\f:换页符\v:垂直制表符\uxxxx:其中 xxxx 是 4 位十六进制数,表示 unicode 字符\xhh:其中 hh 是 2 位十六进制数,表示字符
字符类:[] 用于定义字符集。
[abc]:匹配a、b或c中的任意一个字符[^abc]:匹配除了a、b或c之外的任意一个字符[a-z]:匹配任意小写字母[a-z]:匹配任意大写字母[0-9]:匹配任意数字[a-za-z0-9]:匹配任意字母或数字
元字符
.:匹配除了换行符之外的任意单个字符。
*:匹配前面的子表达式零次或多次。
+:匹配前面的子表达式一次或多次。
?:匹配前面的子表达式零次或一次。
{n}:匹配前面的子表达式恰好 n 次。
{n,}:匹配前面的子表达式至少 n 次。
{n,m}:匹配前面的子表达式至少 n 次,但不超过 m 次。
^:匹配输入字符串的开始位置。
$:匹配输入字符串的结束位置。
\b:匹配一个单词边界。
\b:匹配非单词边界。
\d:匹配一个数字字符,等价于 [0-9]。
\d:匹配一个非数字字符,等价于 [^0-9]。
\w:匹配任何单词字符,等价于 [a-za-z0-9_]。
\w:匹配任何非单词字符,等价于 [^a-za-z0-9_]。
\s:匹配任何空白字符,包括空格、制表符、换页符等。
\s:匹配任何非空白字符。
特定构造
分组与捕获:() 用于将多个项组合成一个单元,并可以记住匹配的文本供以后引用。
\1,\2, ...:引用之前捕获的分组。
选择:| 用于分隔多个可能的匹配项。
a|b:匹配a或b。
非捕获分组:(?:...) 匹配 ... 但不捕获匹配的文本。
前瞻断言:
(?=...):正向前瞻断言,要求接下来的字符与 ... 匹配,但不消耗字符。(?!...):负向前瞻断言,要求接下来的字符不与 ... 匹配。
后顾断言:
(?<=...):正向后顾断言,要求前面的字符与 ... 匹配,但不消耗字符(注意:不是所有正则表达式引擎都支持后顾断言)。(?<!...):负向后顾断言,要求前面的字符不与 ... 匹配。
回退引用:\n,其中 n 是一个数字,用于引用之前捕获的分组内容。
量词修饰符:
*?、+?、{n}?、{n,}?、{n,m}?:非贪婪量词,匹配尽可能少的字符。
边界匹配:除了 \b 和 \b,还有一些其他的边界匹配字符。
条件表达式:`(?(condition)yes-pattern|no-
python常用的re正则匹配函数库
python 的 re 模块提供了对正则表达式(regular expressions)的支持,允许你进行文本匹配和搜索操作。以下是 re 模块中常用的一些函数和它们的功能:
1. re.match(pattern, string)
- 功能:从字符串的开头匹配模式。
- 返回值:如果匹配成功,返回一个匹配对象;否则返回
none。
import re result = re.match(r'hello', 'hello, world!') print(result.group()) # 输出: hello
2. re.search(pattern, string)
- 功能:在字符串中搜索模式,返回第一个匹配的对象。
- 返回值:如果匹配成功,返回一个匹配对象;否则返回
none。
result = re.search(r'world', 'hello, world!') print(result.group()) # 输出: world
3. re.findall(pattern, string)
- 功能:查找字符串中所有匹配的子串。
- 返回值:返回一个包含所有匹配子串的列表。
result = re.findall(r'\w+', 'hello, world!') print(result) # 输出: ['hello', 'world']
4. re.finditer(pattern, string)
- 功能:查找字符串中所有匹配的子串,返回一个迭代器。
- 返回值:返回一个迭代器,每次迭代返回一个匹配对象。
for match in re.finditer(r'\w+', 'hello, world!'):
print(match.group()) # 输出: hello 和 world
5. re.split(pattern, string)
- 功能:根据模式分割字符串。
- 返回值:返回一个分割后的字符串列表。
result = re.split(r',\s*', 'hello, world,python,programming') print(result) # 输出: ['hello', 'world', 'python', 'programming']
6. re.sub(pattern, repl, string)
- 功能:替换字符串中的匹配项。
- 返回值:返回替换后的字符串。
result = re.sub(r'\s+', '-', 'hello world') print(result) # 输出: hello-world
7. re.compile(pattern)
- 功能:编译正则表达式,生成一个正则表达式对象。
- 返回值:返回一个正则表达式对象,可以用于后续的匹配操作。
pattern = re.compile(r'\d+')
result = pattern.findall('the price is 20 dollars.')
print(result) # 输出: ['20']
8. 匹配对象方法
match.group(): 返回匹配的字符串。match.start(): 返回匹配的开始位置。match.end(): 返回匹配的结束位置。match.span(): 返回一个元组,包含匹配的 (开始, 结束) 位置。
这些只是 re 模块中常用的一些函数和方法。正则表达式在实际使用中非常强大,能够进行复杂的模式匹配和替换操作。不过,编写和理解复杂的正则表达式需要一些练习和经验。
运用正则表达式生成随机密码案列
re.compile(pattern) 函数用于编译正则表达式,生成一个正则表达式对象。这个对象可以用于后续的匹配操作。下面详细介绍该函数的参数、功能以及如何使用它来生成满足特定条件的密码。
密码要求:
- 至少一个数字:
\d - 至少一个字母(大小写不限):
[a-za-z] - 至少一个特殊符号(例如
!@#$%^&*()-_+=等):[!@#$%^&*()\-_=+] - 密码长度至少8位:
{8,}
根据条件组合在一起,我们得到的正则表达式为:
pattern = r'^(?=.*\d)(?=.*[a-za-z])(?=.*[!@#$%^&*()\-_=+]).{8,}$'解释一下这个正则表达式:
^: 表示字符串的开始。(?=.*\d): 表示后面跟着至少一个数字。(?=.*[a-za-z]): 表示后面跟着至少一个字母。(?=.*[!@#$%^&*()\-_=+]): 表示后面跟着至少一个特殊符号。.{8,}: 表示任意字符,至少8位。$: 表示字符串的结束。
接下来,我们使用 re.compile() 编译这个正则表达式,并使用 search() 方法来生成满足条件的密码。
random.choice(string.ascii_letters + string.digits + '!@#$%^&*()\-_=+')用于生成随机字符。pattern.search(password)用于检查密码是否符合正则表达式。generate_password()函数将生成满足条件的密码,并返回该密码。
实现代码如下:
import re
import random
import string
def generate_password():
pattern = re.compile(r'^(?=.*\d)(?=.*[a-za-z])(?=.*[!@#$%^&*()\-_=+]).{8,}$')
while true:
# 生成随机密码,包含数字、字母和特殊符号
password = ''.join(random.choice(string.ascii_letters + string.digits + '!@#$%^&*()\-_=+') for _ in range(12))
# 检查密码是否符合正则表达式
if pattern.search(password):
return password
# 生成密码
password = generate_password()
print(password)
print("生成的密码:", password)生成结果:
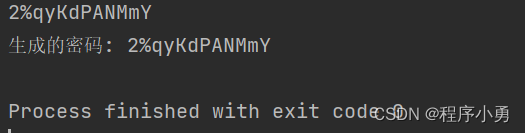
到此这篇关于python中re正则匹配数据的实现的文章就介绍到这了,更多相关python re正则匹配内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论