从零开始学习使用 python 调用 stable diffusion api 生成图像,涵盖本地部署、api 调用、controlnet、图生图等进阶技巧。

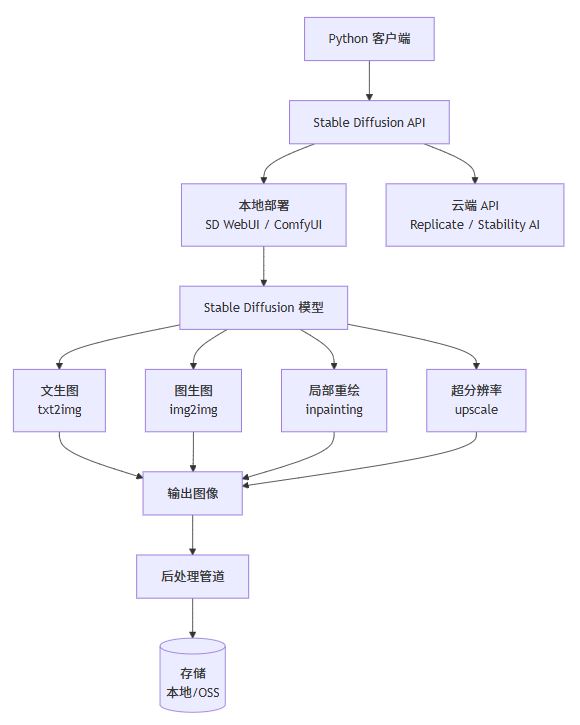
1. 技术架构
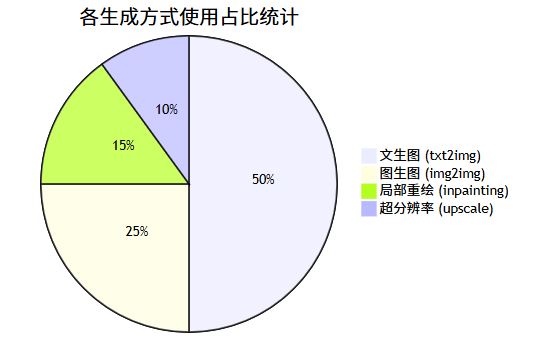
2. 图像生成方式对比
3. 环境准备
3.1 本地部署 stable diffusion webui
# 克隆 stable diffusion webui git clone https://github.com/automatic1111/stable-diffusion-webui.git cd stable-diffusion-webui # 启动(开启 api 模式) ./webui.sh --api --listen # windows 用户 webui.bat --api --listen
3.2 安装依赖
pip install requests pillow io base64
4. 核心代码实现
4.1 sd api 客户端封装
# sd_client.py
import requests
import base64
import io
import json
import time
from pathlib import path
from pil import image
from dataclasses import dataclass, field
from typing import optional
@dataclass
class generationconfig:
"""图像生成配置"""
prompt: str = ""
negative_prompt: str = "low quality, blurry, deformed"
width: int = 512
height: int = 512
steps: int = 30
cfg_scale: float = 7.0
sampler_name: str = "dpm++ 2m karras"
seed: int = -1 # -1 表示随机
batch_size: int = 1
n_iter: int = 1 # 迭代次数
model: optional[str] = none
class stablediffusionclient:
"""stable diffusion api 客户端"""
def __init__(self, base_url: str = "http://127.0.0.1:7860"):
self.base_url = base_url
self.api_url = f"{base_url}/sdapi/v1"
def _save_base64_image(self, b64_str: str, output_path: str) -> str:
"""将 base64 图片保存到文件"""
img_data = base64.b64decode(b64_str)
img = image.open(io.bytesio(img_data))
img.save(output_path)
return output_path
# ---- 文生图 ----
def txt2img(self, config: generationconfig,
output_dir: str = "./output") -> list[str]:
"""文生图:从文本描述生成图像"""
payload = {
"prompt": config.prompt,
"negative_prompt": config.negative_prompt,
"width": config.width,
"height": config.height,
"steps": config.steps,
"cfg_scale": config.cfg_scale,
"sampler_name": config.sampler_name,
"seed": config.seed,
"batch_size": config.batch_size,
"n_iter": config.n_iter,
}
if config.model:
self._switch_model(config.model)
response = requests.post(f"{self.api_url}/txt2img", json=payload)
response.raise_for_status()
data = response.json()
path(output_dir).mkdir(exist_ok=true)
saved_paths = []
for i, img_b64 in enumerate(data["images"]):
path = f"{output_dir}/txt2img_{int(time.time())}_{i}.png"
self._save_base64_image(img_b64, path)
saved_paths.append(path)
print(f"已保存: {path}")
return saved_paths
# ---- 图生图 ----
def img2img(self, init_image_path: str, prompt: str,
denoising_strength: float = 0.75,
config: generationconfig = none,
output_dir: str = "./output") -> list[str]:
"""图生图:基于参考图 + 提示词生成新图"""
config = config or generationconfig()
# 读取初始图片并转 base64
with open(init_image_path, "rb") as f:
init_images = [base64.b64encode(f.read()).decode()]
payload = {
"init_images": init_images,
"prompt": prompt,
"negative_prompt": config.negative_prompt,
"width": config.width,
"height": config.height,
"steps": config.steps,
"cfg_scale": config.cfg_scale,
"sampler_name": config.sampler_name,
"denoising_strength": denoising_strength,
