一、什么是 http 网络请求
http(hypertext transfer protocol)是互联网上应用最广泛的通信协议。简单来说,http 网络请求就是客户端(如你的 python 程序)向服务器发送消息,并等待服务器返回响应的过程。
常见的请求类型包括:
- get:获取资源(如打开网页、查询数据)
- post:提交数据(如表单提交、上传文件)
- put/patch:更新资源
- delete:删除资源
在 python 中实现 http 请求,本质上是利用现有的网络库,按照 http 协议的规范构造请求并解析响应。
二、python 中常用的 http 工具
python 生态中有多个成熟的库可以处理 http 请求,根据场景复杂度可分为两类:
2.1 简单场景:标准库与轻量级第三方库
对于基础的请求-响应操作,python 标准库内置了 urllib 模块。它无需安装额外依赖,适合处理简单的 url 访问、参数编码和响应读取。不过,它的 api 相对底层,代码写起来较为繁琐。
更推荐的做法是使用第三方库,它在标准库之上做了高度封装,提供了更人性化的接口。例如:
- 发送 get 请求只需一行代码
- 自动处理 url 编码、cookie、重定向等细节
- 响应内容可直接获取文本或二进制数据
2.2 复杂场景:功能更强大的异步库
当需要处理高并发请求、异步 i/o 或复杂的会话管理时,可以考虑支持异步编程的库。这类库基于 asyncio 实现,能够在单线程内高效调度大量网络请求,显著提升爬虫或 api 客户端的性能。
三、实现 http 请求的核心步骤
无论使用哪个库,一次完整的 http 请求通常包含以下环节:
3.1 构造请求
- 指定 url:目标接口地址
- 选择方法:get、post 等
- 设置请求头(headers):如 user-agent、content-type、认证令牌(token)等
- 准备请求体(body):主要用于 post/put,常见格式有表单数据、json 字符串、文件流等
3.2 发送请求并建立连接
库会自动处理底层的 tcp 连接、ssl/tls 加密(https)以及超时控制。你可以设置超时时间,避免程序因网络阻塞无限等待。
3.3 接收并解析响应
服务器返回的响应包含:
- 状态码:如 200(成功)、404(未找到)、500(服务器错误)
- 响应头:内容类型、编码方式、缓存策略等
- 响应体:实际返回的数据(html、json、图片等)
对于 json 格式的 api 响应,现代库通常提供一键解析为 python 字典的方法。
