概述
nvidia-docker 和 nvidia-container-runtime 是用于在 nvidia gpu 上运行 docker 容器的两个相关工具。它们的作用是提供 docker 容器与 gpu 加速硬件的集成支持,使容器中的应用程序能够充分利用 gpu 资源。
nvidia-docker
为了提高 nvidia gpu 在 docker 中的易用性, nvidia 通过对原生 docker 的封装提供了 nvidia-docker 工具
nvidia-docker 是一个 docker 插件,用于在 docker 容器中启用 nvidia gpu 支持。
该工具提供了一个命令行界面,允许在运行容器时通过简单的命令来指定容器是否应该访问主机上的 nvidia gpu 资源。
当在容器中运行需要 gpu 加速的应用程序时,可以使用 nvidia-docker 来确保容器能够访问 gpu。
# 示例命令 nvidia-docker run -it --rm nvidia/cuda:11.0-base nvidia-smi
上述命令使用 nvidia-docker 在容器中运行 nvidia 的 cuda 基础镜像,并在容器中执行 nvidia-smi 命令以查看 gpu 信息
nvidia-container-runtime
nvidia-container-runtime 是 nvidia 的容器运行时,它与 docker 和其他容器运行时(如 containerd)集成,以便容器可以透明地访问 nvidia gpu 资源。
与 nvidia-docker 不同,nvidia-container-runtime 不是 docker 插件,而是一种更通用的容器运行时,可与多个容器管理工具集成。
nvidia-docker 和 nvidia-container-runtime 都是用于使 docker 容器能够访问 nvidia gpu 资源的工具。可以根据自己的需求选择其中一个来配置容器以利用 gpu 加速。
需要注意的是,最新的 nvidia docker 支持通常建议使用 nvidia-container-runtime,因为它提供了更灵活和通用的 gpu 支持,而不仅仅是为 docker 定制的解决方案。
# 示例命令 docker run --runtime=nvidia -it --rm nvidia/cuda:11.0-base nvidia-smi
上述命令使用 docker 运行容器,通过 --runtime=nvidia 参数指定使用 nvidia-container-runtime 运行时,并在容器中执行 nvidia-smi 命令。
原生 docker 通过设备挂载和磁盘挂载的方式支持访问 gpu 资源
docker 本身并不原生支持 gpu,但使用 docker 的现有功能可以对 gpu 的使用进行支持