"seed": config.seed,
}
response = requests.post(f"{self.api_url}/img2img", json=payload)
response.raise_for_status()
data = response.json()
path(output_dir).mkdir(exist_ok=true)
saved_paths = []
for i, img_b64 in enumerate(data["images"]):
path = f"{output_dir}/img2img_{int(time.time())}_{i}.png"
self._save_base64_image(img_b64, path)
saved_paths.append(path)
print(f"已保存: {path}")
return saved_paths
# ---- 局部重绘 ----
def inpaint(self, init_image_path: str, mask_image_path: str,
prompt: str, denoising_strength: float = 0.85,
output_dir: str = "./output") -> list[str]:
"""局部重绘:只修改 mask 区域"""
with open(init_image_path, "rb") as f:
init_images = [base64.b64encode(f.read()).decode()]
with open(mask_image_path, "rb") as f:
mask = base64.b64encode(f.read()).decode()
payload = {
"init_images": init_images,
"mask": mask,
"prompt": prompt,
"negative_prompt": "low quality, blurry",
"denoising_strength": denoising_strength,
"inpainting_fill": 1, # 0=fill, 1=original, 2=latent noise
"inpaint_full_res": true,
"steps": 30,
"cfg_scale": 7.0,
"sampler_name": "dpm++ 2m karras",
"width": 512,
"height": 512,
}
response = requests.post(f"{self.api_url}/img2img", json=payload)
response.raise_for_status()
data = response.json()
path(output_dir).mkdir(exist_ok=true)
saved_paths = []
for i, img_b64 in enumerate(data["images"]):
path = f"{output_dir}/inpaint_{int(time.time())}_{i}.png"
self._save_base64_image(img_b64, path)
saved_paths.append(path)
return saved_paths
# ---- 超分辨率 ----
def upscale(self, image_path: str, scale: int = 2,
output_dir: str = "./output") -> str:
"""使用 esrgan 进行超分辨率放大"""
with open(image_path, "rb") as f:
img_b64 = base64.b64encode(f.read()).decode()
payload = {
"image": img_b64,
"upscaler_1": "r-esrgan 4x+",
"upscaling_resize": scale,
}
response = requests.post(f"{self.api_url}/extra-single-image",
json=payload)
response.raise_for_status()
data = response.json()
path(output_dir).mkdir(exist_ok=true)
path = f"{output_dir}/upscaled_{int(time.time())}.png"
self._save_base64_image(data["image"], path)
print(f"超分辨率完成: {path}")
return path
# ---- 模型管理 ----
def _switch_model(self, model_name: str):
"""切换模型"""
response = requests.post(
f"{self.api_url}/options",
json={"sd_model_checkpoint": model_name},
)
response.raise_for_status()
time.sleep(3) # 等待模型加载
def list_models(self) -> list[str]:
"""列出可用模型"""
response = requests.get(f"{self.api_url}/sd-models")
return [m["title"] for m in response.json()]
def list_samplers(self) -> list[str]:
"""列出可用采样器"""
response = requests.get(f"{self.api_url}/samplers")
return [s["name"] for s in response.json()]
4.2 批量生成示例
# batch_generate.py
from sd_client import stablediffusionclient, generationconfig
def batch_generate_portraits():
"""批量生成人物肖像"""
sd = stablediffusionclient()
# 查看可用模型和采样器
print("可用模型:", sd.list_models()[:5])
print("可用采样器:", sd.list_samplers())
# 风格列表
styles = [
"cyberpunk neon city",
"watercolor painting",
