前言
数据缺失:指的是数据中的某个或某些特征不完整,即由于各种原因导致数据记录中某些列的值空缺。
不同的数据存储或环境对于缺失值的表现结果不同,例如,数据库中为 null,python 返回 none,pandas 或 numpy 则是 nan。
缺失值也不同于空字符串,空字符串是有实体的,为字符串类型;而缺失值是没有实体的,没有数据类型。
pandas 中常见的数据缺失值的检测、统计与处理方法,如下。
一、缺失值的检测与统计
定量:了解数据中那些字段有缺失,缺失比例如何。
pandas 提供识别缺失值的方法 isnull、识别非缺失值的方法 notnull ,返回值为布尔值(false或true)。以下面读取数据的结果为示例:
import pandas as pd
df =pd.read_excel('sass.xlsx') # 读取数据
print(df)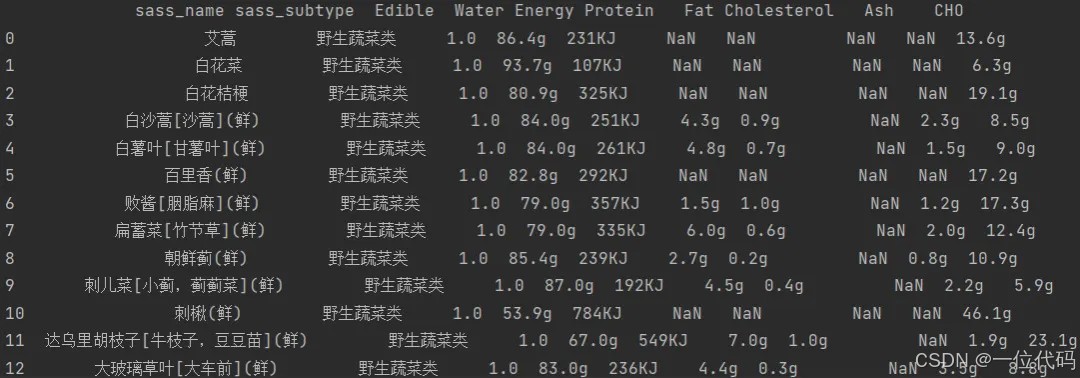
查看每列是否有缺失值
df.isnull.any():true 表示有缺失,false 表示没有缺失。
print('每列是否存在缺失值:\n', df.isnull().any()) # true表示有缺失,false表示无缺失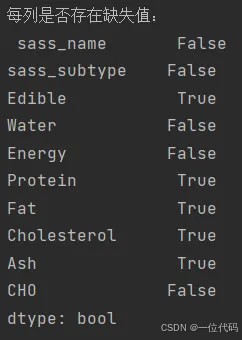
显示数据缺失情况、位置
df.isnull():true 表示有缺失,false 表示没有缺失。
print('数据缺失值查看:\n', df.isnull()) # true表示缺失,false表示未缺失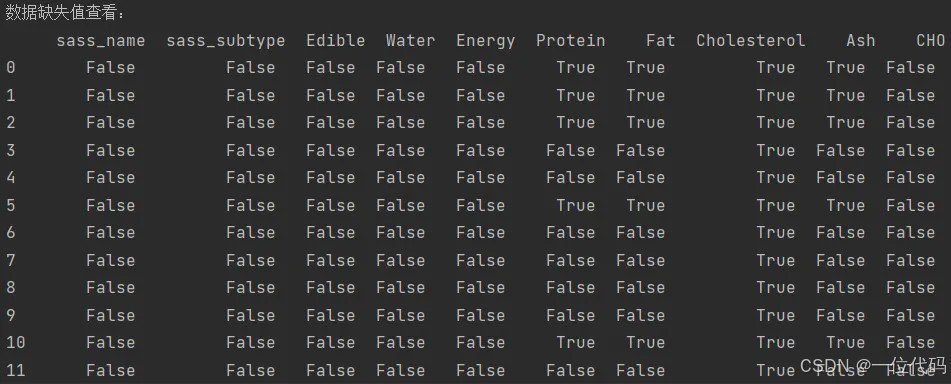
统计每列缺失值个数
sum() 函数结合 isnull、notnull,可查看数据中缺失值的分布以及数据中一共有多少个缺失值。
print('每列数据缺失的个数:\n', df.isnull().sum())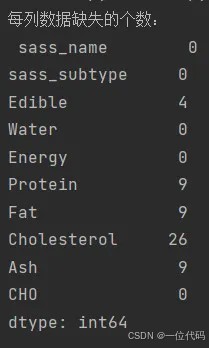
注:notnull 用法一样,只是代表意思相反,表示未缺失值情况。
二、缺失值的处理
直接删除缺失值(删除法)
这种方法简单明了,直接删除带有缺失值的行记录(整行删除)或者列字段(整列删除),但是这种方法会消减数据特征,在很多情况下是不科学的,需要根据具体情况来考虑是否删除。
pandas 提供了 dropna 方法来删除缺失值,语法:
dataframe.dropna(self,axis=0,how='any',thresh=none,subset=none,inplace=false)
| 参数 | 释义 |
| axis | 接收0或1,表示轴向,0表示行,1表示列。默认为0 |
| how | 接收特定string,表示删除形式。取值为“any”,表示只要有缺失值就执行删除操作,取值为“all”,表示当且仅当全部为缺失值时才执行删除操作。默认为“any” |