# 示例命令 docker run \ --device /dev/nvidia0:/dev/nvidia0 \ --device /dev/nvidiactl:/dev/nvidiactl \ --device /dev/nvidia-uvm:/dev/nvidia-uvm \ -v /usr/local/nvidia:/usr/local/nvidia \ -it --privileged nvidia/cuda
通过 --device 来指定挂载的 gpu 设备,通过 -v 来将宿主机上的 nvidia gpu 的命令行工具和相关的依赖库挂载到容器。这样,在容器中就可以看到和使用宿主机上的 gpu 设备了。
注意:这种方式对于 gpu 的可用性(哪些 gpu 是空闲的等)需要人为的判断,效率很低
nvidia-docker 详解
结构图及各组件说明
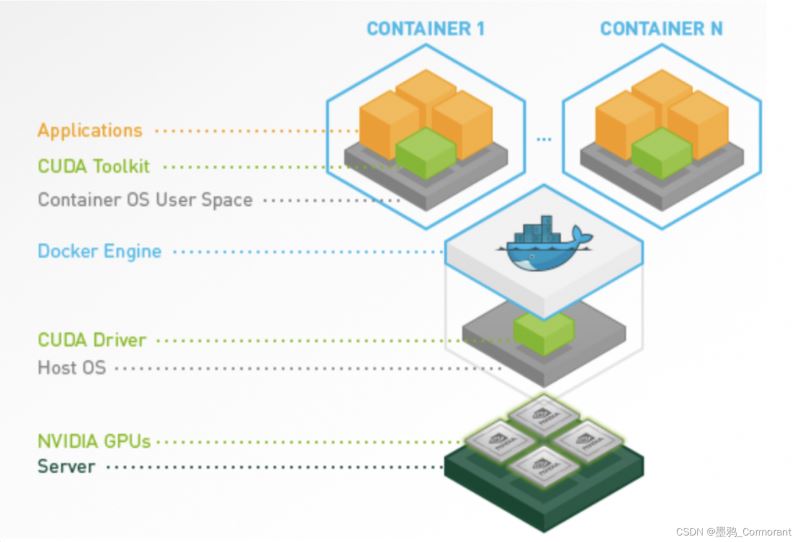
nvidia-docker 对于使用 gpu 资源的 docker 容器支持的层次关系:
nvidia-docker的原理图以及各个部分的作用解析:
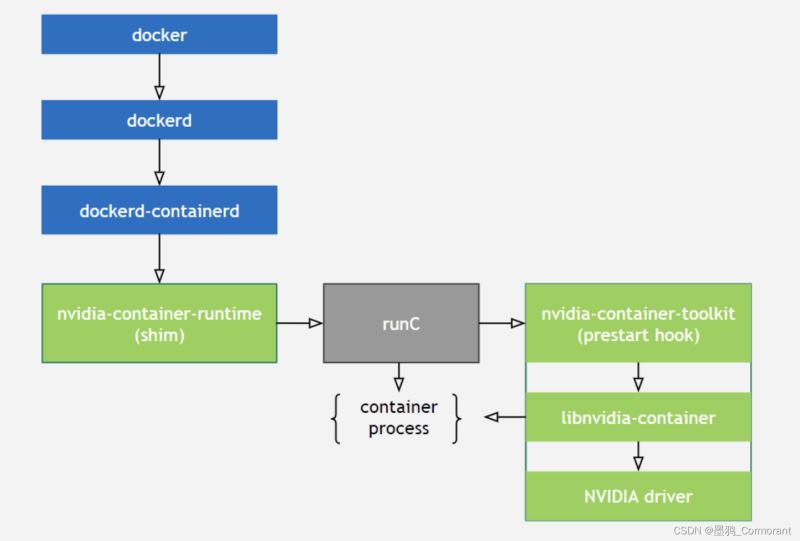
**libnvidia-container:**提供了一个库和简单的 cli 工具,以实现在容器当中支持使用 gpu 设备的目标。
nvidia-container-toolkit:
是一个实现了 runc 的 prestart hook 接口的脚本,该脚本在 runc 创建一个容器之后,启动该容器之前调用,其主要作用就是修改与容器相关联的 config.json,注入一些在容器中使用 nvidia gpu 设备所需要的一些信息(比如:需要挂载哪些 gpu 设备到容器当中)。
nvidia-container-runtime:
主要用于将容器 runc spec 作为输入,然后将 nvidia-container-toolkit 脚本作为一个 prestart hook 加入到 runc spec 中,再用修改后的 runc spec 调 runc 的 exec 接口运行容器。
所以在容器启动之前会调用 pre-start hook(nvidia-container-toolkit),这个 hook 会通过 nvidia-container-cli 文件,来调用libnvidia-container 库,最终映射挂载宿主机上的 gpu 设备、nvid 驱动的 so 文件、可执行文件到容器内部。
nvidia-container-runtime 才是真正的核心部分,它在原有的 docker 容器运行时 runc 的基础上增加一个 prestart hook,用于调用 libnvidia-container 库
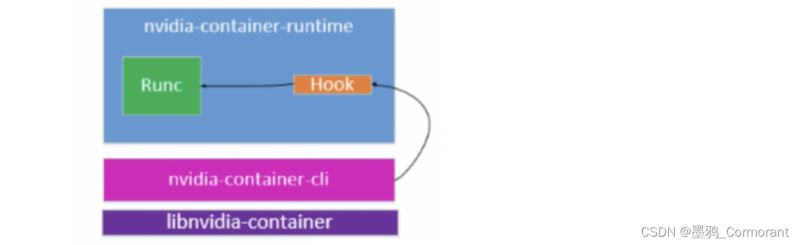
runc:
runc 是一个轻量级的工具,它是用来运行容器的,只用来做这一件事。
可以认为它就是个命令行小工具,可以不用通过 docker 引擎,直接运行容器。也是 docker 默认的容器运行方式。
事实上,runc 是标准化的产物,它根据 oci 标准来创建和运行容器。而 oci(open container initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准。
直接使用 runc 的命令行即可以完成创建一个容器,并提供了简单的交互能力。
容器创建过程