"oil painting renaissance",
"anime style",
"photorealistic 8k",
]
base_prompt = (
"portrait of a young woman, detailed face, beautiful eyes, "
"dramatic lighting, masterpiece, best quality"
)
for style in styles:
config = generationconfig(
prompt=f"{base_prompt}, {style}",
negative_prompt="lowres, bad anatomy, bad hands, text, error",
width=512,
height=768,
steps=30,
cfg_scale=7.5,
)
paths = sd.txt2img(config, output_dir=f"./output/{style.replace(' ', '_')}")
print(f"风格 [{style}] -> {paths}")
if __name__ == "__main__":
batch_generate_portraits()
4.3 调用 stability ai 云端 api
# stability_cloud.py
import requests
import base64
from pathlib import path
from pil import image
from io import bytesio
class stabilityaiclient:
"""stability ai 官方云端 api"""
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "https://api.stability.ai/v2beta"
def generate(self, prompt: str, aspect_ratio: str = "1:1",
style: str = "photographic",
output_path: str = "output.png") -> str:
"""调用 stable diffusion 3 生成图像"""
response = requests.post(
f"{self.base_url}/stable-image/generate/sd3",
headers={
"authorization": f"bearer {self.api_key}",
"accept": "image/*",
},
files={"none": ""},
data={
"prompt": prompt,
"aspect_ratio": aspect_ratio,
"style_preset": style,
"output_format": "png",
},
)
if response.status_code != 200:
raise exception(f"api 错误: {response.status_code} - {response.text}")
with open(output_path, "wb") as f:
f.write(response.content)
print(f"已生成: {output_path}")
return output_path
# 使用示例
if __name__ == "__main__":
client = stabilityaiclient(api_key="sk-your-api-key")
client.generate(
prompt="a majestic dragon flying over a neon-lit cyberpunk city at night, "
"highly detailed, cinematic lighting, 8k",
aspect_ratio="16:9",
style="cinematic",
output_path="dragon_city.png",
)
4.4 图像后处理管道
# postprocess.py
from pil import image, imageenhance, imagefilter
from pathlib import path
class imagepostprocessor:
"""图像后处理:调整色彩、锐化、添加水印"""
@staticmethod
def enhance(image_path: str, brightness: float = 1.1,
contrast: float = 1.15, sharpness: float = 1.3,
output_path: str = none) -> str:
"""综合增强"""
img = image.open(image_path)
img = imageenhance.brightness(img).enhance(brightness)
img = imageenhance.contrast(img).enhance(contrast)
img = imageenhance.sharpness(img).enhance(sharpness)
output_path = output_path or image_path.replace(".", "_enhanced.")
img.save(output_path, quality=95)
return output_path
@staticmethod
def add_watermark(image_path: str, text: str = "ai generated",
output_path: str = none) -> str:
"""添加水印"""
from pil import imagedraw, imagefont
img = image.open(image_path).convert("rgba")
overlay = image.new("rgba", img.size, (0, 0, 0, 0))
draw = imagedraw.draw(overlay)
# 半透明白色文字
draw.text(
(img.width - 200, img.height - 40),
text,
fill=(255, 255, 255, 128),
)
img = image.alpha_composite(img, overlay).convert("rgb")
output_path = output_path or image_path.replace(".", "_wm.")
