markdown 凭借其轻量级和易读性,已经成为技术文档、博客文章及项目规范的首选格式。然而,在需要展示网页或集成系统的时候,html 才是通用的展示媒介。如何快速地将 markdown 转换为 html,是许多人都面临的需求。
本文将介绍如何基于 spire.doc for python,完成这项格式转换任务,为文档自动化提供更专业和高效的支持。
环境配置:准备工作
在开始代码实战之前,我们需要先在 python 环境中部署核心库。spire.doc for python 是一个独立的文档处理组件,它不依赖于 microsoft word 就能轻松处理各项简单或复杂的文本文档相关的任务,例如今天的教程将要讲解的转换 markdown 为 html。
系统与工具要求:
- python 版本:建议使用 python 3.8 及以上版本,以确保与最新版库的兼容性。
- 编辑器推荐:由于本篇使用 vs code 进行演示,因此推荐使用 visual studio code (vs code)。配合 python 插件,它能提供完善的代码补全和调试功能,让调用 spire.doc 接口时的开发体验更加流畅。
安装步骤: 你可以通过 pip 命令快速完成安装:
pip install spire.doc
此外,该组件还提供免费版(free spire.doc for python),适合个人开发者或小规模项目使用。
安装完成后,只需在脚本顶部引入命名空间,即可开启文档转换。
在 python 中将单个 markdown 文件转换为 html
将单个 markdown 文件转换为 html 是最基础的任务,我们就从处理单个文件入手,讲解 spire.doc for python 是通过怎样的步骤来完成转换。其实整个过程非常简单,创建文档对象,加载 markdown 文档,保存为 html 文件。
下方的 python 代码就展示了从 markdown 到 html 转换,你可以直接复制到 vs code 进行测试,但注意替换文件路径:
from spire.doc import *
# 创建 document 对象
doc = document()
# 从文件加载 markdown
doc.loadfromfile("全球旅游.md", fileformat.markdown)
# 将文档保存为 html
doc.savetofile("markdowntohtml.html", fileformat.html)
doc.close()
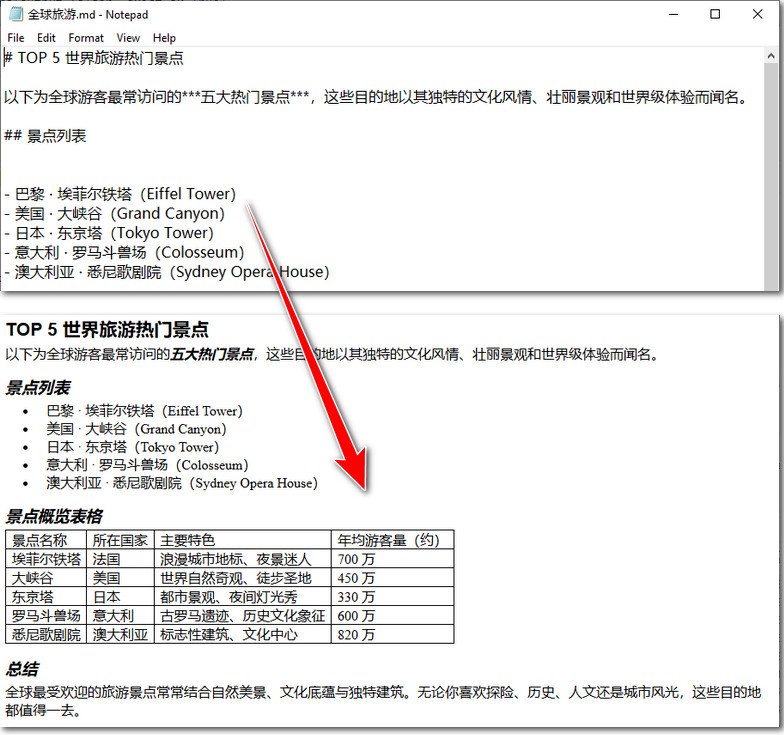
通过 python 批量转换 markdown 文档为 html
在实际工作中,除了处理单个文件,批量转换 markdown 文档也非常常见。针对存储在目录下的数十甚至上百个技术日志或项目规范,我们可以利用 python 的文件系统操作能力来实现自动化批量扫描与转换。
通过结合 os 模块,我们可以遍历指定路径下的所有 .md 文件,并为其自动生成对应的 html 输出。关键步骤与转换单个文件一致,但需要在最开始添加遍历文件夹中文件的代码片段。
下方为批量转换 markdown 文档为 html 的代码示例:
from spire.doc import *
import os
from spire.doc import *
# 设置包含 markdown 文件的源文件夹和 html 文件保存的目标文件夹
input_folder = "/input/markdown/"
output_folder = "/output/html/"
# 检查输出路径,如果不存在则自动创建,确保流程不报错
os.makedirs(output_folder, exist_ok=true)
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
# 仅处理 markdown 后缀的文件,过滤掉其他杂质
if filename.endswith(".md"):
# 为每个文件创建一个独立的 document 对象,避免内容叠加
doc = document()
# 将当前遍历到的 markdown 文件加载到对象中
doc.loadfromfile(os.path.join(input_folder, filename), fileformat.markdown)
# 动态设置输出文件路径,将后缀名从 .md 替换为 .html
output_file = os.path.join(output_folder, filename.replace(".md", ".html"))
# 执行转换并保存到目标路径
doc.savetofile(output_file, fileformat.html)
doc.close()
为什么选择 spire.doc
除了上述的转换功能,spire.doc 还可以转换其它多种格式。你可以轻松地将同样的 document 对象保存为 pdf 或 word,只需修改 fileformat 参数即可。这为技术团队构建一处编写,多处发布的文档中台提供了极大的便利。
此外,在转换过程中,你还可以通过库提供的 api 注入自定义样式表或调整文档属性。
常见问题处理与注意事项
在实际应用 spire.doc 进行文档转换时,你可能会遇到环境兼容性或特殊格式显示的问题。为了确保转换过程的顺畅以及输出文件的效果,以下几个关键点需要特别注意:
1.中文文件转换时避免乱码困扰
