前言
为了后续能更好的讲解redis的各种数据类型,我们需要学习一点前置知识。
数据类型
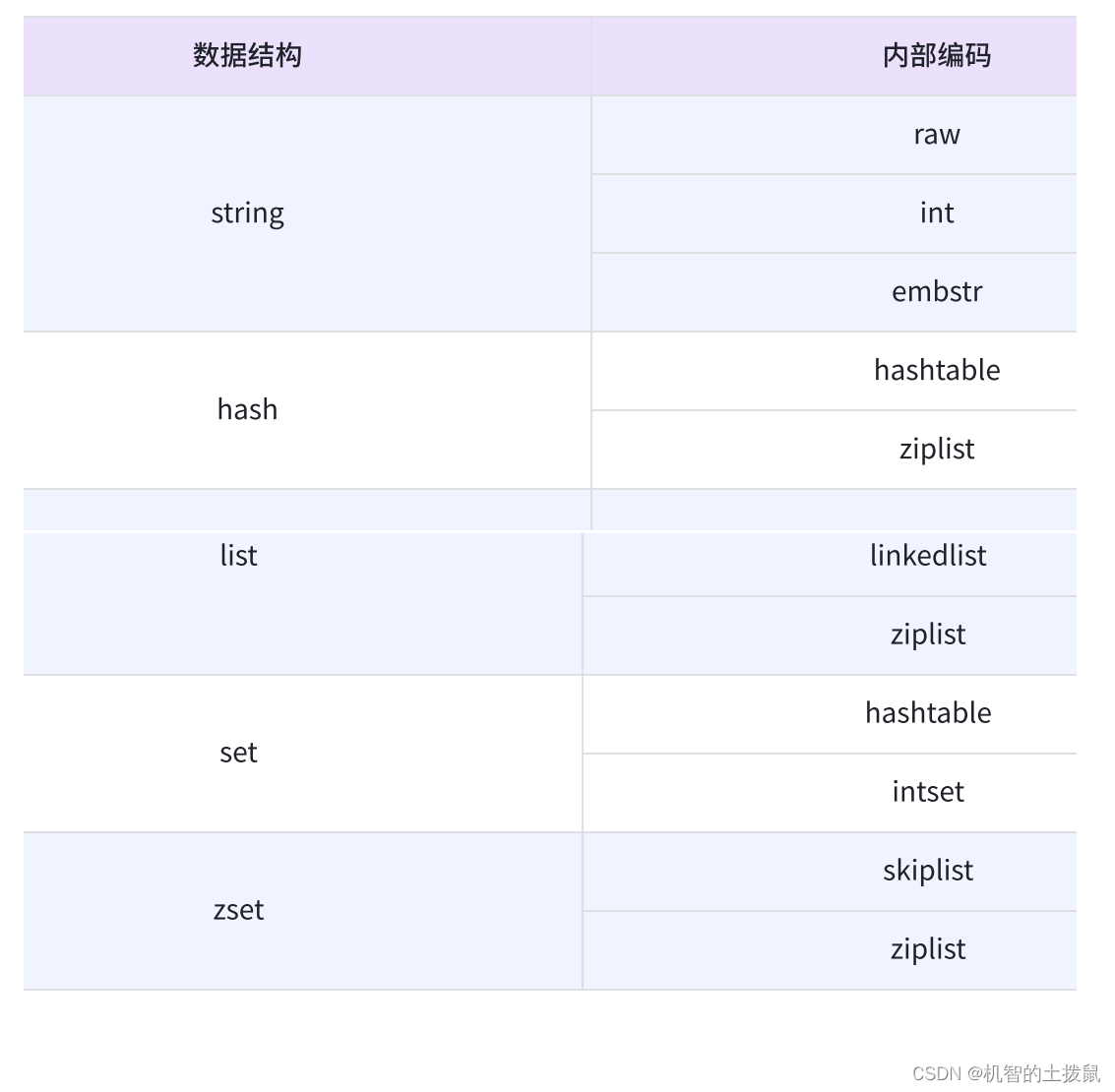
redis是通过key-value的形式来组织数据的,而key的类型都是string,而value的类型可以有很多。
在redis中最通用的数据类型大致有这几种:string、list、set、hash、sorted set。
不过,redis底层在实现这些数据结构(类型)的时候,会在源码层面进行优化,以达到节省时间/节省空间的效果,而对于内部数据结构也称之为内部编码。
ps:有点指鹿为马的感觉。redis告诉你,我的类型就是一个字符串,但自己背后却给优化成了整形,指着整形说是字符串,然后咱也只能老老实实用~
string
在string类型中有三种内部编码方式:raw、int、embstr。
raw:最基本的字符串,底层就类似是java中的byte数组。
int:在特定场景下,会优化成整数,方便进行数值计算。
embstr:针对短字符串进行的优化。
hash
在hash类型中有两种内部编码方式:hashtable、ziplist。
hashtable:最基本的哈希表(不同于java标准库中的hashtable)。
ziplist:压缩列表,当哈希表中的元素比较少的时候,就进行了优化,节省空间。
list
在list类型中有两种内部编码方式:linkedlist、ziplist。
linkedlist:链表的形式
ziplist:压缩列表
不过从redis3.2开始,就引入了新的实现方式:quicklist。
quicklist:集成了链表和压缩列表的优势。本质上就是一个链表,而每个元素又是一个压缩列表。当元素很多的时候,如果全是链表,就会出现很多节点,而每个节点都需要使用指针域,这也会大大增加开销。
set
在set类型中有两种内部编码方式:hashtable、intset。