img.save(output_path, quality=95)
return output_path
@staticmethod
def create_grid(image_paths: list[str], cols: int = 3,
output_path: str = "grid.png") -> str:
"""将多张图片拼成网格"""
images = [image.open(p) for p in image_paths]
w, h = images[0].size
rows = (len(images) + cols - 1) // cols
grid = image.new("rgb", (w * cols, h * rows), "white")
for i, img in enumerate(images):
row, col = divmod(i, cols)
grid.paste(img, (col * w, row * h))
grid.save(output_path, quality=95)
print(f"网格图已保存: {output_path}")
return output_path
5. prompt 工程技巧
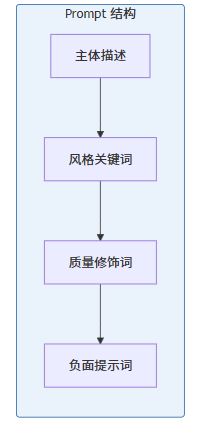
高质量 prompt 模板
prompt_templates = {
"人物肖像": (
"{subject}, {style}, detailed face, expressive eyes, "
"dramatic lighting, masterpiece, best quality, ultra detailed"
),
"风景": (
"{scene}, {mood}, volumetric lighting, god rays, "
"landscape photography, 8k uhd, cinematic composition"
),
"产品设计": (
"{product}, minimalist design, studio lighting, "
"white background, product photography, professional, 4k"
),
"动漫": (
"{character}, anime style, vibrant colors, "
"detailed illustration, cel shading, masterpiece"
),
}
negative_prompts = {
"通用": "lowres, bad anatomy, bad hands, text, error, missing fingers, "
"extra digit, cropped, worst quality, low quality, blurry",
"写实": "illustration, painting, drawing, art, sketch, anime, cartoon, "
"cg, render, 3d, watermark, text, font, signature",
"动漫": "photo, realistic, 3d, western, ugly, duplicate, morbid, "
"deformed, bad anatomy, blurry",
}
6. 关键参数影响
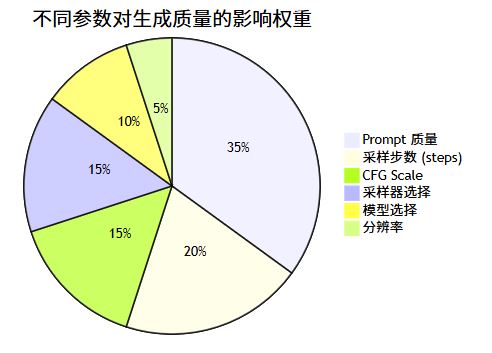
| 参数 | 推荐值 | 说明 |
|---|---|---|
steps | 25-35 | 步数越多细节越好,但边际递减且更慢 |
cfg_scale | 7-12 | 越高越遵循 prompt,过高会过饱和 |
sampler | dpm++ 2m karras | 兼顾速度与质量 |
denoising_strength | 0.5-0.8 | 图生图降噪强度,越高变化越大 |
seed | -1 | 随机种子,固定可复现 |
7. 完整使用流程
# complete_demo.py
from sd_client import stablediffusionclient, generationconfig
from stability_cloud import stabilityaiclient
from postprocess import imagepostprocessor
def main():
# ===== 方式一:本地 sd webui =====
sd = stablediffusionclient("http://127.0.0.1:7860")
# 文生图
config = generationconfig(
prompt="a serene japanese garden with cherry blossoms, "
"koi pond, stone bridge, golden hour, cinematic, 8k",
negative_prompt="lowres, blurry, text, watermark",
width=768,
height=512,
steps=30,
cfg_scale=7.5,
)
paths = sd.txt2img(config)
print(f"生成完成: {paths}")
# 图生图
if paths:
new_paths = sd.img2img(
init_image_path=paths[0],
prompt="same scene but in autumn, orange and red leaves, snow",
denoising_strength=0.6,
)
print(f"图生图完成: {new_paths}")
# 超分辨率
if paths:
upscaled = sd.upscale(paths[0], scale=2)
print(f"超分辨率完成: {upscaled}")
# 后处理
pp = imagepostprocessor()
if paths:
enhanced = pp.enhance(paths[0])
watermarked = pp.add_watermark(enhanced, text="ai art")
print(f"后处理完成: {watermarked}")
# ===== 方式二:云端 api =====
# cloud = stabilityaiclient("sk-xxx")
# cloud.generate("a futuristic cityscape at sunset", "16:9", "cinematic")
if __name__ == "__main__":
main()
8. 总结
本文覆盖了 stable diffusion 图像生成的完整链路:
- 本地部署 sd webui 并开启 api 模式
- 封装 python 客户端 支持文生图、图生图、局部重绘、超分辨率
- 云端 api 作为无 gpu 环境的替代方案
- prompt 工程 模板化的提示词编写技巧
- 后处理管道 增强色彩、添加水印、拼图网格
生成速度参考:rtx 4090 生成 512x512 约 3-5 秒,512x768 约 5-8 秒。云端 api 约 10-20 秒。
以上就是python调用stable diffusion api实现ai图像生成的完整教程的详细内容,更多关于python调用stable diffusion api图像生成的资料请关注代码网其它相关文章!





发表评论