▼尾部的散热格栅

▼这风扇拆掉后能看到主板布局,左边是 nvidia connectx-7 智能网卡,主要作用就是前面提到的集群扩容

▼主机核心就是这块 nvidia gb10 grace blackwell 超级芯片,这标志着桌面端正式进入了“超级芯片”时代,优势方面包括:
异构计算核心: gb10 完美集成了 blackwell gpu 与基于 arm 架构的 grace cpu。其中 cpu 部分包含 20 个高性能核心(由 10 个 cortex-x925 与 10 个 cortex-a725 组成),确保了在处理复杂逻辑与数据流时的极致能效比。
- 恐怖的 ai 性能: blackwell gpu 配备 6144 个 cuda 核心,并采用第五代 tensor core。在 fp4 精度计算下,单台设备可提供高达 **1 pflops(每秒 1000 万亿次)**的 ai 运算性能。这使得单机即可支持最高 2,000 亿参数的 ai 模型。
- nvlink-c2c 互连技术: 不同于传统的 pcie 总线,该机采用 nvlink-c2c 技术实现 cpu 与 gpu 的高效协同,带宽高达 900gb/s(约为 pcie 5.0 的 5 倍)。这种超高带宽确保了在微调大规模模型时,数据传输不再成为瓶颈。
- 集群扩容潜力: 针对更高需求,ai top atom 支持通过集群串接。两台设备串联后,可执行高达 4,050 亿参数的超级模型。结合 nvidia 完整的 ai 软件栈,它为本地 ai 计算提供了前所未有的适应性。
▼右侧为处理器区域,技嘉 ai top atom 采用了 128gb lpddr5x 内存与 4tb nvme 存储的顶配方案。其内存带宽达到了惊人的 273gb/s,这种极致的配比正是为了应对本地化 200b 大模型的严苛需求,让复杂的 ai 推理与微调任务在本地运行变得游刃有余。

▼存储部分,该机在主板背面配备了 4tb 三星 pm9e1 ssd(m.2 2242 规格)。依托三星 5nm “presto” 主控与 v8 tlc v-nand 的核心组合,存储性能直达 pcie 5.0 顶峰,顶部则是天线的固定区域。

系统体验及算力测试
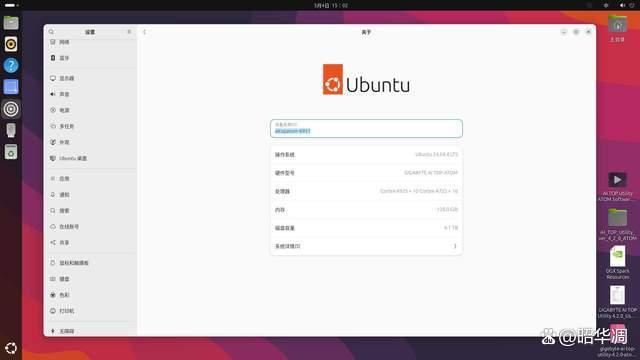
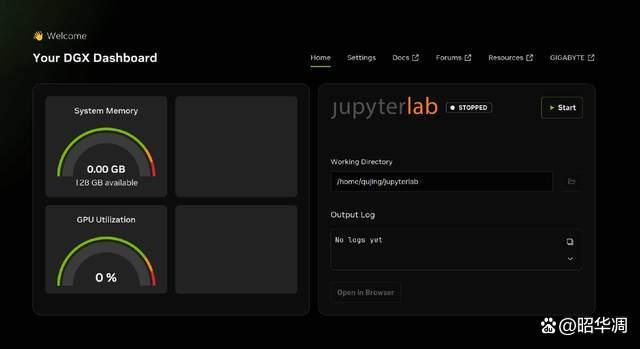
▼系统方面,技嘉 ai top atom 自带经过优化的 ubuntu 定制环境,在保障 ai 开发兼容性的同时,内置了全套生产力工具。
不过从系统也能看到,该机面向的用户群体还是有很强针对性的。

▼内置软件从用于网页浏览与查阅文献的 firefox,到支持工具自由扩展的应用商店,再到满足文档管理需求的内置办公软件,ai top atom 真正做到了从“开发实验”到“通用办公”的平滑切换。
▼应用市场
▼技嘉 ai top atom 在 ai 方面的优势还是很大的,主机内嵌了 nvidia ai 软件栈,提供各式工具、开发框架与函数库,以加速 ai 项目开发流程。


发表评论