四、代码实现
4.1 安装uvicorn和fastapi
pip3 install uvicorn pip3 install fastapi
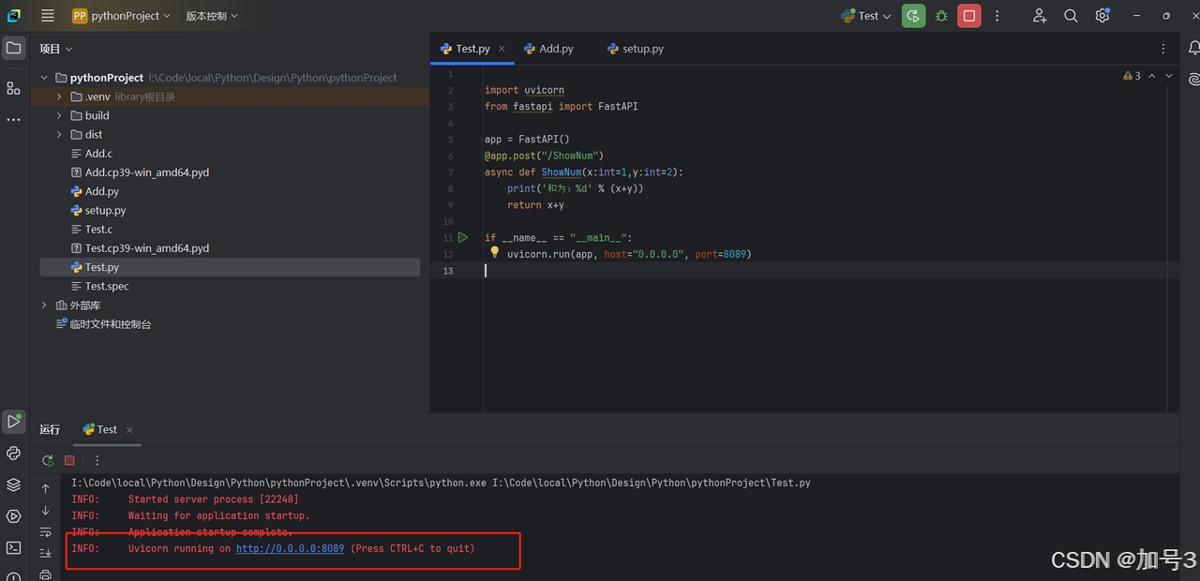
4.2 监听接口实现
import uvicorn
from fastapi import fastapi
app = fastapi()
@app.post("/shownum")
async def shownum(x:int=1,y:int=2):
print('和为:%d' % (x+y))
return x+y
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8089)
如图所示已启动http端口监听
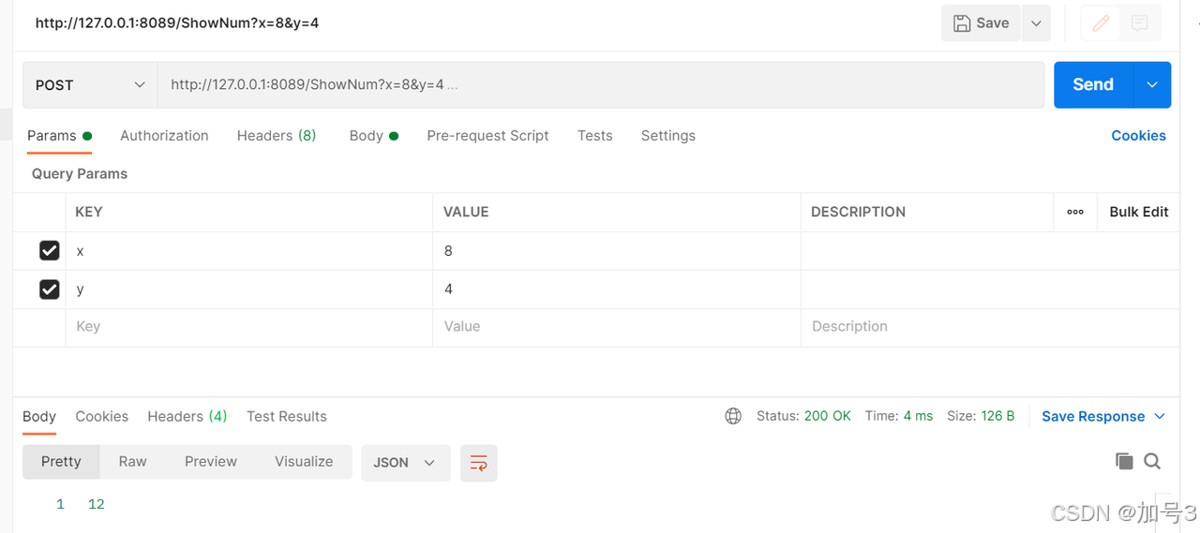
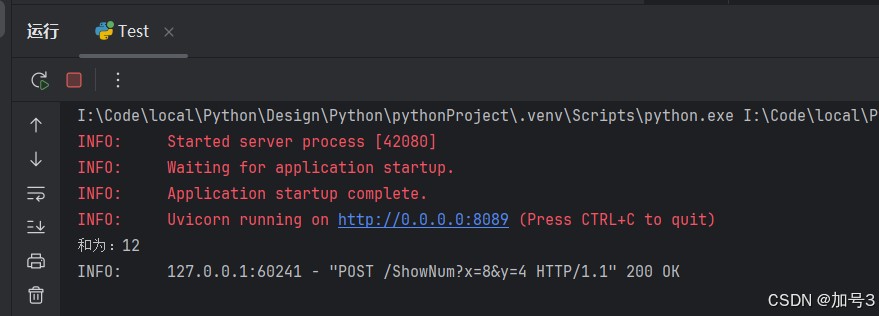
4.3 postman调用接口
五、实际应用中的关键注意事项
5.1 异常处理
网络环境充满不确定性,必须考虑:
- 连接超时:服务器无响应
- 请求异常:dns 解析失败、网络中断
- http 错误:4xx 客户端错误、5xx 服务器错误
良好的做法是用异常捕获机制包裹请求逻辑,确保程序不会因单次请求失败而崩溃。
5.2 参数编码与安全性
- url 中的查询参数需要正确编码,避免特殊字符导致请求格式错误
- 涉及密码、token 等敏感信息时,务必使用 https,并避免将密钥硬编码在代码中
5.3 会话保持(session)
某些场景(如登录后的连续操作)需要保持 cookie 或复用连接。使用"会话对象"可以自动维护跨请求的 cookie 和连接池,避免每次请求都重新建立 tcp 连接,提升效率。
5.4 代理与反爬虫策略
在数据采集等场景中,可能需要:
- 配置 http/https 代理以绕过 ip 限制
- 设置合理的请求间隔,避免对目标服务器造成压力
- 随机更换 user-agent 或添加其他请求头模拟真实浏览器
六、总结
用 python 实现 http 网络请求并不复杂。对于绝大多数日常需求(调用 rest api、抓取网页、提交数据),选择一个封装良好的第三方库即可快速上手。关键在于理解 http 协议的基本流程,并在实践中注意异常处理、安全编码和性能优化。
以上就是python实现http网络请求功能的入门指南的详细内容,更多关于python http网络请求功能的资料请关注代码网其它相关文章!






发表评论