在日常的办公中,我们经常会遇到需要批量处理excel文件的情况。比如:给几百个员工的姓名前面加上部门名称,把一列包含完整地址的数据拆分成省、市、区多列,或者对某些产品的价格统一上调50元。如果只有一两个文件,手动改改还行;但如果是几十个文件,或者每个月都要重复这些操作,那就太折磨人了!
今天,我们就用 python + pyqt5 + pandas 打造一款图形化的“excel批量列处理工具”,不仅支持一键拖拽文件,还能动态选择列名、添加多条处理规则,帮你彻底告别重复劳动!
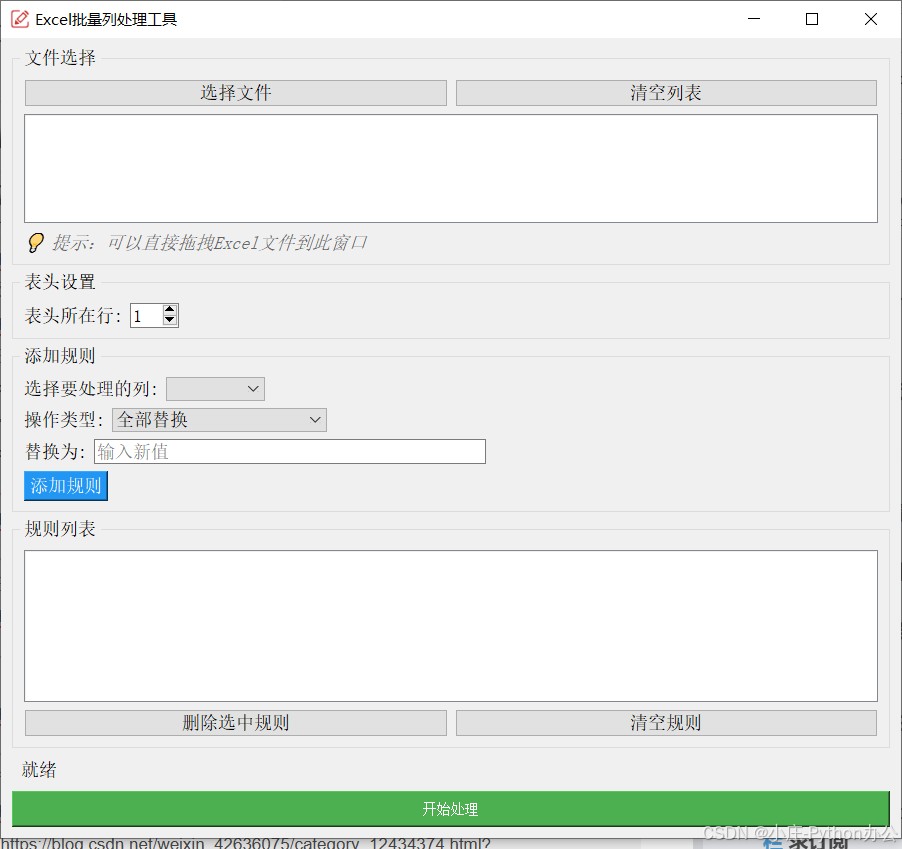
工具亮点展示
这款工具具备以下强大的功能:
- 傻瓜式文件导入:支持点击选择或直接将多个 excel 文件拖拽到软件窗口。
- 智能识别列名:导入文件后,程序会自动读取 excel 的表头,并生成下拉列表供你选择,再也不用担心手动输入列名打错字了。
- 强大的六大操作:
- 全部替换:将整列数据替换为统一的新值。
- 头部/尾部添加:批量给文本添加前缀或后缀。
- 字符分割(多列/保留单列):支持按指定字符将一列拆分成多列,或者只提取你需要的那部分。
- 数值统一加减:一键对数值列进行加减运算。
- 多规则流水线:可以在一次任务中添加多条规则(比如先给a列加前缀,再把b列拆分),程序会按顺序一次性处理完毕。
- 安全可靠:处理后的文件会自动另存为
原文件名_已处理.xlsx,绝不覆盖你的原始数据!