intset:存储的都是整数的集合。
zset
在set类型中有两种内部编码方式:skiplist、ziplist。
skiplist:跳表,跳表也是链表,不同于普通链表的是,跳表的每个节点上有很多指针域,巧妙利用这个特性,查询速度能调高到o(logn).
查询内部编码方式指令
#基本语法 object encoding key #查询key的内部编码
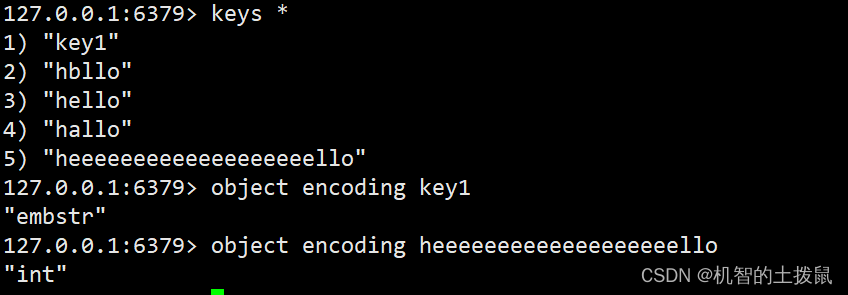
redis会自动根据当前的实际情况选择内部的编码方式~~真香!
redis的单线程模型
此处的单线程模型并非是真的说在redis内部只有一个线程在工作,说的是redis只用一个线程来处理命令请求,在redis内部还有其他一些线程是用来处理网络io的,毕竟是作为一个服务器来使用的~~
正是由于redis的单线程模型,以至于当多个客户端并发的对redis服务器进行操作的时候,不会有线程安全的问题,多个请求来的时候就使用放到一个队列里,串行的去处理里面的命令。而且redis的主要核心业务逻辑也都是一些“短频快”的操作,不太消耗cpu,所以单线程模型才能很好的工作,但也有弊端:当一个指令执行的时间太长,就会阻塞其他指令!!!
面试题:
redis虽然是单线程模型,为啥效率这么高呢?
1.redis访问的是内存中的数据,相较于数据库访问的是硬盘数据,会快很多。
2.redis的核心功能,比数据库简单(数据库支持各种各样的约束,功能很强大,势必会带来更多开销)。
3.单线程模型避免了一些不必要的线程竞争开销。
4.处理网络io的时候,使用了epoll这样的io多路复用机制。
到此这篇关于redis的数据类型和内部编码的文章就介绍到这了,更多相关redis数据类型和内部编码内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论