创建一个正常容器(不支持 gpu)的流程:
docker --> dockerd --> containerd–> containerd-shim -->runc --> container-process
docker 客户端将创建容器的请求发送给 dockerd,当 dockerd 收到请求任务之后将请求发送给 containerd,containerd 经过查看校验启动 containerd-shim 或者自己来启动容器进程。
创建一个支持 gpu 的容器的流程:
docker–> dockerd --> containerd --> containerd-shim–> nvidia-container-runtime --> nvidia-container-runtime-hook --> libnvidia-container --> runc – > container-process
基本流程和不支持 gpu 的容器差不多,只是把 docker 默认的运行时替换成了 nvidia 封装的 nvidia-container-runtime
这样当 nvidia-container-runtime 创建容器时,先执行 nvidia-container-runtime-hook,这个 hook 去检查容器是否需要使用gpu(通过环境变 nvidia_visible_devices 来判断)。如果需要则调用 libnvidia-container 来暴露 gpu 给容器使用。否则走默认的 runc 逻辑。
nvidia docker 整体工作架构
软硬件基础
- 硬件,服务器上安装了英伟达 gpu
- 宿主机,安装了操作系统和 cuda driver,以及 docker 引擎
- 容器,包含容器 os 用户空间,cuda toolkit,以及用户应用程序
注意:
- 宿主机上需要安装 cuda driver,容器内需要安装 cuda toolkit。容器内无需安装 cuda driver
- nvidia 提供了一些官方镜像,其中已经安装好了 cuda toolkit,但还是需要在宿主机安装 cuda driver。
api 结构
nvidia 提供了三层 api:
- cuda driver api:
gpu 设备的抽象层,通过提供一系列接口来操作 gpu 设备,性能最好,但编程难度高,一般不会使用该方式开发应用程序
- cuda runtime api:
对 cuda driver api 进行了一定的封装,调用该类 api 可简化编程过程,降低开发难度
- cuda libraries:
是对 cuda runtime api 更高一层的封装,通常是一些成熟的高效函数库,开发者也可以自己封装一些函数库便于使用
cuda 结构图如下:
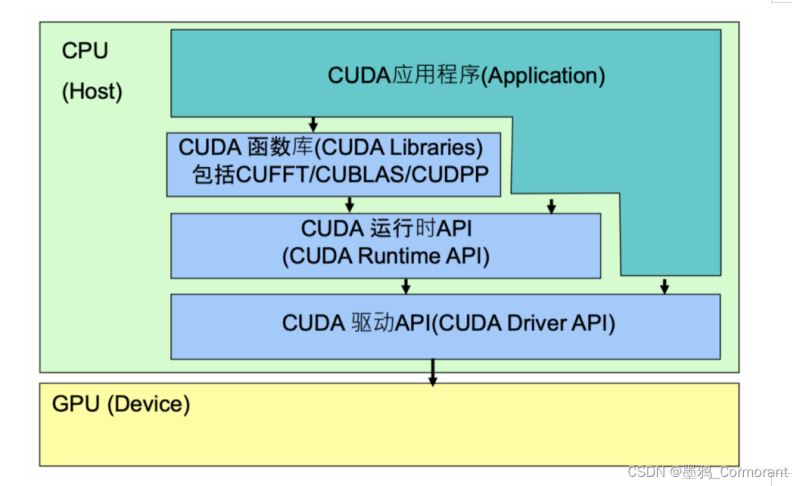
cuda 调用关系:
应用程序可调用 cuda libraries 或者 cuda runtime api 来实现功能,当调用 cuda libraries 时,cuda libraries 会调用相应的 cuda runtime api,cuda runtime api 再调用 cuda driver api,cuda driver api 再操作 gpu 设备。