核心代码拆解
这款工具的界面是使用 pyqt5 编写的,而底层的表格处理则是大名鼎鼎的数据分析库 pandas。我们来看看几个关键的技术点:
1. 动态读取 excel 列名
为了让用户能直接从下拉菜单中选择列名,我们需要在用户拖入文件后,迅速读取 excel 的表头。这里我们用到了 pandas 的一个小技巧:设置 nrows=0,这样 pandas 只会读取表头,不会加载海量的数据,速度极快!
def update_columns(self):
"""更新列名下拉列表"""
self.column_combo.clear()
if not self.files:
return
try:
# 读取第一个文件的表头作为参考,nrows=0 大幅提升读取速度
file_path = self.files[0]
header_row = self.header_spin.value()
df = pd.read_excel(file_path, header=header_row - 1, nrows=0)
columns = df.columns.tolist()
self.column_combo.additems([str(col) for col in columns])
except exception as e:
self.status_label.settext(f"读取列名失败: {str(e)}")
2. 使用 qthread 避免界面卡顿
处理大体积的 excel 文件或者同时处理数十个文件时,如果在主线程里执行,软件界面就会“假死”(未响应)。所以我们继承 qthread 编写了一个 processthread,把耗时的处理工作放到后台线程。
class processthread(qthread):
progress = pyqtsignal(str)
finished = pyqtsignal(bool, str)
def __init__(self, files, header_row, rules):
super().__init__()
self.files = files
self.header_row = header_row
self.rules = rules
def run(self):
try:
success_count = 0
for file_path in self.files:
self.progress.emit(f"正在处理: {os.path.basename(file_path)}")
if self.process_file(file_path):
success_count += 1
self.finished.emit(true, f"处理完成!成功处理 {success_count}/{len(self.files)} 个文件")
except exception as e:
self.finished.emit(false, f"处理出错: {str(e)}")
3. pandas 数据处理核心逻辑
核心的数据处理部分全靠 pandas。我们遍历用户设定的规则列表 self.rules,针对不同的操作类型,调用相应的 pandas api。比如字符串拼接、str.split 拆分列,以及 pd.to_numeric 进行数值计算:
def process_file(self, file_path):
df = pd.read_excel(file_path, header=self.header_row - 1)
for rule in self.rules:
column_name = rule.get('column')
operation = rule.get('operation')
params = rule.get('params', {})
if operation == "头部添加":
prefix = params.get('prefix', '')
df[column_name] = prefix + df[column_name].astype(str)
elif operation == "以字符分割成多列":
delimiter = params.get('delimiter', ',')
# expand=true 会直接返回一个 dataframe
split_data = df[column_name].astype(str).str.split(delimiter, expand=true)
df = df.drop(columns=[column_name])
col_index = df.columns.tolist().index(column_name) if column_name in df.columns else len(df.columns)
for i, col in enumerate(split_data.columns):
df.insert(col_index + i, f"{column_name}_分割{i+1}", split_data[col])
elif operation == "数值统一加减":
add_value = params.get('add_value', 0)
df[column_name] = pd.to_numeric(df[column_name], errors='coerce') + add_value
# 安全保存文件
base_name, ext = os.path.splitext(file_path)
output_path = f"{base_name}_已处理{ext}"
df.to_excel(output_path, index=false)
return true
打包为 exe 分享给同事
写好代码后,为了让没有安装 python 环境的同事也能使用,我们可以使用 pyinstaller 将它打包成一个独立的 exe 可执行文件。
只需在命令行中运行以下命令:
pyinstaller --noconfirm --onefile --windowed --icon "修改.ico" --add-data "修改.png;." --name "excel批量列处理工具" excel_editor.py
--onefile:打包成单一文件--windowed:运行时不显示黑乎乎的控制台黑框--icon和--add-data:给软件加上好看的图标
打包完成后,在 dist 目录下就会生成一个 excel批量列处理工具.exe,直接双击就能愉快地使用了!
结语
借助 python 和 pandas 强大的数据处理能力,再搭配 pyqt5 的图形化界面,我们轻松就把繁琐的 excel 处理工作变成了一键式的傻瓜工具。不仅自己用着爽,发给身边的同事,绝对能让你收获满满的赞誉!
到此这篇关于python+pyqt5打造一个excel批量列处理工具的文章就介绍到这了,更多相关python excel批量列处理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论