在处理包含中文内容的 markdown 文件时,源文件最好采用 utf-8 编码。虽然 spire.doc 具有较强的识别能力,但在读取阶段显式检查文件的编码格式,可以有效避免转换后 html 页面出现“烫烫烫”或问号乱码的情况。
2.数学公式与特殊表格
标准的 markdown 语法较为简单,而对于包含 latex 数学公式或极其复杂的嵌套表格,转换后的 html 渲染效果可能取决于浏览器对 css 的支持。建议在转换后,针对复杂的 html 结构引用一套成熟的样式表(如 bootstrap 表格样式),以确保在网页端能获得最佳的视觉体验。
3.图片显示问题
markdown 中常使用相对路径引用本地图片。转换为 html 后,如果 html 文件与图片的相对位置发生了改变,会导致网页中出现红叉占位符。在进行批量转换时,建议统一管理图片资源库,或者在转换后通过脚本批量修正 html 中的 <img> 标签路径。
4.必要的动态库支持
虽然该库不依赖 microsoft word,但在 linux 或 docker 容器环境下运行时,系统可能缺少必要的图形渲染库(如 libgdiplus)。如果转换过程中出现字体解析或图像处理报错,请确保运行环境中已安装相关的底层图形依赖。
方法补充
python 生态中有多种成熟的库可以自动化实现 markdown 到 html 的转换,选择哪个方案,取决于你的具体需求,是对速度的追求,还是对扩展性的需要。
下表对比了几个主流方案的核心特点,方便你快速了解和选择:
| 方案 | 核心特点 | 复杂度 | 代码量/学习曲线 | 扩展灵活性 | 性能 | 适用场景 |
|---|---|---|---|---|---|---|
| markdown | 官方参考实现,社区最活跃 | 简单 | 低 | 极高(丰富的扩展机制) | 中等 | 博客系统、cms、需要稳定支持的通用场景 |
| mistune | 性能极快,纯 python 实现 | 中等 | 中低 | 高(插件和渲染器系统) | 最高 | 高并发 web 应用、实时预览工具、对渲染速度有极致要求的场景 |
| markdown-it-py | 符合 commonmark 标准,现代设计 | 中等 | 中 | 高(插件系统,与 js 版 markdown-it 有诸多兼容插件) | 高 | 需要严格遵循标准、或希望从 js 生态迁移的项目 |
| pypandoc | 功能最全的格式转换 | 中等 | 低(api简单) | 低(需了解 pandoc 命令行选项) | 中等 | 需要处理多格式互转(如 md/docx/pdf)的复杂业务 |
| spire.doc | 企业级格式保真度,api 简单 | 简单 | 低 | 低 | 良好 | 企业应用、对转换质量和格式完美度有极高要求的批量处理场景 |
| markdown2 | 轻量、快速、功能全面 | 简单 | 低 | 高(支持多种额外语法) | 高 | 个人项目、快速转换、偏好轻量级开源方案 |
提示:上表总结了几种常用方案。若你的目标不仅是简单的文本转换,还需处理复杂的文档元素(如表格、代码高亮等),建议你进一步下滑,在“代码实战:转换您的 markdown”章节,根据所选库查看支持高级功能的代码示例。
1. 使用markdown库
您可以将 markdown 库的高级用法封装起来,构建一个功能强大的文档转换器。
代码示例:
import markdown
from markdown.extensions.toc import tocextension
import sys
def convert(md_file: str, html_file: str):
"""从文件读取 markdown,转换为带有目录的 html"""
with open(md_file, 'r', encoding='utf-8') as f:
text = f.read()
# 添加扩展:toc(目录)、extra(表格)、codehilite(高亮)
extensions = [
'extra', 'toc', 'codehilite',
tocextension(permalink="¶", title="在此处引用")
]
html = markdown.markdown(text, extensions=extensions)
# 生成完整的html页面
full_html = f"""
<!doctype html>
<html>
<head><meta charset="utf-8"><title>{md_file}</title>
<link href="https://cdn.bootcdn.net/ajax/libs/github-markdown-css/5.8.1/github-markdown.min.css" rel="external nofollow" rel="stylesheet">
<style>.markdown-body {{ margin: 0 auto; max-width: 800px; padding: 20px; }}</style>
</head>
<body class="markdown-body">\n{html}\n</body>
</html>"""
with open(html_file, 'w', encoding='utf-8') as f:
f.write(full_html)
if __name__ == "__main__":
if len(sys.argv) != 3:
print("usage: python convert.py input.md output.html")
sys.exit(1)