cuda 的容器化
目标:让应用程序可以在容器内调用 cuda api 来操作 gpu
因此需要实现:
- 在容器内应用程序可调用 cuda runtime api 和 cuda libraries
- 在容器内能使用 cuda driver 相关库。因为 cuda runtime api 其实就是 cuda driver api 的封装,底层还是要调用到 cuda driver api
- 在容器内可操作 gpu 设备
因此容器中访问 gpu 资源过程为:
- 要在容器内操作 gpu 设备,需要将 gpu 设备挂载到容器里
- docker 可通过 --device 挂载需要操作的设备,或者直接使用特权模式(不推荐)。
- nvidia docker 是通过注入一个 prestart 的 hook 到容器中,在容器自定义命令启动前就将gpu设备挂载到容器中。
- 至于要挂载哪些gpu,可通过 nvidia_visible_devices 环境变量控制。
- 挂载 gpu 设备到容器后,还要在容器内可调用 cuda api
- cuda runtime api 和 cuda libraries 通常跟应用程序一起打包到镜像里
- cuda driver api 是在宿主机里,需要将其挂载到容器里才能被使用。
- nvidia docker 挂载 cuda driver 库文件到容器的方式和挂载 gpu 设备一样,都是在 runtime hook 里实现的。
注意:
该方案也有一些问题,即容器内的 cuda runtime 同宿主机的 cuda driver 可能存在版本不兼容的问题。
cuda libraries 和 cuda runtime api 是和应用程序一起打包到镜像中的,而 driver 库是在创建容器时从宿主机挂载到容器中的,需要保证 cuda driver 的版本不低于 cuda runtime 版本。
nvidia docker 2.0(nvidia-container-runtime)
实现机制
- nvidia-docker2.0 是一个简单的包,它主要通过修改 docker 的配置文件 /etc/docker/daemon.json,将默认的 runtime 修改为 nvidia-container-runtime,可实现将 gpu 设备,cuda driver 库挂载到容器中。
cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeargs": []
}
}
}
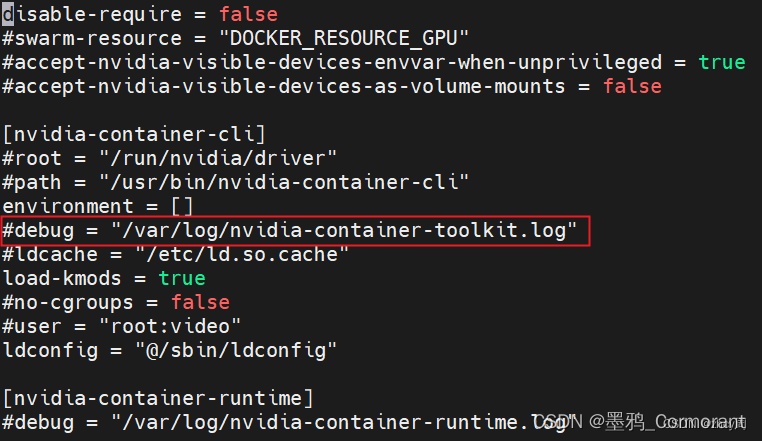
debug日志
修改 nvidia runc 的默认配置文件 /etc/nvidia-container-runtime/config.toml ,打开 hook 的 debug 日志选项,可以看到宿主机挂载 nvidia 驱动、设备到容器内部的详细过程。
以上就是docker容器访问gpu资源的使用指南的详细内容,更多关于docker访问gpu资源的资料请关注代码网其它相关文章!



发表评论