| subset | 接收array,表示根据去重的行/列条件。默认为none,所有行/列 |
| inplace | 接收布尔值,代表操作是否对原数据生效,默认为false |
以原始数据(df1)为例:
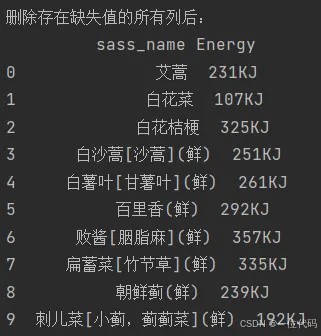
实例1:删除存在缺失值(nan)的所有列
df2 =df1.dropna(axis=1)
print('删除存在缺失值的所有列后:\n', df2)
实例2:删除特定字段存在缺失值(nan)的行。
如:删除'protein'或 'cho'字段存在缺失值(nan)的行。
df3 = df1.dropna(subset=['protein', 'cho'])
print('删除特定字段为空的行:\n', df3)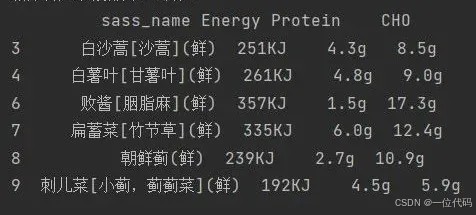
替换补齐缺失值
相对于直接删除法而言,补齐是更加常用的缺失值处理方法。
如果缺失值所在特征(列)为数值型,通常利用均值、中位数、众数等描述其集中趋势的统计量来替换补齐缺失值;
如果缺失值所在特征(列)为类别型,选择使用类别众数来替换补齐。
当然根据实际情况,可选择随机法、特殊值法、模型法等来替换补齐。
pandas 提供了缺失值替换的方法 fillna,语法:
dataframe.fillna(value=none,method=none,axis=1,inplace=false,limit=none)
| 参数 | 释义 |
| value | 接收dict、dataframe等类型数据,表示用来替换缺失值的值。无默认值 |
| method | 接收特定string:(1)取值为“backfill”或“bfill”,表示使用下一个非缺失值来填补缺失值。(2)取值为“pad”或“ffill”,表示使用上一个非缺失值来填补缺失值。默认为none |
| axis | 接收0或1,表示轴向。默认为1 |
| inplace | 接收布尔值,代表操作是否对原数据生效,默认为false |
| limit | 接收int,表示填补缺失值个数上限,超过则不进行填补。默认为none |
以上面数据(df1)为例,将所有缺失值(nan)填充为0:
df4 = df1.fillna(value=0)
print('将所有缺失值填充为0:\n', df4)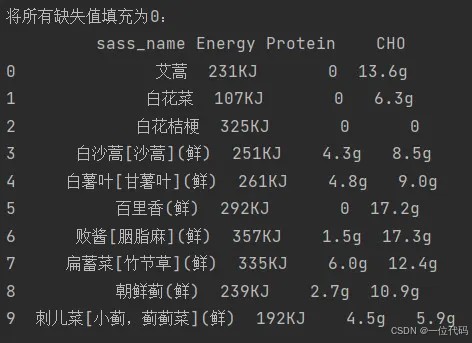
注:根据实际需要,为缺失数据填充合理的值,方便后面数据的分析与建模,这里全部填充为0,只是作为一个方法举例。
以上就是pandas中数据缺失值的检测,统计与处理教学的详细内容,更多关于pandas数据缺失值处理的资料请关注代码网其它相关文章!






发表评论