convert(sys.argv[1], sys.argv[2])以上代码演示了如何读取一个 markdown 文件,利用 extra 扩展集(包含表格、围栏代码块等功能)和 toc(目录)扩展进行转换,并最终生成一个带有 github 风格样式的完整 html 页面。
2. 使用 mistune 库
mistune 本身追求极致速度,当引入 pygments 作为代码高亮后端时,能兼顾性能与呈现效果。
代码示例:
import mistune
from pygments import highlight
from pygments.lexers import get_lexer_by_name
from pygments.formatters import htmlformatter
class highlightrenderer(mistune.htmlrenderer):
"""支持代码高亮的定制渲染器"""
def block_code(self, code, lang=none):
if lang:
lexer = get_lexer_by_name(lang, stripall=true)
formatter = htmlformatter()
return highlight(code, lexer, formatter)
return '<pre><code>' + mistune.escape(code) + '</code></pre>'
def mistune_advanced_convert(markdown_text: str) -> str:
"""使用高级配置和自定义渲染器进行转换"""
renderer = highlightrenderer()
markdown = mistune.markdown(renderer=renderer, plugins=['table', 'footnotes'])
return markdown(markdown_text)此示例通过自定义 highlightrenderer,实现了代码块的高亮功能。
3. 使用 markdown-it-py 库
如果您已经熟悉或希望迁移 javascript 生态的 markdown-it 库,markdown-it-py 能提供一致的前端开发体验。
安装:pip install markdown-it-py[plugins]
代码示例:
from markdown_it import markdownit
# 使用默认 presets,启用表格、代码块、删除线等
md = markdownit('commonmark') # 或 'default', 'zero' 等预设
md.enable(['table', 'strikethrough'])
markdown_text = """
| 语法 | 说明 |
|------|------|
| 表格 | 支持 `table` 扩展 |
"""
html = md.render(markdown_text)markdownit 的预设 (commonmark, default 等) 能快速适应不同的 markdown 风格。
4. 使用 pypandoc 库
对于跨多种文档格式的复杂自动化任务,pypandoc 是最强大的利器。
安装:pip install pypandoc。
准备:它需要 pandoc 作为后端,可通过以下方式安装:
- 命令行:
brew install pandoc(macos) |sudo apt install pandoc(ubuntu) | 官网下载 (windows)。 - python代码自动下载:
pypandoc.download_pandoc()。
代码示例:
import pypandoc
# 单文件转换
output = pypandoc.convert_file('input.md', 'html', outputfile='output.html')
# 批量目录转换
from pathlib import path
for md_file in path('docs/').glob('*.md'):
pypandoc.convert_file(str(md_file), 'html', outputfile=md_file.with_suffix('.html'))该代码展示了如何使用 pypandoc 高效地处理单个文件或批量文档转换。
进阶技巧:自动化与安全
为了提高效率和应对自动化场景,您可以参考以下实践:
- 批量转换:使用
glob或pathlib遍历文档目录,对每个文件执行转换操作。pypandoc非常适合这类任务。 - 性能优化:对于高频率、低延迟的场景,请优先考虑
mistune或markdown-it-py。对于企业级批量处理,可考虑使用spire.doc等商业库。 - 样式与高亮:为生成的 html 编写 css,并结合
codehilite(python-markdown)、pygments(mistune)等工具实现代码高亮。 - 网络安全:当解析来自用户输入的 markdown 时,请务必进行清理 (sanitization) 以防止跨站脚本攻击(xss)。
markdown-it-py可以通过配置限制允许的 html 标签。
总结
本文主要讲解了如何使用 spire.doc for python 高效将 markdown 转换为 html 文件,不管是单个文件还是多文件的批量转换,你都可以通过该组件轻松完成!主页还有将 markdown 转换为 word 或 pdf 文档的教程,欢迎浏览。






发表评论